RAG Pipeline Explained: Complete Guide to Retrieval-Augmented Generation Workflow
Retrieval-Augmented Generation (RAG) has become one of the most important architectures in modern AI systems. As enterprises increasingly adopt AI assistants, intelligent search platforms, enterprise copilots, and document AI systems, RAG pipelines are rapidly becoming foundational infrastructure for production AI applications.
Traditional Large Language Models (LLMs) are powerful, but they still face major limitations. They can hallucinate, generate outdated information, and struggle to access private enterprise knowledge.
That is exactly why retrieval-based AI architectures became essential.
Instead of relying only on training memory, RAG systems retrieve relevant information from external knowledge sources before generating responses. This improves factual grounding, reduces hallucinations, and enables AI systems to work with real enterprise data.
Today, RAG pipelines power many advanced AI applications including:
- enterprise search systems
- AI chatbots
- customer support assistants
- document retrieval platforms
- legal AI tools
- healthcare knowledge systems
- research assistants
In this guide, you will learn how the RAG pipeline works, what each stage does, and why Retrieval-Augmented Generation workflows are transforming enterprise AI systems.
In Simple Terms
What Is a RAG Pipeline?
A RAG pipeline is the complete workflow used in Retrieval-Augmented Generation systems.
It combines:
- document ingestion
- embeddings generation
- vector databases
- semantic retrieval
- prompt augmentation
- language model generation
into one AI workflow.
Instead of generating answers entirely from model memory, the system first retrieves relevant information from external sources before responding.
Think of a RAG pipeline as an AI research workflow where the system searches for information before generating an answer.
Why RAG Pipelines Became Important
Modern AI systems require more than just language generation.
