Hybrid Search in RAG: How AI Combines Semantic and Keyword Retrieval
Retrieval-Augmented Generation (RAG) systems have transformed modern Artificial Intelligence applications by enabling Large Language Models (LLMs) to retrieve external knowledge before generating responses. This retrieval layer dramatically improves factual grounding, reduces hallucinations, and enables enterprise AI systems to work with real-time information.
However, retrieval quality remains one of the most important challenges in production RAG systems.
If the wrong documents are retrieved:
- AI accuracy decreases
- hallucinations increase
- irrelevant context enters prompts
- enterprise trust drops
This is exactly why hybrid search became one of the most important optimization strategies in modern RAG architectures.
Traditional keyword search works well for exact matching, while semantic vector search works well for contextual understanding. But both approaches have limitations when used independently.
Hybrid search combines both retrieval methods into one intelligent retrieval system.
Today, hybrid retrieval powers many advanced AI systems including:
- enterprise search platforms
- AI copilots
- document intelligence systems
- customer support assistants
- ecommerce AI systems
- legal AI applications
- enterprise knowledge assistants
In this guide, you will learn how hybrid search in RAG works, why it improves retrieval quality, and why enterprises increasingly rely on hybrid retrieval systems for production AI applications.
In Simple Terms
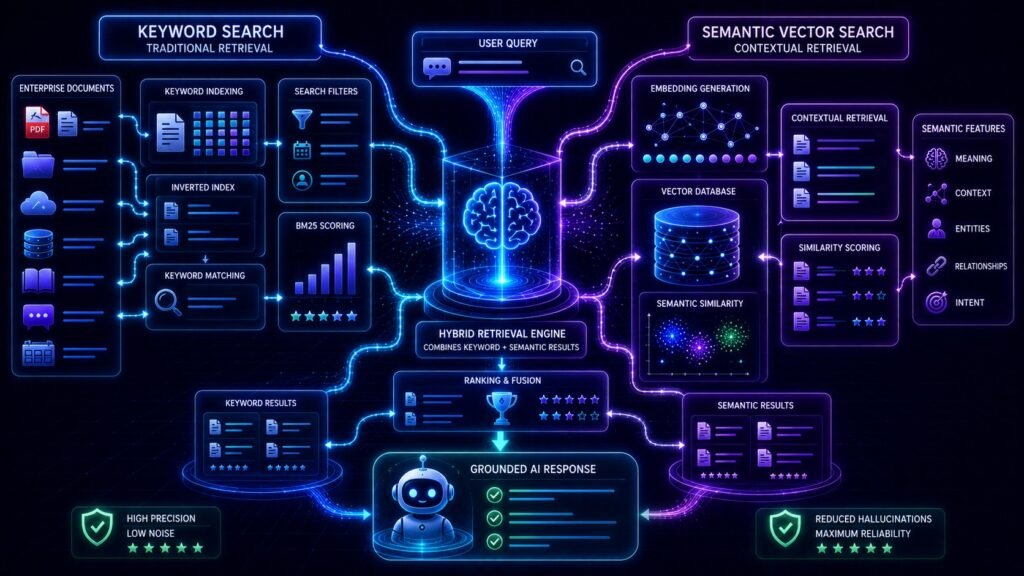
What Is Hybrid Search in RAG?
Hybrid search is a retrieval technique that combines:
- keyword-based search
- semantic vector search
inside the same RAG system.
Instead of relying only on exact keyword matching or only on embeddings, the system uses both approaches together.
This allows the AI system to retrieve information that is:
- contextually relevant
- semantically meaningful
- keyword accurate
- enterprise precise
Think of hybrid search as combining the strengths of traditional search engines and semantic AI retrieval systems into one architecture.
Why Hybrid Search Became Important in RAG
Modern enterprise retrieval systems require more than simple keyword matching.
At the same time, semantic retrieval alone is not always sufficient.
Hybrid search solves several important retrieval limitations simultaneously.
Keyword Search Alone Has Major Weaknesses
Traditional keyword search systems rely heavily on exact word matching.
This creates several problems.
For example:
A user may ask:
“How do travel reimbursements work?”
