Vector Database for RAG: How AI Retrieval Systems Store and Search Knowledge
Retrieval-Augmented Generation (RAG) has become one of the most important architectures in modern Artificial Intelligence systems. Enterprises increasingly rely on RAG-powered AI assistants, semantic enterprise search platforms, document retrieval systems, and intelligent chatbots to deliver more accurate and grounded responses.
But behind nearly every successful RAG system is a critical technology layer that enables semantic retrieval at scale:
Vector Databases
Without vector databases, modern semantic search and Retrieval-Augmented Generation systems would struggle to retrieve relevant information efficiently.
Traditional databases were designed for structured data and exact matching. However, modern AI systems require something fundamentally different. They need the ability to search based on meaning, context, and semantic similarity.
That is exactly what vector databases enable.
Today, vector databases power many advanced AI applications including:
- enterprise search systems
- AI copilots
- semantic document retrieval
- AI chatbots
- recommendation engines
- knowledge assistants
- document intelligence systems
In this guide, you will learn how vector databases for RAG work, why they are essential for semantic retrieval, and how they improve AI search quality in modern enterprise systems.
In Simple Terms
What Is a Vector Database in RAG?
A vector database is a specialized database designed to store and retrieve embeddings efficiently.
In RAG systems, documents are converted into embeddings, which are numerical vector representations of meaning.
The vector database stores these embeddings and helps the AI system retrieve semantically relevant information when users ask questions.
Instead of searching for exact keywords, vector databases search based on contextual similarity.
Think of vector databases as semantic search engines for AI systems.
Why Vector Databases Are Important for RAG
Modern Retrieval-Augmented Generation systems depend heavily on semantic retrieval.
Without vector databases, AI retrieval systems would behave more like traditional keyword search engines.
Vector databases make semantic retrieval possible at scale.
Traditional Databases Were Not Built for Semantic Search
Traditional SQL databases work well for:
- exact matching
- structured queries
- transactional systems
- relational data
But semantic AI retrieval requires something different.
RAG systems need to retrieve information based on meaning rather than exact text matches.
For example:
A user may ask:
“How do customer refunds work?”
But the document may contain:
“product return compensation policy”
Traditional databases may struggle with this mismatch.
Vector databases solve this using embeddings and semantic similarity.
Modern AI Systems Need Semantic Understanding
Enterprise data often contains:
- inconsistent terminology
- abbreviations
- technical language
- synonyms
- domain-specific phrases
Vector databases help AI systems retrieve relevant information despite wording differences.
This dramatically improves enterprise search quality.
Retrieval Quality Affects AI Accuracy
Retrieval is one of the most important stages in RAG systems.
If retrieval quality is poor:
- hallucinations increase
- irrelevant information appears
- answer quality decreases
- user trust drops
Vector databases improve retrieval precision significantly.
This helps AI systems generate more grounded responses.
Easy Analogy
Imagine two libraries.
Library A
Stores books alphabetically and only supports exact title matching.
Library B
Understands concepts, themes, meanings, and relationships between books.
Library B behaves like a vector database.
That second approach is dramatically more intelligent for AI retrieval systems.
This is why vector databases became foundational infrastructure for modern RAG architectures.