Enterprises need AI systems that are:
- accurate
- grounded in real information
- connected to enterprise data
- capable of semantic search
- updated dynamically
- scalable for production environments
Traditional LLMs struggle with these requirements.
RAG pipelines solve many of these problems simultaneously.
Traditional LLMs Can Hallucinate
Language models predict text patterns instead of verifying facts.
As a result, they sometimes generate convincing but incorrect information.
This becomes risky in industries such as:
- healthcare
- finance
- legal services
- enterprise operations
- cybersecurity
RAG pipelines reduce hallucinations by grounding responses in retrieved information.
AI Knowledge Becomes Outdated
Traditional models only know information available during training.
Once training ends, the model does not automatically learn:
- new policies
- updated documentation
- changing regulations
- live inventory information
- recent research
RAG systems solve this dynamically through retrieval.
Enterprises Need Access to Private Data
Most enterprise knowledge exists inside:
- internal documents
- cloud systems
- support portals
- databases
- PDFs
- operational manuals
- enterprise wikis
Traditional public LLMs cannot directly access this information.
RAG pipelines connect AI systems to enterprise knowledge sources securely.
Core Components of a RAG Pipeline
Before understanding the workflow step by step, it is important to understand the major components.
| Component | Purpose |
| Documents | Knowledge source |
| Chunking System | Splits large files |
| Embedding Model | Converts text into vectors |
| Vector Database | Stores embeddings |
| Retriever | Finds relevant information |
| Prompt Augmentation Layer | Adds retrieved context |
| LLM | Generates final answer |
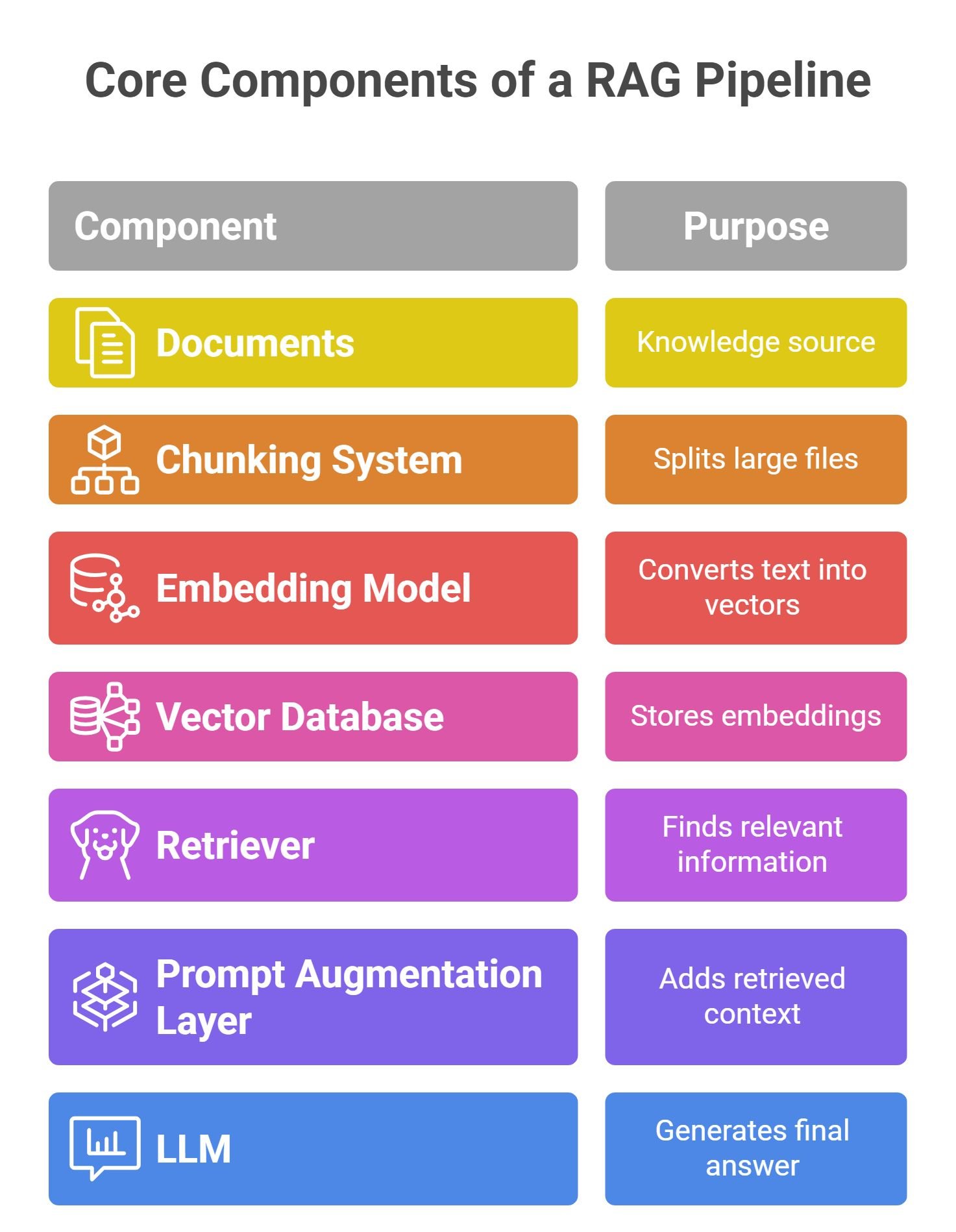
Each stage plays a critical role in improving AI retrieval quality and answer accuracy.
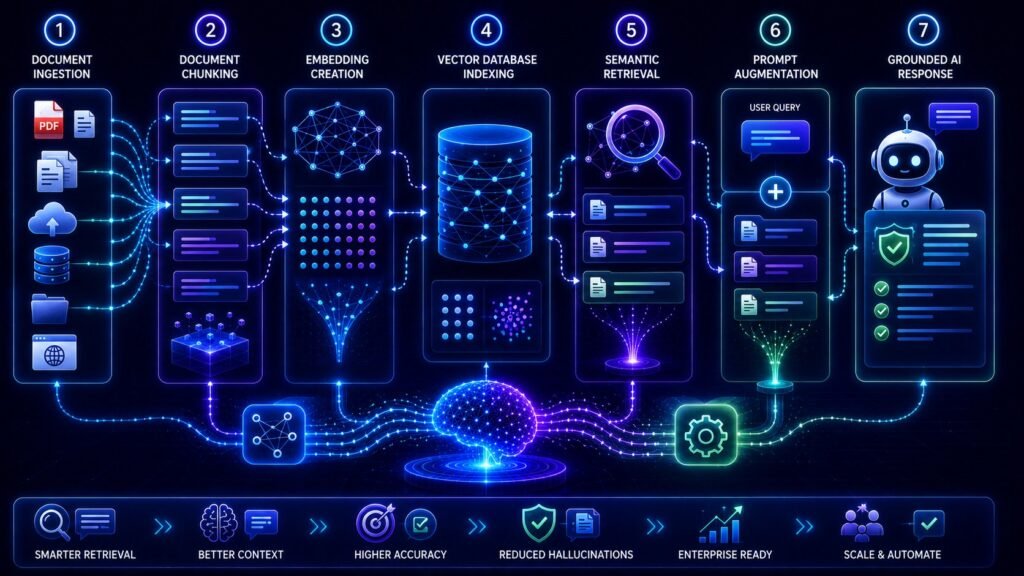
Step-by-Step RAG Pipeline Explained
Now let us break down the complete RAG workflow.
