Reranking in RAG: How AI Retrieval Systems Improve Search Accuracy
Retrieval-Augmented Generation (RAG) systems have become foundational infrastructure for modern Artificial Intelligence applications. Enterprises increasingly use RAG-powered AI assistants, enterprise search systems, customer support copilots, legal AI platforms, and document intelligence systems to improve AI accuracy and reduce hallucinations.
However, even advanced semantic retrieval systems still face one major challenge:
Retrieval quality
A RAG system is only as good as the information it retrieves.
If the retrieval layer returns irrelevant, outdated, or weak contextual information, the Large Language Model (LLM) may generate inaccurate or hallucinated responses.
This is exactly why reranking became one of the most important optimization techniques in modern RAG architecture.
Reranking helps AI systems evaluate retrieved documents more intelligently before sending them to the language model.
Instead of relying entirely on the initial retrieval stage, reranking introduces a second layer of contextual analysis that improves precision, relevance, and answer quality.
Today, reranking systems power many advanced enterprise AI applications including:
- AI enterprise search
- customer support assistants
- semantic retrieval systems
- legal AI workflows
- healthcare knowledge retrieval
- AI copilots
- research assistants
In this guide, you will learn how reranking in RAG works, why rerankers became critical for enterprise AI systems, and how reranking dramatically improves retrieval quality and grounded AI responses.
In Simple Terms
What Is Reranking in RAG?
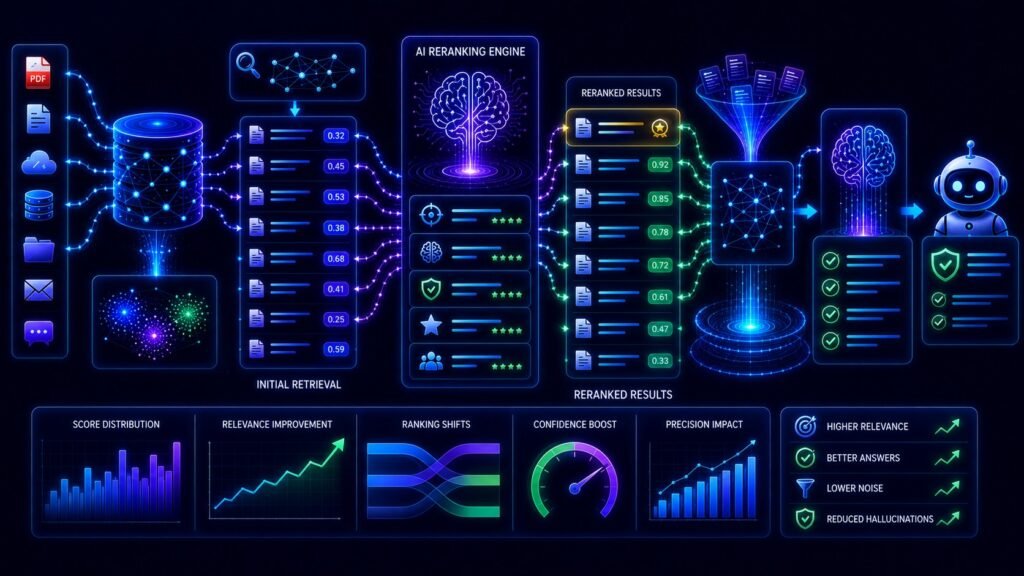
Reranking is a retrieval optimization process used in RAG systems to reorder retrieved search results based on deeper contextual relevance.
The retriever first gathers potentially useful document chunks.
Then the reranker analyzes those chunks more carefully and sorts them from most relevant to least relevant.
Only the highest-ranked chunks are sent to the language model.
Think of reranking as a second intelligence layer that improves retrieval quality before AI response generation begins.
Why Reranking Became Important in RAG
Modern enterprise retrieval systems operate across massive knowledge bases.
