Dense Retrieval vs Sparse Retrieval: Understanding Modern AI Search Systems
Modern Artificial Intelligence systems increasingly depend on retrieval technologies to improve search quality, contextual understanding, and grounded response generation. Enterprise AI assistants, Retrieval-Augmented Generation (RAG) systems, semantic search platforms, and AI copilots all rely heavily on retrieval infrastructure to access relevant information efficiently.
Two retrieval methods dominate modern AI retrieval architecture:
Dense Retrieval
and
Sparse Retrieval
Although both approaches help AI systems find relevant information, they operate very differently.
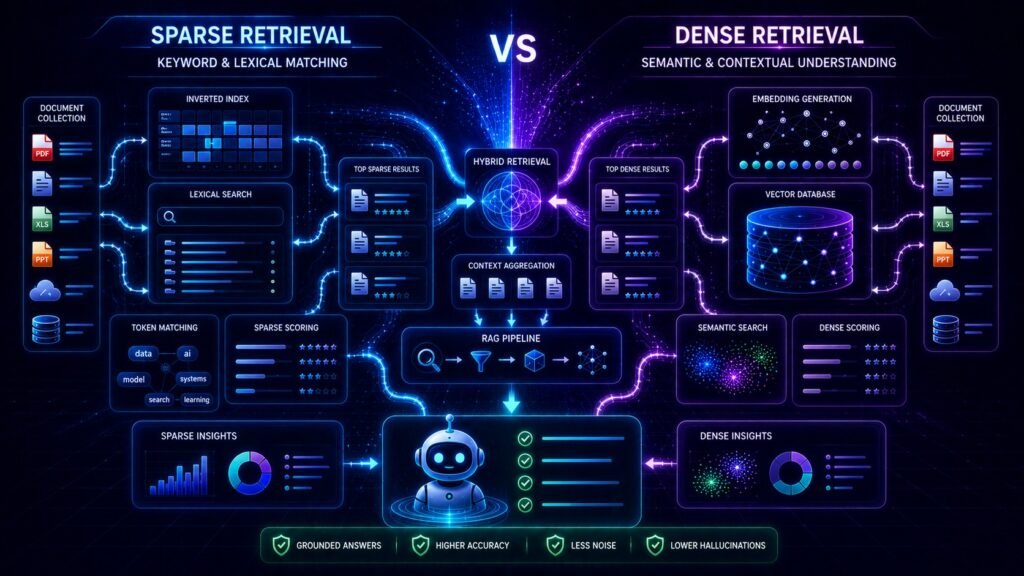
Sparse retrieval focuses primarily on exact keyword matching and lexical search techniques, while dense retrieval focuses on semantic understanding and contextual similarity using embeddings.
Understanding the difference between dense retrieval vs sparse retrieval is important because modern RAG systems often combine both approaches together to improve retrieval quality.
Today, these retrieval architectures power many AI applications including:
- enterprise search systems
- AI chatbots
- semantic retrieval platforms
- recommendation systems
- customer support copilots
- legal AI assistants
- document intelligence systems
In this guide, you will learn how dense retrieval and sparse retrieval work, their advantages and limitations, and why modern RAG systems increasingly combine both methods using hybrid retrieval architectures.
In Simple Terms
What Is Sparse Retrieval?
Sparse retrieval is a traditional search method that retrieves information using exact keywords and lexical matching.
It focuses on:
- word frequency
- keyword overlap
- token matching
- inverted indexes
Search engines like traditional enterprise search systems often use sparse retrieval techniques.
Examples include:
- BM25
- TF-IDF
- keyword ranking systems
Sparse retrieval works well when exact terminology matters.
What Is Dense Retrieval?
Dense retrieval uses embeddings to retrieve information based on semantic meaning and contextual similarity.
Instead of relying on exact keywords, dense retrieval converts text into vector embeddings and searches based on semantic relationships.
Dense retrieval powers modern semantic search systems and Retrieval-Augmented Generation architectures.
It helps AI systems understand meaning instead of exact wording.
The Core Difference Between Dense and Sparse Retrieval
The easiest way to understand the difference is this:
| Retrieval Type | Main Focus |
| Sparse Retrieval | Exact keyword matching |
| Dense Retrieval | Semantic meaning and contextual similarity |
Sparse retrieval searches for matching words.