Step 1: Document Ingestion
The first stage involves collecting knowledge sources.
These may include:
- PDFs
- websites
- research papers
- support documentation
- enterprise files
- cloud storage systems
- operational manuals
- databases
These files become the searchable AI knowledge base.
The quality of the knowledge base strongly affects retrieval quality.
If the source data is outdated or incomplete, the AI outputs will also become unreliable.
This is why enterprise data quality is one of the most important parts of production RAG systems.
Step 2: Document Chunking
Large documents are divided into smaller sections called chunks.
For example:
A 500-page enterprise manual may be divided into hundreds of searchable text segments.
Chunking improves retrieval precision because smaller sections are easier to retrieve semantically.
If chunks are too large:
- retrieval becomes noisy
- irrelevant information increases
- prompt quality decreases
If chunks are too small:
- context may become fragmented
- retrieval loses important meaning
Choosing the correct chunk size is one of the most important optimization tasks in modern RAG systems.
Step 3: Embedding Generation
The chunks are converted into embeddings.
What Are Embeddings?
Embeddings are vector representations of meaning.
Instead of matching exact keywords, embeddings allow systems to understand semantic similarity.
For example:
- “refund policy”
- “return process”
- “cancellation rules”
may generate similar embeddings because they share contextual meaning.
This enables semantic search instead of traditional keyword retrieval.
Embeddings are one of the most important technologies behind modern AI retrieval systems.
Step 4: Vector Database Storage
The embeddings are stored inside a vector database.
Popular vector database ecosystems include:
- Pinecone
- Weaviate
- Chroma
- Milvus
These systems are optimized for semantic retrieval at scale.
Unlike traditional databases, vector databases retrieve information based on contextual similarity rather than exact keyword matches.
This dramatically improves retrieval quality.
Vector databases have become foundational infrastructure for enterprise RAG systems.
Step 5: User Query Processing
The user sends a query.
Example:
“What is the company reimbursement policy?”
The query initiates the retrieval workflow.
The system now prepares the query for semantic search.
Step 6: Query Embeddings Are Generated
The user query is converted into embeddings using the same embedding model.
This allows semantic comparison between:
- the user question
- stored document chunks
Even if wording differs, semantically similar information can still be retrieved.
For example:
“How do expense reimbursements work?”
may still retrieve documents containing:
“employee compensation guidelines”
This is one reason why RAG systems outperform traditional keyword search systems.
Step 7: Semantic Retrieval Happens
The retriever searches the vector database for the most relevant document chunks.
This stage is called retrieval.
The retriever returns contextually relevant information based on semantic similarity.
This retrieval stage is what fundamentally differentiates RAG systems from standalone LLMs.
Instead of relying entirely on memory, the AI retrieves grounded evidence before generating answers.
Retrieval quality heavily affects final answer quality.
Weak retrieval systems usually create weak AI outputs.
Step 8: Prompt Augmentation
The retrieved information is inserted into the prompt sent to the language model.
This stage is called prompt augmentation.
The prompt now contains:
- user query
- retrieved document context
- system instructions
- formatting rules
Instead of guessing, the AI now has access to supporting information before generating responses.
This dramatically improves grounding and reliability.
Step 9: Response Generation
The language model generates the final answer using:
- retrieved information
- reasoning capabilities
- prompt instructions
- natural language generation
This final stage is called generation.