But the document may contain:
“employee expense compensation policy”
Traditional keyword search may fail because the wording differs significantly.
This limits retrieval quality.
Semantic Search Also Has Limitations
Semantic retrieval uses embeddings and vector databases to retrieve information based on meaning.
While this improves contextual understanding, semantic search sometimes retrieves:
- loosely related information
- overly broad matches
- contextually similar but irrelevant content
For example:
A semantic retriever may return documents discussing:
- refunds
- reimbursements
- compensation
- cancellations
even when the user only needs refund procedures.
This creates retrieval noise.
Enterprises Need Precision and Context Together
Enterprise AI systems require:
- semantic understanding
- exact terminology matching
- precise retrieval
- contextual relevance
- structured filtering
Hybrid search combines all these capabilities into one retrieval workflow.
This dramatically improves production AI reliability.
Easy Analogy
Imagine two librarians.
Librarian A
Only searches books using exact keywords.
Librarian B
Only searches books using conceptual similarity.
Now imagine a third librarian who combines both approaches intelligently.
That third librarian behaves like a hybrid retrieval system.
This is why hybrid search became foundational for enterprise-grade RAG systems.
How Hybrid Search Works in RAG Systems
Understanding hybrid retrieval becomes easier when broken into stages.
Step 1: Documents Are Collected
The RAG system gathers external knowledge sources such as:
- PDFs
- cloud documents
- websites
- enterprise databases
- support manuals
- research papers
- operational files
These become the searchable knowledge base.
Step 2: Documents Are Chunked
Large documents are divided into smaller searchable sections called chunks.
Chunking improves retrieval precision.
If chunks are too large:
- retrieval becomes noisy
- irrelevant context increases
If chunks are too small:
- important context may disappear
Chunk optimization is critical for hybrid retrieval systems.
Step 3: Embeddings Are Generated
The chunks are converted into embeddings using embedding models.
Embeddings represent semantic meaning numerically.
This enables semantic vector retrieval.
Step 4: Keyword Indexes Are Created
In parallel, keyword indexes are also created.
These indexes support:
- exact keyword matching
- lexical search
- structured retrieval
- traditional ranking methods
This creates the keyword retrieval layer.
Step 5: User Queries Enter the System
A user submits a question.
Example:
“What is the customer refund process?”
The query now enters both retrieval systems simultaneously.
Step 6: Semantic Retrieval Happens
The semantic retrieval layer converts the query into embeddings.
The vector database retrieves semantically similar document chunks.
This helps retrieve contextually related information.
Step 7: Keyword Retrieval Happens
At the same time, the keyword search engine retrieves documents using exact keyword matching.
This improves precision for:
- technical terms
- product names
- regulations
- identifiers
- exact enterprise terminology
Step 8: Results Are Combined
The semantic and keyword retrieval results are merged together.
This stage is called hybrid ranking or retrieval fusion.
The system now combines:
- contextual relevance
- exact matching precision
into one ranked retrieval list.
This dramatically improves retrieval quality.
Step 9: Re-Ranking Optimizes Results
Many advanced systems use re-ranking models to sort retrieved results more intelligently.
Re-ranking models improve:
- relevance
- contextual precision
- answer quality
This is especially important for enterprise AI systems.
Step 10: Retrieved Information Is Sent to the LLM
The top-ranked retrieved chunks are inserted into the prompt sent to the language model.
The AI now receives:
- user query
- semantically relevant context
- exact keyword matches
- enterprise information
This dramatically improves grounding and response quality.
Why Hybrid Search Improves RAG Systems
Hybrid retrieval solves several major AI retrieval problems simultaneously.
Better Retrieval Accuracy
Combining semantic and keyword retrieval improves overall retrieval precision significantly.
The system retrieves:
- conceptually relevant information
- exact terminology matches
at the same time.
Reduced Hallucinations
Better retrieval improves factual grounding.
This helps reduce hallucinations and unsupported responses.
Better Enterprise Search Performance
Enterprise documents often contain:
- abbreviations
- technical language
- inconsistent phrasing
- identifiers
- structured terminology
Hybrid search handles these complexities better than standalone retrieval methods.