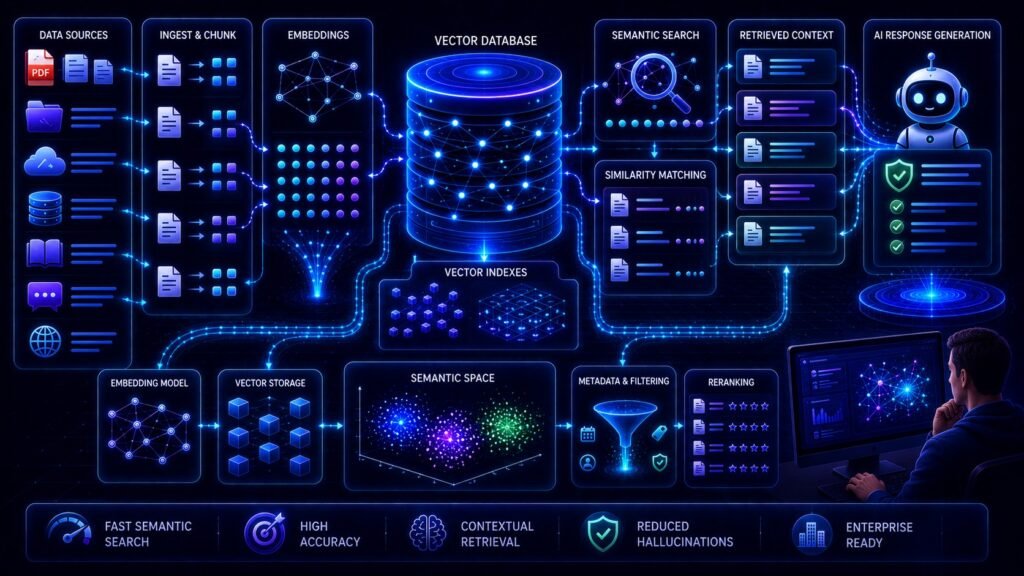
How Vector Databases Work in RAG Systems
Understanding vector databases becomes easier when broken into stages.
Step 1: Documents Are Collected
The RAG system gathers external knowledge sources such as:
- PDFs
- websites
- enterprise documents
- support manuals
- cloud files
- operational guides
- databases
- research papers
These files become the AI knowledge base.
Step 2: Documents Are Split Into Chunks
Large documents are divided into smaller sections called chunks.
For example:
A 600-page enterprise manual may become hundreds of searchable semantic chunks.
Chunking improves retrieval precision.
Smaller chunks are easier to compare contextually.
Choosing the right chunk size is one of the most important optimization tasks in RAG systems.
Step 3: Embeddings Are Generated
The chunks are converted into embeddings using embedding models.
What Are Embeddings?
Embeddings are numerical vector representations of meaning.
For example:
[0.34, -0.28, 0.71, 0.19, …]
Humans cannot interpret these vectors directly, but AI systems can compare them mathematically.
The closer two vectors are, the more semantically similar they are.
This enables semantic retrieval.
Step 4: Embeddings Are Stored in the Vector Database
The generated embeddings are stored inside vector databases.
Popular vector database platforms include:
The vector database indexes embeddings for fast semantic retrieval.
This indexing stage is critical because enterprise AI systems may contain millions of embeddings.
Efficient indexing dramatically improves search performance.
Step 5: Users Ask Questions
A user submits a query.
Example:
“What is the employee reimbursement policy?”
The query now enters the retrieval workflow.
Step 6: Query Embeddings Are Generated
The user query is converted into embeddings using the same embedding model.
This creates a semantic representation of the question.
The system can now compare the query vector against stored document vectors.
Step 7: Semantic Vector Search Happens
The vector database searches for the most semantically similar embeddings.
This retrieval process identifies document chunks that are contextually relevant.
For example:
“How do travel reimbursements work?”
may retrieve:
- employee expense policies
- compensation workflows
- travel reimbursement guidelines
even if the wording differs significantly.
This is one reason why vector databases outperform traditional keyword search systems.
Step 8: Retrieved Chunks Are Sent to the LLM
The retrieved information is inserted into the prompt sent to the language model.
The AI now receives:
- user query
- retrieved contextual information
- system instructions
This allows the model to generate grounded responses using retrieved evidence.
Why Vector Databases Improve RAG Systems
Vector databases solve several major retrieval problems simultaneously.
Semantic Search Instead of Keyword Matching
Vector databases search based on meaning instead of exact words.
This dramatically improves retrieval relevance.
Better Enterprise Knowledge Discovery
Enterprise documents often contain inconsistent terminology.
Vector databases help retrieve relevant information despite wording differences.
Reduced Hallucinations
Better retrieval improves factual grounding.
This helps reduce hallucinations significantly.
Faster Retrieval at Scale
Modern vector databases are optimized for large-scale semantic search.
This enables enterprise AI systems to search millions of embeddings efficiently.