These systems often contain:
- millions of document chunks
- overlapping enterprise terminology
- duplicate workflows
- outdated policies
- loosely related contextual information
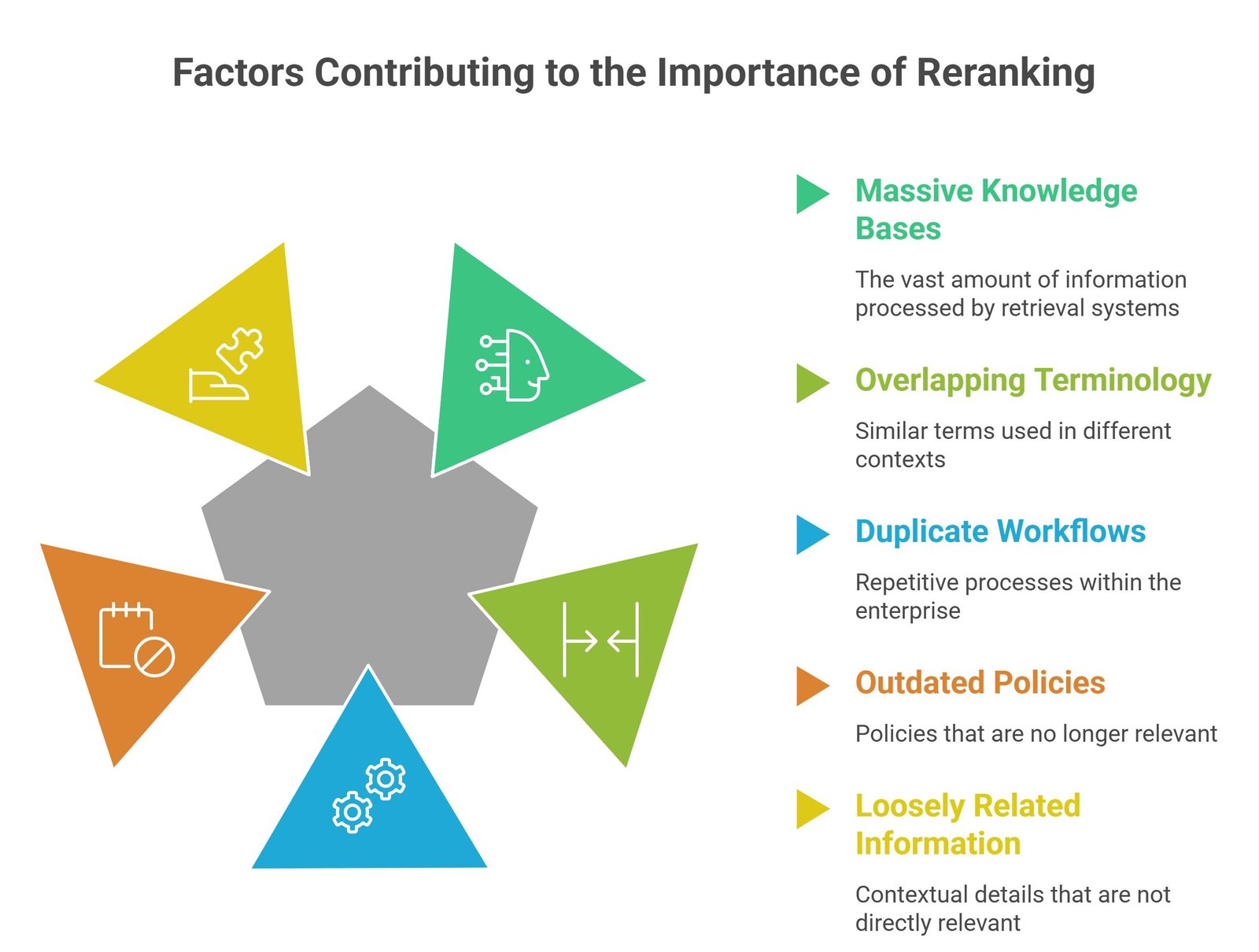
Even strong semantic retrievers can retrieve noisy or partially relevant information.
Reranking helps solve this problem.