Dense retrieval searches for matching meaning.
This distinction is critical for modern AI retrieval systems.
Why Sparse Retrieval Became Important
Sparse retrieval systems powered search technology for decades.
They became popular because they are:
- efficient
- scalable
- interpretable
- fast
- highly precise for exact matches
Traditional search engines rely heavily on sparse retrieval.
Sparse Retrieval Works Well for Exact Matching
Sparse retrieval performs especially well when exact wording matters.
Examples include:
- product names
- legal references
- SKU numbers
- technical identifiers
- regulations
- compliance terms
For example:
Searching for:
“RTX 5090 GPU”
requires exact lexical matching.
Sparse retrieval handles this efficiently.
Sparse Retrieval Uses Lexical Signals
Sparse retrieval systems often analyze:
- keyword frequency
- inverse document frequency
- token overlap
- query-document similarity
These systems rank documents according to lexical relevance.
Why Dense Retrieval Became Important
Modern AI systems require more than exact keyword matching.
Users increasingly search using natural language instead of carefully engineered keywords.
Dense retrieval solves this problem.
Dense Retrieval Understands Meaning
Dense retrieval helps AI systems retrieve semantically relevant information even when wording differs significantly.
For example:
A user may ask:
“How do employee reimbursements work?”
But the document may contain:
“travel expense compensation policy”
Dense retrieval can understand the semantic relationship between these phrases.
Sparse retrieval may struggle in this scenario.
Dense Retrieval Powers Semantic Search
Dense retrieval became foundational for:
- semantic search
- AI assistants
- enterprise copilots
- RAG systems
- conversational AI
because it enables contextual understanding.
How Sparse Retrieval Works
Understanding sparse retrieval becomes easier when broken into stages.
Step 1: Documents Are Indexed
The retrieval system processes documents and extracts keywords or tokens.
Step 2: Inverted Indexes Are Built
Sparse retrieval systems build inverted indexes that map keywords to documents.
This enables fast keyword lookup.
Step 3: User Queries Are Tokenized
The user query is split into searchable terms.
Example:
“refund policy process”
becomes searchable tokens.
Step 4: Keyword Matching Happens
The retrieval engine searches for documents containing matching keywords.
Documents are ranked based on lexical relevance.
Step 5: Results Are Returned
The system returns documents containing strong keyword overlap.
This completes sparse retrieval.
How Dense Retrieval Works
Dense retrieval uses a very different architecture.
Step 1: Documents Are Chunked
Large documents are divided into smaller semantic chunks.
Step 2: Embeddings Are Generated
The chunks are converted into embeddings.
What Are Embeddings?
Embeddings are numerical vector representations of meaning.
They capture semantic relationships between concepts.
Step 3: Embeddings Are Stored in Vector Databases
The embeddings are stored inside vector databases such as:
Step 4: User Queries Become Embeddings
The user query is converted into embeddings using the same embedding model.
Step 5: Semantic Similarity Search Happens
The vector database retrieves semantically similar chunks based on vector proximity.
This enables contextual retrieval.
Step 6: Results Are Returned
The system returns semantically relevant information even when wording differs.
This completes dense retrieval.
Sparse Retrieval vs Dense Retrieval Comparison
| Feature | Sparse Retrieval | Dense Retrieval |
| Main retrieval method | Keyword matching | Semantic similarity |
| Uses embeddings | No | Yes |
| Uses vector databases | No | Yes |
| Handles synonyms well | Weak | Strong |
| Exact terminology precision | Strong | Moderate |
| Semantic understanding | Weak | Strong |
| Conversational search | Limited | Strong |
| Enterprise AI integration | Moderate | Strong |
Advantages of Sparse Retrieval
Sparse retrieval still remains extremely valuable.
Strong Exact Matching
Sparse retrieval performs very well for exact identifiers and terminology.
Efficient Infrastructure
Traditional keyword indexes are highly optimized and scalable.
Fast Query Processing
Sparse retrieval systems can process large-scale search workloads efficiently.
Transparent Ranking
Lexical ranking methods are easier to interpret and debug.
Mature Ecosystem
Sparse retrieval technologies have decades of optimization behind them.
Limitations of Sparse Retrieval
Sparse retrieval also has major weaknesses.
Weak Semantic Understanding
Sparse retrieval struggles with synonyms and contextual similarity.
