Semantic Search vs RAG: Understanding the Key Differences in AI Retrieval
Modern Artificial Intelligence systems increasingly depend on retrieval technologies to improve accuracy, contextual understanding, and enterprise knowledge access. As AI assistants, enterprise copilots, semantic search systems, and document intelligence platforms continue to evolve, two technologies appear repeatedly in modern AI discussions:
Semantic Search
and
Retrieval-Augmented Generation (RAG)
Although these technologies are closely related, they are not the same thing.
Many beginners assume semantic search and RAG are interchangeable because both involve embeddings, vector databases, and retrieval systems. However, they solve different problems and operate at different architectural layers.
Understanding the difference between semantic search vs RAG is important because modern AI systems often combine both technologies together.
Today, enterprises use semantic retrieval and RAG systems across many applications including:
- enterprise search
- AI chatbots
- customer support assistants
- document retrieval systems
- AI copilots
- legal AI platforms
- healthcare knowledge systems
In this guide, you will learn what semantic search is, how RAG works, how both systems differ, and when organizations should use semantic retrieval versus Retrieval-Augmented Generation architectures.
In Simple Terms
What Is Semantic Search?
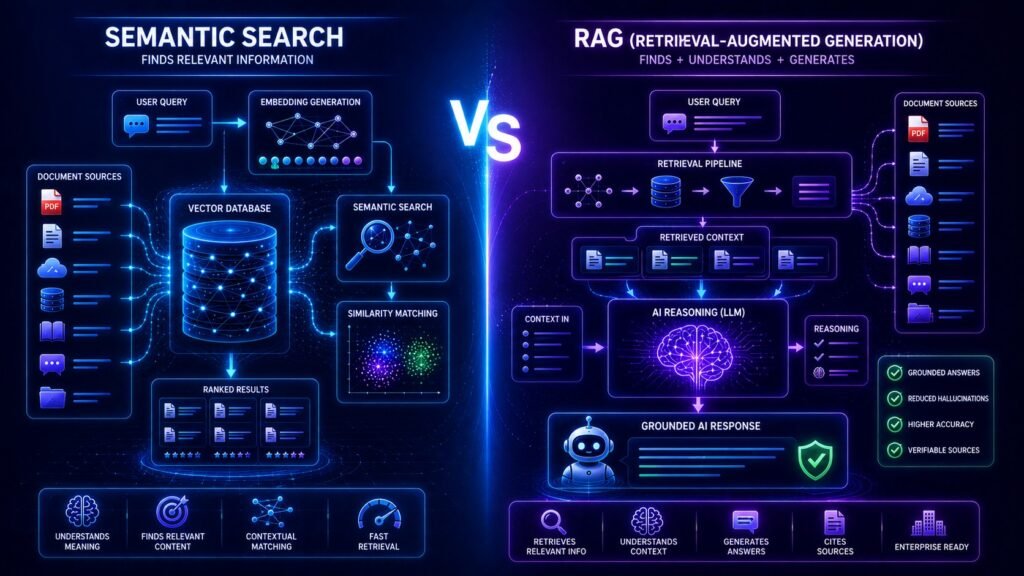
Semantic search is a retrieval technique that searches based on meaning and contextual similarity instead of exact keywords.
Instead of matching exact words, semantic search uses embeddings to understand relationships between concepts.
For example:
A semantic search engine may understand that:
- “refund process”
- “return policy”
- “cancellation workflow”
are contextually related.
Semantic search focuses primarily on:
- retrieval
- contextual similarity
- search relevance
- embeddings-based ranking
It is mainly a retrieval technology.
What Is RAG?
RAG stands for:
Retrieval-Augmented Generation
RAG is a larger AI architecture that combines:
- retrieval systems
- semantic search
- vector databases
- prompt augmentation
- Large Language Models (LLMs)
into one AI workflow.
RAG retrieves relevant information first and then uses a language model to generate grounded responses.
Semantic search is often one component inside a RAG system.
This is one of the most important distinctions.
