LLM Truthfulness Evaluation: How to Measure Honest AI Outputs in 2026
Large Language Models (LLMs) can generate fluent answers in seconds, but fluency does not always equal truth. A response may sound confident while containing false facts, invented sources, or misleading reasoning.
That is why LLM truthfulness evaluation has become a major priority for AI teams.
If your chatbot gives wrong legal guidance, your research tool cites fake studies, or your assistant invents company policies, trust disappears quickly.
This guide explains how to evaluate LLM truthfulness, what metrics matter, and how organizations improve reliability.
In simple terms
LLM truthfulness evaluation means:
Testing whether a language model gives accurate, grounded, and honest answers instead of misleading ones.
It focuses on questions like:
- Is the answer factually correct?
- Did the model invent details?
- Did it admit uncertainty when unsure?
- Did it rely on trusted sources?
- Does confidence match correctness?
Truthfulness is about trust, not just grammar.
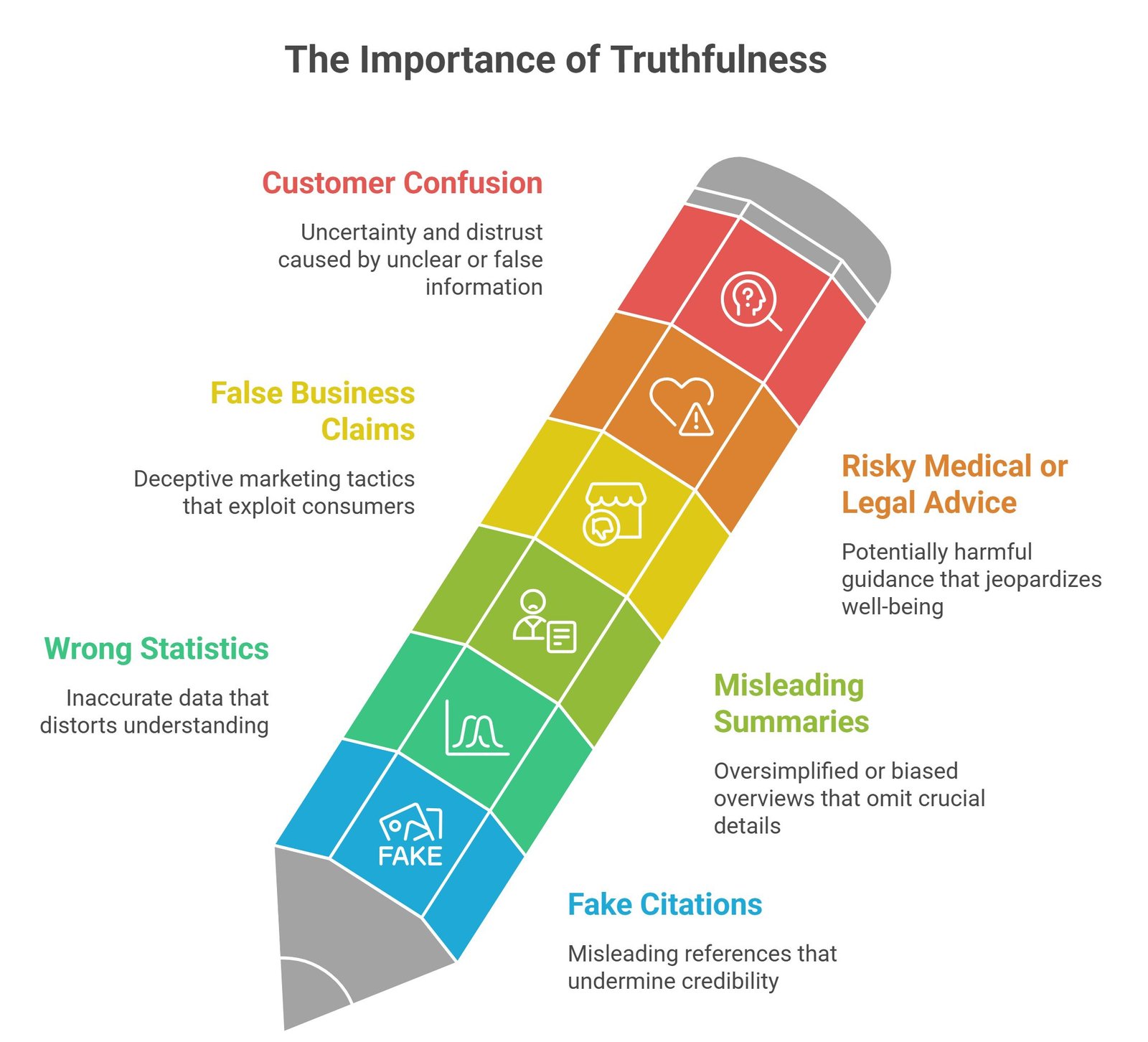
Why Truthfulness Matters
Without truthfulness controls, AI systems may create:
- fake citations
- wrong statistics
- misleading summaries
- false business claims
- risky medical or legal advice
- customer confusion
For many use cases, truthfulness matters more than creativity.