Keyword Dependency
Users often need carefully engineered search terms.
Poor Conversational Search
Natural language questions may not retrieve optimal results.
Limited Contextual Understanding
Sparse retrieval focuses primarily on lexical overlap rather than meaning.
Advantages of Dense Retrieval
Dense retrieval powers many modern AI systems because it solves semantic retrieval problems.
Strong Semantic Understanding
Dense retrieval understands contextual relationships between concepts.
Better Conversational Search
Users can ask natural language questions.
Improved Enterprise Retrieval
Dense retrieval handles inconsistent enterprise terminology more effectively.
Better RAG Integration
Dense retrieval integrates naturally with embeddings and vector databases.
Improved Contextual Retrieval
Dense retrieval retrieves semantically relevant information even with different wording.
Limitations of Dense Retrieval
Dense retrieval also introduces challenges.
Higher Infrastructure Complexity
Dense retrieval requires:
- embeddings
- vector databases
- semantic indexing systems
Higher Computational Costs
Embedding generation and vector search require more computational resources.
Weak Exact Matching
Dense retrieval sometimes struggles with precise identifiers.
Retrieval Noise
Semantic retrieval may occasionally retrieve loosely related content.
Why Hybrid Retrieval Became Important
Modern RAG systems increasingly combine dense and sparse retrieval together.
This approach is called:
Hybrid Retrieval
Hybrid retrieval combines:
- semantic understanding
- exact keyword matching
into one retrieval system.
This dramatically improves retrieval quality.
Hybrid Retrieval Improves Enterprise Search
Enterprise systems often require:
- exact identifiers
- contextual understanding
- semantic retrieval
- structured filtering
Hybrid retrieval handles all these requirements more effectively.
Example of Hybrid Retrieval
A user searches for:
“latest reimbursement workflow for Europe finance team”
Sparse retrieval helps match:
- Europe
- finance
- workflow
Dense retrieval helps understand:
- reimbursements
- expense approval
- compensation processes
Together, retrieval quality improves significantly.
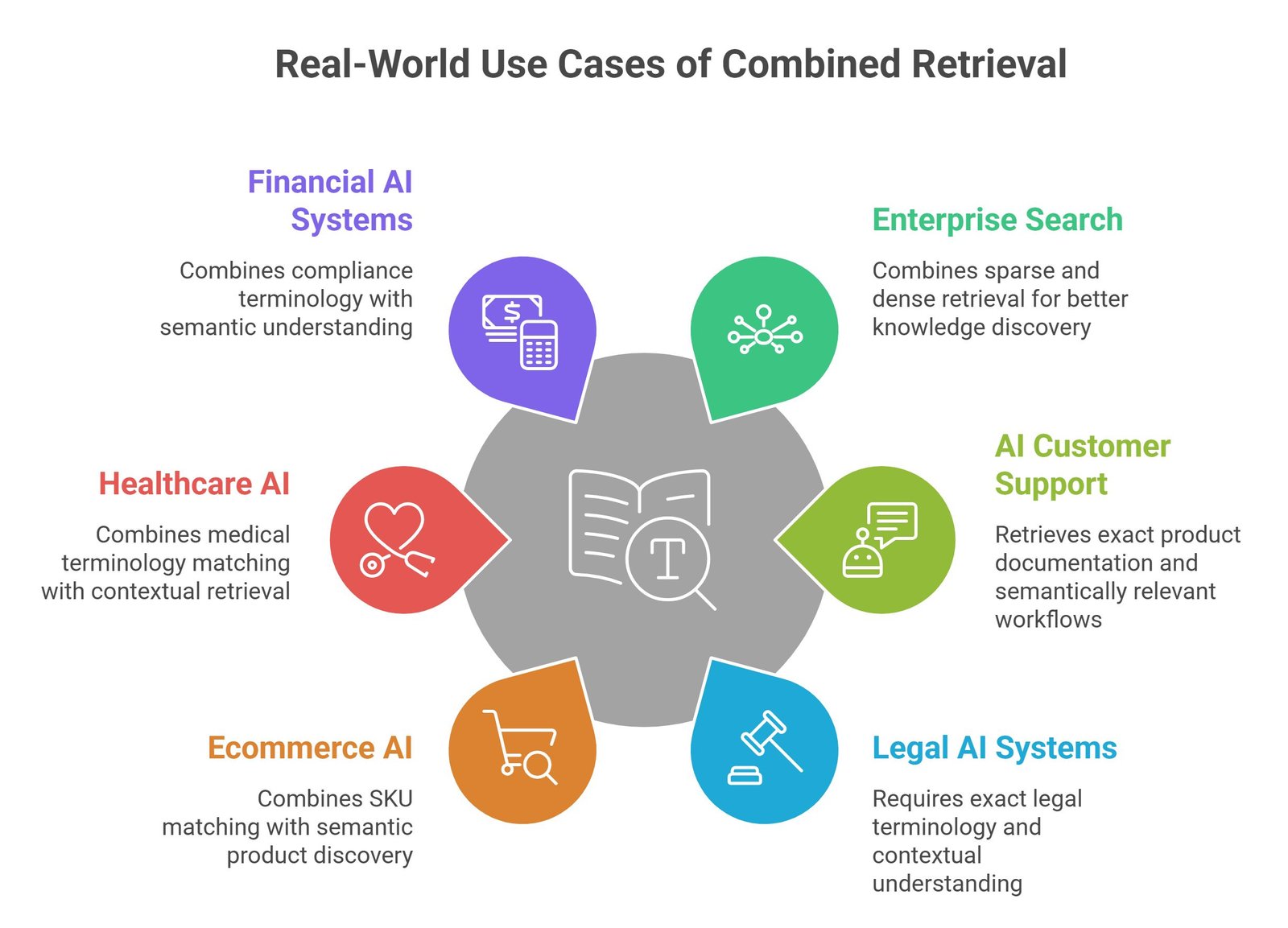
Real-World Use Cases: Dense Retrieval vs Sparse Retrieval
Enterprise Search Systems
Organizations combine sparse and dense retrieval for better knowledge discovery.
AI Customer Support
Support assistants retrieve exact product documentation plus semantically relevant workflows.
Legal AI Systems