Better User Experience
Users can ask natural language questions instead of carefully engineered keyword queries.
This improves usability dramatically.
Popular Vector Databases Used in RAG
Several vector database platforms are commonly used in modern RAG systems.
Pinecone
Popular managed vector database optimized for scalability and production AI systems.
Widely used in enterprise RAG workflows.
Weaviate
Open-source vector database with strong semantic search capabilities.
Often used for enterprise AI systems.
Chroma
Developer-friendly vector database commonly used in AI prototypes and smaller applications.
Milvus
High-performance open-source vector database optimized for large-scale retrieval systems.
Qdrant
Modern vector database focused on efficient filtering and semantic retrieval performance.
Vector Databases vs Traditional Databases
| Feature | Traditional Database | Vector Database |
| Exact keyword matching | Strong | Moderate |
| Semantic retrieval | Weak | Strong |
| Embeddings support | Weak | Strong |
| Contextual search | Weak | Strong |
| AI retrieval optimization | Limited | High |
| Natural language retrieval | Limited | Strong |
Advanced Vector Database Techniques in RAG
Modern enterprise systems often use advanced optimization strategies.
Hybrid Search
Combines:
- vector retrieval
- keyword retrieval
for stronger search performance.
Re-Ranking Models
Re-ranking systems improve retrieval quality after initial vector search.
Metadata Filtering
Enterprise systems often filter retrieval using:
- department
- permissions
- timestamps
- categories
- document type
This improves retrieval precision and enterprise security.
Approximate Nearest Neighbor Search (ANN)
ANN algorithms improve vector retrieval speed for massive enterprise datasets.
This is critical for large-scale production AI systems.
Multi-Vector Retrieval
Some advanced systems use multiple embeddings per document for deeper contextual understanding.
Vector Database for RAG: Real-World Use Cases
Enterprise Search Systems
Employees retrieve company knowledge conversationally.
AI Customer Support
Support assistants retrieve troubleshooting documentation dynamically.
Legal AI Platforms
Legal assistants retrieve contracts and compliance documentation semantically.
Healthcare AI
Healthcare systems retrieve medical guidelines contextually.
Ecommerce AI
Shopping assistants retrieve product information semantically.