Stronger Semantic Understanding
Semantic retrieval helps retrieve relevant context even when wording differs.
This improves natural language search capabilities.
Better User Experience
Users can ask conversational questions while still benefiting from precise enterprise retrieval.
This dramatically improves usability.
Hybrid Search vs Semantic Search vs Keyword Search
| Feature | Keyword Search | Semantic Search | Hybrid Search |
| Exact keyword matching | Strong | Weak | Strong |
| Semantic understanding | Weak | Strong | Strong |
| Contextual retrieval | Weak | Strong | Strong |
| Enterprise terminology support | Strong | Moderate | Strong |
| Natural language search | Limited | Strong | Strong |
| Retrieval precision | Moderate | Moderate | Strong |
Common Hybrid Search Architectures in RAG
Modern enterprise systems use several hybrid retrieval strategies.
Sparse + Dense Retrieval
Combines:
- sparse keyword vectors
- dense semantic embeddings
This is one of the most common hybrid architectures.
BM25 + Vector Search
BM25 handles keyword ranking while vector search handles semantic retrieval.
Widely used in enterprise search systems.
Multi-Stage Retrieval
Some systems perform:
- keyword retrieval
- semantic retrieval
- re-ranking
This improves enterprise retrieval quality significantly.
Weighted Hybrid Retrieval
Some architectures assign weights to:
- semantic scores
- keyword scores
This enables fine-tuned ranking optimization.
Hybrid Search in RAG: Real-World Use Cases
Enterprise Search Systems
Employees retrieve enterprise knowledge conversationally while maintaining exact terminology accuracy.
AI Customer Support
Support assistants retrieve troubleshooting workflows and exact product documentation.
Legal AI Systems
Legal retrieval requires both semantic understanding and exact legal terminology matching.
Ecommerce AI
Shopping assistants retrieve products using semantic intent plus exact SKU matching.
Healthcare AI
Medical systems retrieve semantically relevant guidelines while preserving terminology precision.
Financial AI Systems
Finance systems retrieve policies, identifiers, and compliance rules accurately.
Common Challenges in Hybrid Retrieval
While hybrid search is powerful, it still introduces complexity.
Infrastructure Complexity
Hybrid systems require:
- vector databases
- keyword indexes
- retrieval orchestration
- ranking systems
This increases engineering complexity.
Tuning Difficulty
Balancing semantic and keyword weighting requires experimentation.
Latency
Multiple retrieval systems increase computational overhead.
Relevance Optimization
Poor ranking strategies can still produce noisy retrieval results.
Scaling Enterprise Systems
Large-scale hybrid retrieval systems require strong infrastructure optimization.
Future of Hybrid Search in RAG
Hybrid retrieval systems are evolving rapidly.
Major trends include:
- AI-powered re-ranking
- graph-enhanced hybrid retrieval
- multimodal hybrid search
- agentic retrieval systems
- personalized retrieval ranking
- autonomous enterprise search systems
Many experts believe hybrid retrieval will become standard architecture for enterprise AI systems.
Suggested Read:
- Vector Database for RAG
- Embeddings for RAG
- RAG Architecture Explained
- RAG Pipeline Explained
- RAG for Enterprise Search
- RAG for Document Search
FAQ: Hybrid Search in RAG
What is hybrid search in RAG?
Hybrid search combines semantic retrieval and keyword search inside the same RAG system.
Why is hybrid retrieval important?
It improves retrieval accuracy by combining contextual understanding with exact matching.
What is semantic retrieval?
Semantic retrieval uses embeddings to retrieve information based on meaning.
What is keyword retrieval?
Keyword retrieval searches using exact word matching and lexical ranking.
Does hybrid search reduce hallucinations?
Yes. Better retrieval quality improves factual grounding and reduces hallucinations.
Final Takeaway
Understanding hybrid search in RAG is important because retrieval quality directly affects AI accuracy, grounding, and enterprise reliability.
By combining semantic retrieval with keyword-based precision, hybrid search systems create more intelligent, scalable, and enterprise-ready AI retrieval architectures.
That combination is transforming how AI assistants, enterprise search systems, customer support platforms, and intelligent document retrieval systems operate today.