The Core Difference Between Semantic Search and RAG
The easiest way to understand the difference is this:
| Technology | Main Purpose |
| Semantic Search | Retrieve relevant information |
| RAG | Retrieve + generate AI responses |
Semantic search helps find information.
RAG helps find information and then generate intelligent answers using that information.
This distinction is critical for understanding modern AI architectures.
Why Semantic Search Became Important
Traditional keyword search systems have major limitations.
They rely heavily on exact keyword matching.
This creates retrieval problems when users phrase questions differently from how documents are written.
For example:
A user may ask:
“How do employee reimbursements work?”
But the document may contain:
“travel expense compensation guidelines”
Traditional keyword search may fail.
Semantic search solves this problem by understanding contextual meaning instead of exact wording.
This dramatically improves retrieval quality.
Why RAG Became Important
Traditional Large Language Models also face several limitations.
They can:
- hallucinate
- generate outdated information
- lack enterprise knowledge access
- struggle with private data retrieval
RAG systems solve these problems by retrieving information before generation occurs.
This improves:
- factual grounding
- enterprise relevance
- contextual accuracy
- real-time knowledge access
RAG systems became essential for enterprise AI reliability.
How Semantic Search Works
Understanding semantic search helps explain why it became foundational for modern retrieval systems.
Step 1: Documents Are Collected
The system gathers external knowledge sources such as:
- PDFs
- enterprise documents
- websites
- cloud files
- support manuals
- research papers
These become searchable knowledge repositories.
Step 2: Documents Are Chunked
Large documents are divided into smaller sections called chunks.
Chunking improves retrieval precision.
Smaller chunks are easier to compare contextually.
Step 3: Embeddings Are Generated
The chunks are converted into embeddings.
What Are Embeddings?
Embeddings are numerical vector representations of meaning.
Instead of representing exact keywords, embeddings capture semantic relationships between concepts.
This enables contextual retrieval.
Step 4: Embeddings Are Stored in Vector Databases
The embeddings are stored inside vector databases such as:
These databases support semantic vector search.
Step 5: Queries Are Converted Into Embeddings
When users ask questions, the query is also converted into embeddings.
This creates a semantic representation of user intent.
Step 6: Semantic Retrieval Happens
The vector database retrieves semantically similar document chunks.
The system returns contextually relevant information based on meaning rather than exact keyword matches.
This completes the semantic search workflow.
Notice something important:
Semantic search stops after retrieval.
It retrieves information but does not generate conversational AI responses automatically.
How RAG Works
RAG systems build on top of semantic retrieval systems.
Step 1: Semantic Retrieval Happens
RAG systems often use semantic search internally.
The retriever searches vector databases for relevant information.
This retrieval stage may include:
- semantic search
- keyword search
- hybrid retrieval
- metadata filtering
Step 2: Retrieved Information Is Added to the Prompt
The retrieved document chunks are inserted into the prompt sent to the language model.
This stage is called prompt augmentation.
The AI now receives:
- user query
- retrieved contextual information
- enterprise knowledge
- system instructions
Step 3: The LLM Generates a Response
The language model generates a grounded response using the retrieved context.
This is the key difference:
RAG includes generation.
Semantic search only retrieves information.
RAG retrieves information and generates intelligent responses.