Together, retrieval plus generation create the complete Retrieval-Augmented Generation pipeline.
The result is typically more accurate, contextual, and enterprise-ready than traditional standalone LLM outputs.
Why RAG Pipelines Improve AI Systems
RAG pipelines solve several major AI problems simultaneously.
Better Accuracy
The AI retrieves actual information before generating responses.
This improves factual grounding significantly.
For enterprise systems, grounded answers are often more important than creativity.
Reduced Hallucinations
One of the biggest benefits of RAG pipelines is hallucination reduction.
The system retrieves supporting evidence before generating answers.
This improves reliability and trust.
Access to Updated Information
Traditional LLMs only know information available during training.
RAG pipelines retrieve updated information dynamically without requiring retraining.
Enterprise Knowledge Integration
RAG systems can work with:
- internal company documents
- operational workflows
- support systems
- technical manuals
- enterprise knowledge bases
This dramatically improves enterprise AI usefulness.
Better User Experience
Users receive:
- more accurate answers
- contextual responses
- conversational retrieval
- faster knowledge discovery
This improves enterprise productivity significantly.
Real-World RAG Pipeline Use Cases
Enterprise Search Systems
Employees retrieve company knowledge conversationally across multiple systems.
AI Customer Support
Support assistants retrieve troubleshooting workflows before answering customers.
Legal AI Systems
Legal assistants retrieve contracts and compliance documentation dynamically.
Healthcare AI
Healthcare systems retrieve treatment guidelines and medical protocols before responding.
Research Assistants
Researchers retrieve papers and technical documents conversationally.
Ecommerce AI
AI assistants retrieve inventory, product data, and shipping information dynamically.
Advanced RAG Pipeline Optimizations
Modern enterprise systems often use advanced retrieval optimizations.
Hybrid Search
Combines:
- semantic retrieval
- keyword retrieval
for better performance.
Re-Ranking Models
Re-ranking systems improve retrieval quality by sorting results more intelligently.
Metadata Filtering
Retrieval can be filtered using:
- document type
- date
- department
- permissions
- categories
This improves enterprise relevance.
Multi-Step Retrieval
Some systems perform multiple retrieval passes for deeper contextual understanding.
Common Challenges in RAG Pipelines
Despite their power, RAG systems still face challenges.
Poor Retrieval Quality
Weak retrievers reduce answer quality significantly.
Outdated Knowledge Bases
Old documents produce inaccurate outputs.
Infrastructure Complexity
RAG systems require:
- embeddings
- vector databases
- orchestration pipelines
- monitoring systems
- retrieval infrastructure
This increases engineering complexity.
Latency
Retrieval stages add additional processing time.
Security and Permissions
Enterprise systems must ensure secure data access controls.
Future of RAG Pipelines
RAG pipelines are evolving rapidly.
Major trends include:
- multimodal RAG
- graph-based retrieval systems
- AI agents with retrieval capabilities
- personalized retrieval workflows
- autonomous enterprise copilots
- real-time enterprise retrieval systems
Many future AI systems will likely use retrieval architectures by default.
Suggested Read:
- How RAG Works
- RAG Explained Simply
- RAG for Beginners
- RAG for Enterprise Search
- RAG for Document Search
- LLM vs RAG
FAQ: RAG Pipeline Explained
What is a RAG pipeline?
A RAG pipeline is the workflow used in Retrieval-Augmented Generation systems to retrieve information before generating responses.
Why are RAG pipelines important?
RAG pipelines improve AI accuracy, reduce hallucinations, and enable enterprise knowledge retrieval.
What are embeddings in RAG?
Embeddings are vector representations of meaning used for semantic retrieval.
What is a vector database?
A vector database stores embeddings and enables semantic search.
Does RAG replace LLMs?
No. RAG enhances LLM systems by adding retrieval capabilities.
Final Takeaway
Understanding the RAG pipeline explained is important because Retrieval-Augmented Generation is becoming foundational infrastructure for modern AI systems.
By combining retrieval systems with language generation, RAG pipelines help AI applications become more accurate, grounded, scalable, and enterprise-ready.
That workflow is transforming how AI assistants, enterprise search systems, customer support bots, and intelligent knowledge platforms operate today.