Research Assistants
Researchers retrieve technical papers and scientific documents conversationally.
Common Challenges With Vector Databases
While vector databases are powerful, they still face limitations.
Infrastructure Complexity
Large-scale vector systems require significant engineering infrastructure.
Storage Costs
Enterprise-scale embedding storage can become expensive.
Retrieval Latency
Semantic retrieval adds additional processing overhead.
Security and Permissions
Enterprise systems must ensure vector retrieval respects access controls.
Embedding Quality
Weak embeddings reduce retrieval accuracy significantly.
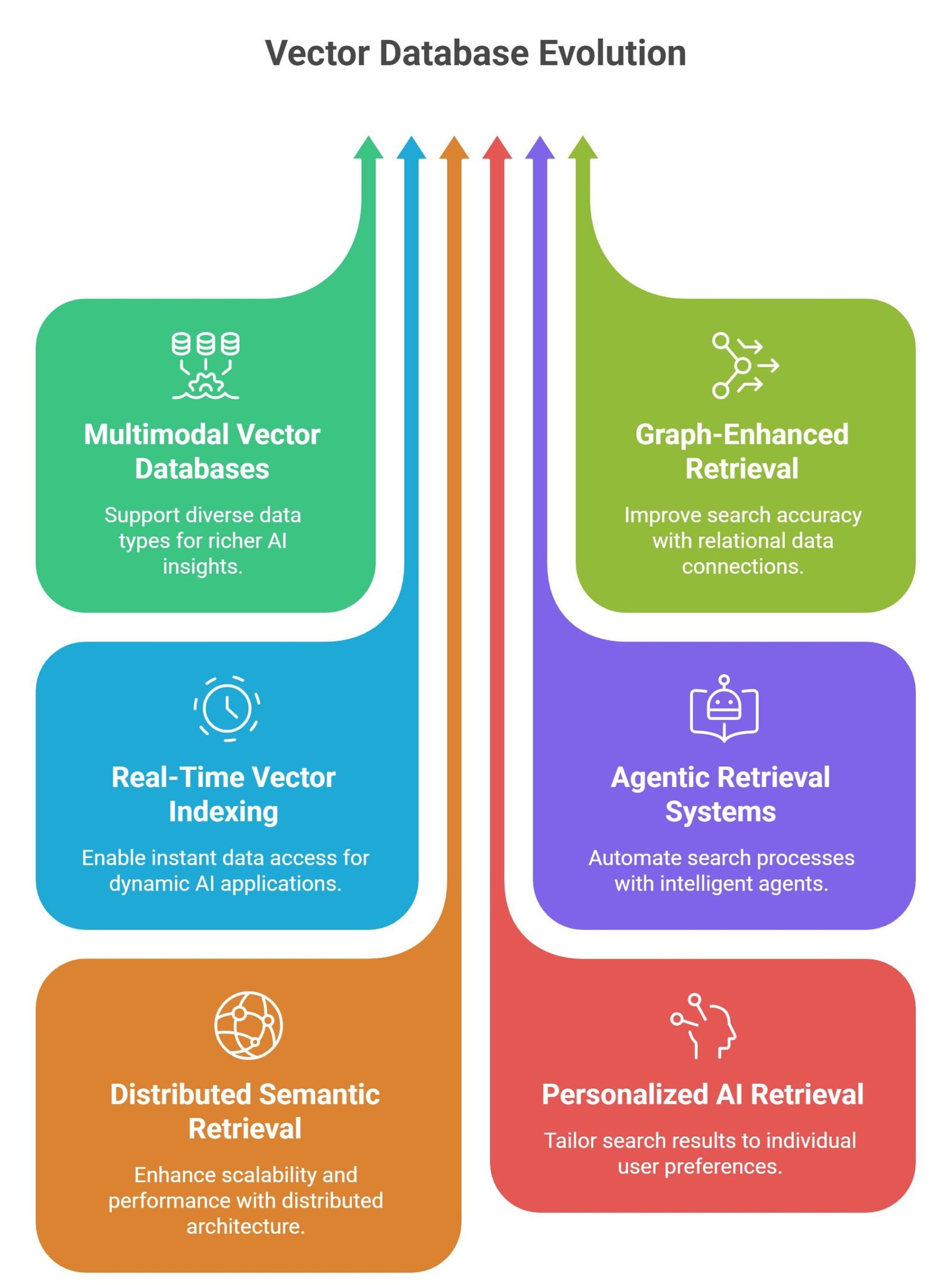
Future of Vector Databases in RAG
Vector database technology is evolving rapidly.
Major trends include:
- multimodal vector databases
- graph-enhanced retrieval
- real-time vector indexing
- agentic retrieval systems
- distributed semantic retrieval
- personalized AI retrieval systems
Many experts believe vector databases will become standard infrastructure for enterprise AI systems.
Suggested Read:
- Embeddings for RAG
- RAG Architecture Explained
- RAG Pipeline Explained
- How RAG Works
- RAG for Enterprise Search
- RAG for Document Search
FAQ: Vector Database for RAG
What is a vector database in RAG?
A vector database stores embeddings and enables semantic retrieval in RAG systems.
Why are vector databases important for RAG?
They allow AI systems to search based on meaning instead of exact keywords.
How do vector databases improve retrieval?
They retrieve semantically similar information using embeddings.
What are embeddings?
Embeddings are vector representations of meaning.
Which vector database is best for RAG?
Popular options include Pinecone, Weaviate, Milvus, Chroma, and Qdrant depending on scalability and infrastructure requirements.
Final Takeaway
Understanding vector databases for RAG is important because vector search infrastructure powers nearly every modern semantic retrieval system.
By enabling AI systems to retrieve information based on meaning instead of exact wording, vector databases dramatically improve retrieval quality, contextual understanding, enterprise search performance, and AI reliability.
That capability is transforming how AI assistants, enterprise search systems, document retrieval platforms, and intelligent knowledge systems operate today.