Semantic Search vs RAG Architecture
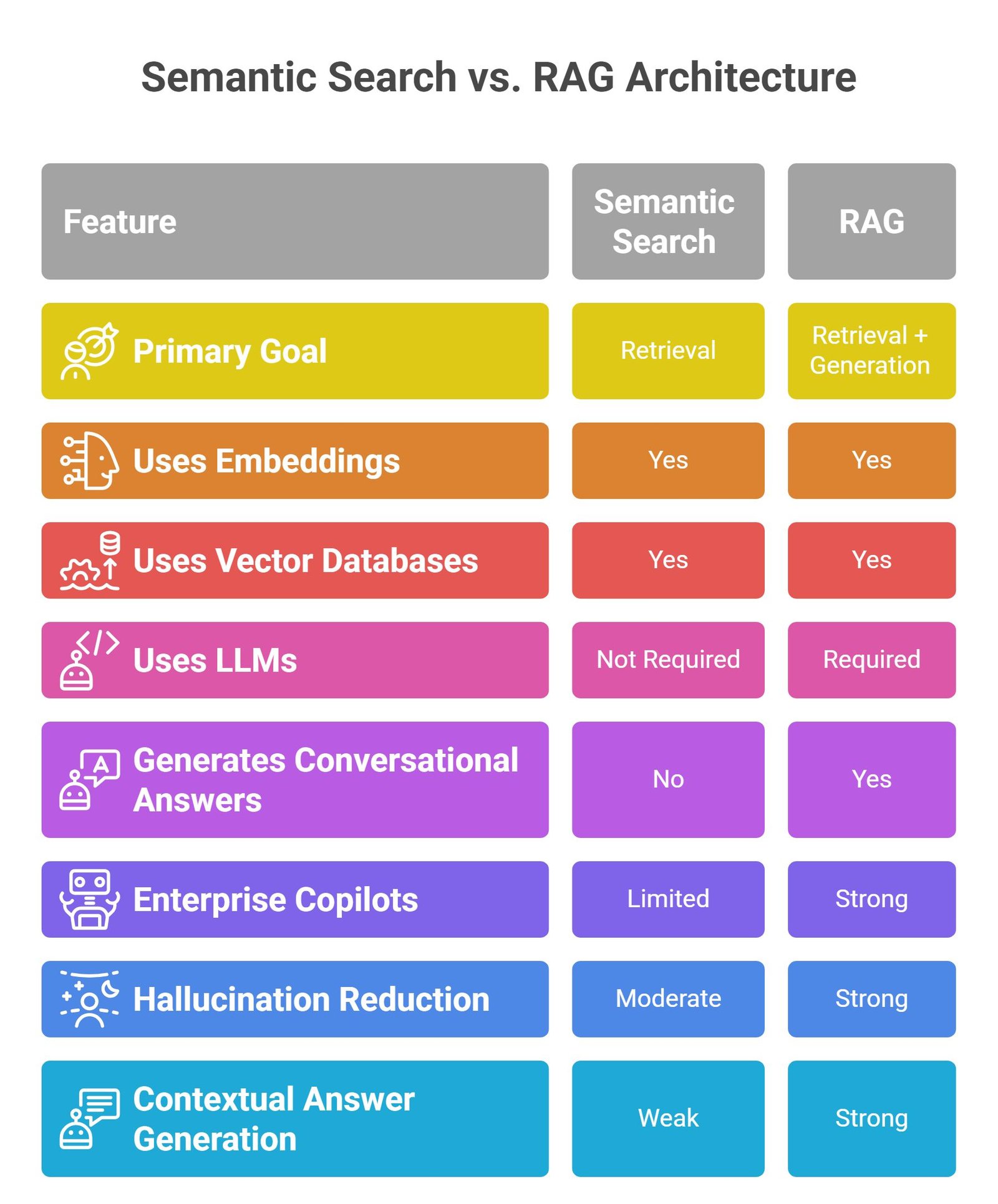
| Feature | Semantic Search | RAG |
| Primary goal | Retrieval | Retrieval + generation |
| Uses embeddings | Yes | Yes |
| Uses vector databases | Yes | Yes |
| Uses LLMs | Not required | Required |
| Generates conversational answers | No | Yes |
| Enterprise copilots | Limited | Strong |
| Hallucination reduction | Moderate | Strong |
| Contextual answer generation | Weak | Strong |
How Semantic Search and RAG Work Together
Many people assume semantic search competes with RAG.
In reality:
RAG often depends on semantic search.
Semantic retrieval is frequently one of the core retrieval layers inside RAG systems.
The workflow often looks like this:
- Semantic search retrieves relevant information
- RAG injects retrieved context into prompts
- LLM generates grounded responses
This means semantic search and RAG are often complementary technologies rather than direct competitors.
When to Use Semantic Search
Semantic search works well when the primary goal is information retrieval.