Easy analogy
Imagine hiring two analysts.
Analyst A speaks smoothly but guesses often.
Analyst B is careful, cites sources, and admits uncertainty.
Most businesses prefer Analyst B.
That is the difference truthfulness evaluation helps measure.
Truthfulness vs Related Concepts
| Term | Meaning |
| Truthfulness | Output is honest and accurate |
| Hallucination | Invented or false content |
| Relevance | Answer matches the prompt |
| Fluency | Response sounds natural |
| Safety | Avoids harmful outputs |
A model can be fluent but untruthful.
Core Metrics for LLM Truthfulness Evaluation
1. Factual Accuracy Rate
How often answers are correct.
Example:
82 correct answers out of 100 prompts = 82%.
2. Hallucination Rate
How often the model invents facts, sources, or unsupported claims.
Lower is better.
3. Source Grounding Score
Measures whether claims align with provided documents or citations.
Important for RAG systems.
4. Uncertainty Calibration
Does the model admit uncertainty when unsure?
Better than confident guessing.
5. Consistency
Do repeated runs produce similar truthful answers?
6. Human Reviewer Score
Experts judge factual quality.
Especially useful in specialized domains.
AI ecosystems focused on reliability
Many providers continue improving truthfulness and grounded generation, including:
Still, deployment teams must run their own evaluations.
How to Test LLM Truthfulness Evaluation
1. Use Known-Answer Questions
Create prompts where verified answers already exist.
Examples:
- product specs
- company policies
- math facts
- approved documentation
2. Test Edge Cases
Use ambiguous or difficult prompts.
3. Ask for Sources
Check whether citations are real and relevant.
4. Run Multiple Versions
Compare models and prompts.
5. Use Human Review
Experts catch subtle errors.
Best Truthfulness Tests: Use Case
Customer Support Bot
- policy accuracy
- refund correctness
- escalation honesty
Enterprise Search
- grounded summaries
- citation quality
- no invented policies
Research Assistant
- source validity
- factual summaries
- uncertainty honesty
Coding Assistant
- real APIs only
- accurate syntax
- no fake packages
Example Truthfulness Scorecard
| Metric | Weight |
| Accuracy | 35% |
| Hallucination Rate | 25% |
| Grounding | 20% |
| Uncertainty Handling | 10% |
| Consistency | 10% |
Customize weights by business need.
How to Improve Truthfulness Evaluation
Retrieval-Augmented Generation (RAG)
Connect models to trusted sources.
Better Prompting
Ask models to cite evidence and state uncertainty.
Narrow Scope
Smaller tasks reduce guessing.
Human Review
Critical outputs need oversight.
Continuous Monitoring
Track drift after updates.
Common mistakes teams make
Measuring Only Fluency
Smooth language hides errors.
No Gold Test Set
Need verified answers.
Ignoring Fake Citations
Very common risk.
Trusting One Benchmark
Use multiple evaluation methods.
No Re-testing
Models and prompts evolve.
Truthfulness in Regulated Industries
Especially important in:
- healthcare
- finance
- insurance
- legal
- education
- government workflows
Wrong outputs can create serious consequences.
Future of Truthfulness Evaluation
Expect rapid growth in:
- automated fact-checking layers
- citation verification tools
- confidence scoring systems
- hallucination detection dashboards
- domain-specific truth benchmarks
- real-time grounded AI agents
Truthfulness may become a core buying criterion.
Suggested Read:
- Why LLMs Hallucinate
- How to Reduce LLM Hallucinations
- LLM Evaluation Metrics
- LLM Benchmarking Explained
- LLM Monitoring
- LLM for Beginners
FAQ: LLM Truthfulness Evaluation
What is LLM truthfulness evaluation?
Testing whether AI outputs are accurate, grounded, and honest.
Is truthfulness the same as hallucination reduction?
Related, but truthfulness is broader.
Can truthfulness be measured automatically?
Partly yes, but human review still matters.
Are bigger models always more truthful?
Not always.
What improves truthfulness most?
Trusted retrieval, good prompts, and evaluation loops.
Final takeaway
LLM truthfulness evaluation helps teams measure what users actually care about: whether the AI can be trusted. Fast and fluent outputs are useful, but reliable outputs create lasting value.
The future of AI belongs not just to smart systems—but truthful ones.