Multimodal AI Trends 2026: Top Changes
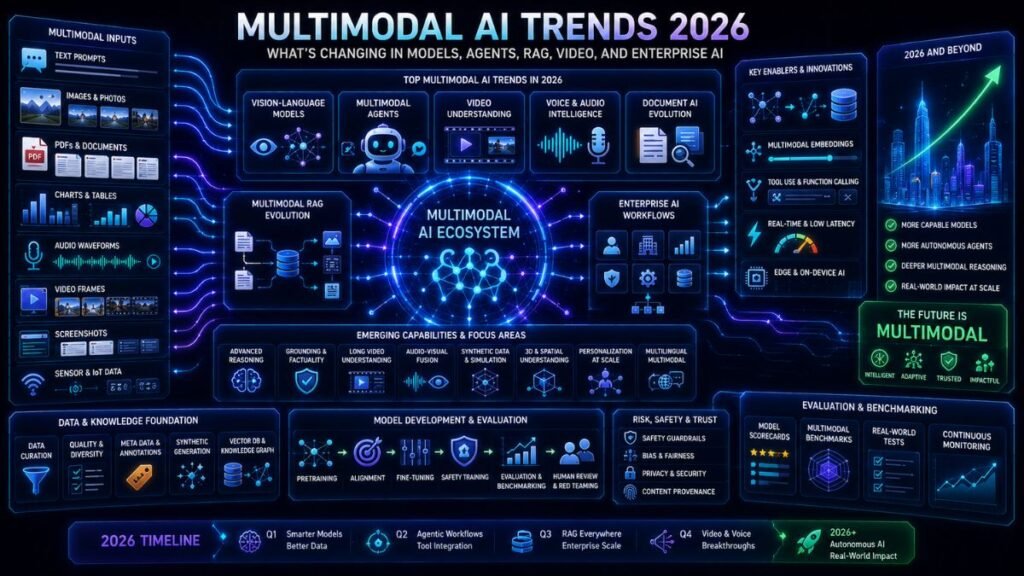
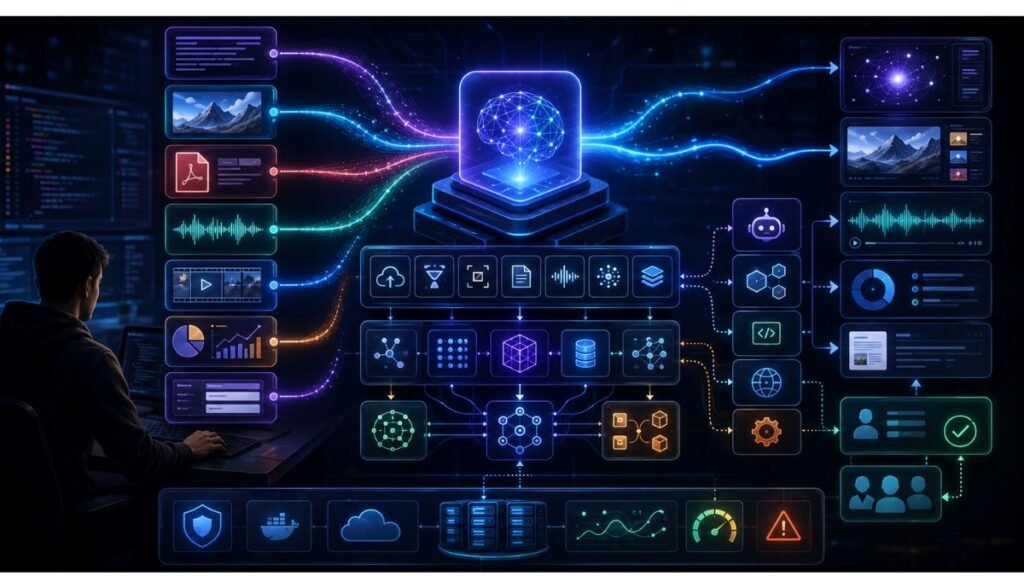
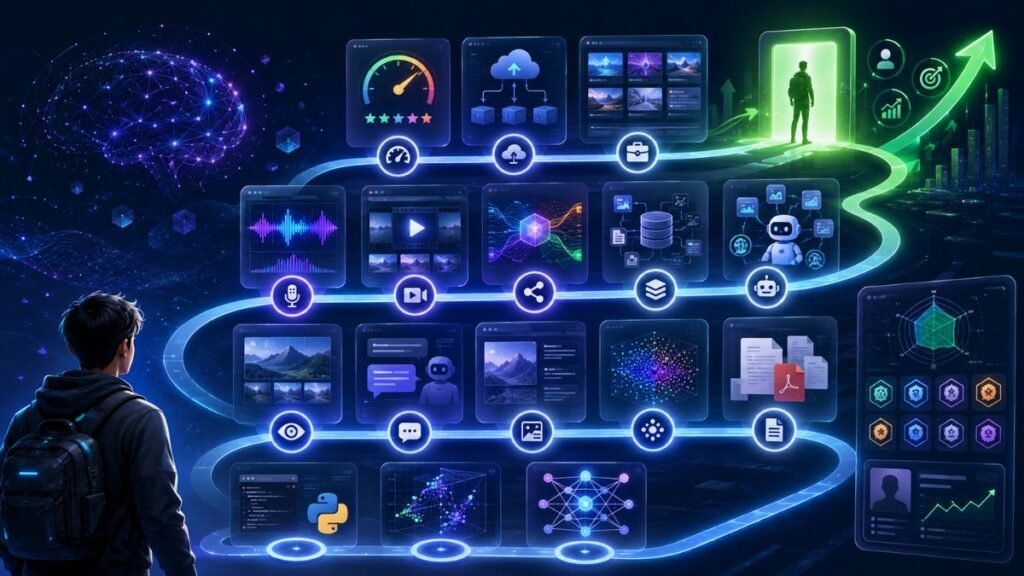
Multimodal AI trends 2026 are moving beyond simple image upload features. The biggest shifts are multimodal agents, stronger vision-language models, video and audio reasoning, multimodal RAG, unified embeddings, document intelligence, enterprise automation, better evaluation, and stronger safety controls for synthetic and sensitive media. In Simple Terms Multimodal AI means AI that works with more than […]
Multimodal AI Trends 2026: Top Changes Read More »