Legal systems require exact legal terminology and contextual understanding together.
Ecommerce AI
Shopping assistants combine SKU matching with semantic product discovery.
Healthcare AI
Healthcare systems combine medical terminology matching with contextual retrieval.
Financial AI Systems
Finance assistants combine compliance terminology with semantic understanding.
Dense Retrieval vs Sparse Retrieval in RAG
Most modern RAG systems rely heavily on dense retrieval because semantic understanding is critical for conversational AI.
However, sparse retrieval still remains valuable for:
- exact enterprise terminology
- identifiers
- compliance references
- technical matching
This is why hybrid retrieval architectures increasingly dominate enterprise RAG systems.
Future of Retrieval Systems
Retrieval systems are evolving rapidly.
Major trends include:
- hybrid retrieval architectures
- multimodal retrieval systems
- graph-enhanced retrieval
- agentic retrieval systems
- personalized retrieval
- autonomous search orchestration
Future enterprise AI systems will likely combine:
- dense retrieval
- sparse retrieval
- reranking
- metadata filtering
- semantic orchestration
into unified retrieval ecosystems.
Suggested Read:
- Hybrid Search in RAG
- Semantic Search vs RAG
- Embeddings for RAG
- Vector Database for RAG
- Reranking in RAG
- Metadata Filtering in RAG
FAQ: Dense Retrieval vs Sparse Retrieval
What is dense retrieval?
Dense retrieval uses embeddings to retrieve information based on semantic similarity.
What is sparse retrieval?
Sparse retrieval uses keyword matching and lexical search techniques.
Which is better: dense or sparse retrieval?
They solve different problems. Dense retrieval handles semantic understanding, while sparse retrieval handles exact terminology matching.
Does RAG use dense retrieval?
Yes. Most RAG systems rely heavily on dense semantic retrieval.
Why do enterprises use hybrid retrieval?
Hybrid retrieval combines semantic understanding with exact keyword precision.
Final Takeaway
Understanding dense retrieval vs sparse retrieval is important because retrieval quality directly affects AI accuracy, enterprise search performance, and grounded response generation.
Sparse retrieval provides strong lexical precision, while dense retrieval provides semantic understanding and contextual intelligence.
Together, these retrieval methods form the foundation of modern hybrid retrieval systems used across enterprise AI, semantic search, and Retrieval-Augmented Generation architectures.