Common use cases include:
Enterprise Search Systems
Employees retrieve enterprise documents contextually.
Knowledge Discovery Platforms
Users search research papers, documentation, and databases semantically.
Recommendation Systems
Platforms retrieve semantically related products or content.
Search Engines
Modern search engines increasingly use semantic retrieval techniques.
Similarity Search
Semantic embeddings help identify related documents or records.
When to Use RAG
RAG works best when systems must generate intelligent conversational responses.
Common use cases include:
AI Chatbots
Chatbots retrieve information and generate contextual responses.
Enterprise Copilots
AI assistants answer employee questions using enterprise knowledge.
Customer Support AI
Support assistants retrieve troubleshooting workflows before generating responses.
Legal AI Systems
Legal assistants retrieve contracts and generate contextual summaries.
Healthcare AI
Medical assistants retrieve treatment guidelines and generate grounded answers.
Why RAG Reduces Hallucinations Better
Semantic search alone only retrieves documents.
It does not control how an LLM generates responses.
RAG systems improve hallucination reduction because retrieved information becomes grounding context for the model.
This allows the AI to generate responses based on retrieved evidence instead of relying entirely on memory.
That architectural difference significantly improves enterprise AI reliability.
Semantic Search vs RAG for Enterprises
Enterprise organizations increasingly use both technologies together.
Semantic Search Helps Enterprises
- improve document discovery
- enable contextual retrieval
- search across large knowledge bases
- reduce keyword dependency
RAG Helps Enterprises
- build enterprise copilots
- create conversational AI systems
- improve answer generation
- reduce hallucinations
- connect LLMs to enterprise data
Together, these technologies create intelligent enterprise AI ecosystems.
Common Challenges With Semantic Search
Semantic retrieval still faces several challenges.
Weak Embeddings
Poor embeddings reduce retrieval quality significantly.
Retrieval Noise
Semantic retrieval sometimes returns loosely related content.
Scaling Vector Databases
Large-scale enterprise retrieval systems require optimized infrastructure.
Lack of Generation
Semantic search alone does not provide conversational AI experiences.
Common Challenges With RAG
RAG systems also introduce complexity.
Infrastructure Complexity
RAG systems require:
- embeddings
- vector databases
- retrieval orchestration
- LLM integration
- prompt engineering
- monitoring systems
Latency
Retrieval plus generation increases processing overhead.
Retrieval Quality Dependence
Poor retrieval creates poor AI responses.
Security and Permissions
Enterprise systems must protect sensitive data access.
Future of Semantic Search and RAG
Both technologies are evolving rapidly.
Major trends include:
- multimodal retrieval
- graph-enhanced retrieval systems
- hybrid search architectures
- agentic RAG systems
- personalized semantic retrieval
- autonomous enterprise AI assistants
Most future enterprise AI systems will likely combine:
- semantic retrieval
- vector databases
- RAG workflows
- intelligent orchestration layers
into unified AI ecosystems.
Suggested Read:
- Hybrid Search in RAG
- Vector Database for RAG
- Embeddings for RAG
- RAG Architecture Explained
- How RAG Works
- LLM vs RAG
FAQ: Semantic Search vs RAG
What is the difference between semantic search and RAG?
Semantic search retrieves information based on meaning, while RAG retrieves information and then generates AI responses using that information.
Does RAG use semantic search?
Yes. Many RAG systems use semantic retrieval internally.
Is semantic search enough for AI chatbots?
Not usually. Chatbots often require generation capabilities, which RAG provides.
Does RAG reduce hallucinations?
Yes. Retrieved context helps ground responses in factual information.
Which is better: semantic search or RAG?
They solve different problems. Semantic search focuses on retrieval, while RAG focuses on retrieval plus generation.
Final Takeaway
Understanding semantic search vs RAG is important because both technologies play critical roles in modern AI systems.
Semantic search helps AI systems retrieve relevant information contextually, while RAG extends retrieval by enabling grounded conversational response generation.
Together, these technologies are transforming enterprise search, AI assistants, customer support systems, document intelligence platforms, and modern AI infrastructure.