Retrieval Systems Prioritize Speed
Most vector retrieval systems are optimized for:
- scalability
- low latency
- fast semantic retrieval
To retrieve information quickly, retrievers often use approximate similarity search methods.
This improves speed but may reduce ranking precision.
As a result, the initial retrieval stage may not always identify the best contextual matches.
Weak Retrieval Creates Weak AI Responses
Large Language Models depend heavily on retrieval quality.
If irrelevant chunks enter the prompt:
- hallucinations increase
- contextual accuracy decreases
- answer quality weakens
- enterprise trust drops
Reranking improves retrieval precision before generation occurs.
This significantly improves AI reliability.
Enterprises Need High-Precision Retrieval
Enterprise AI systems require:
- accurate contextual grounding
- permission-aware retrieval
- compliance-safe search
- domain-specific relevance
- retrieval consistency
Reranking helps enterprise systems achieve these requirements more effectively.
Easy Analogy
Imagine searching for legal documents inside a massive enterprise archive.
The retrieval system first finds 30 potentially relevant files.
However, not all 30 files are equally useful.
A second expert now reviews the results carefully and rearranges them from most relevant to least relevant.
That second expert behaves like a reranker.
This additional review process dramatically improves search quality.
How Reranking Works in RAG Systems
Understanding reranking becomes easier when broken into stages.
Step 1: Documents Are Collected
The RAG system gathers external knowledge sources such as:
- PDFs
- enterprise manuals
- support documents
- websites
- cloud storage files
- research papers
- operational workflows
These become searchable knowledge repositories.
Step 2: Documents Are Chunked
Large documents are divided into smaller sections called chunks.
Chunking improves semantic retrieval precision.
Smaller chunks are easier to compare contextually.
Step 3: Embeddings Are Generated
The chunks are converted into embeddings.
What Are Embeddings?
Embeddings are numerical vector representations of semantic meaning.
Instead of matching exact keywords, embeddings allow retrieval systems to understand contextual relationships between concepts.
This enables semantic retrieval.
Step 4: Embeddings Are Stored in Vector Databases
The embeddings are stored inside vector databases such as:
These systems support semantic retrieval at scale.
Step 5: User Queries Enter the Retrieval System
A user submits a question.
Example:
“What is the latest enterprise reimbursement approval process?”
The retrieval workflow now begins.
Step 6: Initial Semantic Retrieval Happens
The retriever searches the vector database for semantically similar document chunks.
The system retrieves a candidate set of results such as:
- top 10 chunks
- top 20 chunks
- top 50 chunks
However, not all retrieved chunks are equally useful.
Some may only be partially relevant.
Others may contain noisy contextual information.
Step 7: The Reranker Evaluates Retrieved Results
The reranker now performs deeper contextual analysis.
Unlike simple vector similarity search, rerankers evaluate:
- query intent
- semantic alignment
- contextual precision
- answer usefulness
- ranking confidence
This stage is more intelligent than basic retrieval.
The reranker carefully analyzes how useful each retrieved chunk is for answering the user’s question.
Step 8: Results Are Reordered
The reranker sorts the retrieved chunks from highest relevance to lowest relevance.
The most useful chunks move to the top.
Weak or noisy chunks move lower in the ranking list.
This dramatically improves retrieval precision.
Step 9: Top-Ranked Chunks Are Sent to the LLM
Only the best-ranked chunks are inserted into the prompt sent to the Large Language Model.
The AI now receives:
- user query
- highly relevant contextual information
- enterprise-approved retrieval results
- grounded supporting evidence
This significantly improves answer quality.
Why Reranking Improves RAG Systems
Reranking solves several major retrieval problems simultaneously.
Better Retrieval Precision
Reranking improves contextual relevance dramatically.
The system prioritizes stronger retrieval candidates before generation begins.
Reduced Hallucinations
Better retrieval quality improves factual grounding.
This helps reduce unsupported AI responses.
Better Enterprise Search Quality
Enterprise knowledge bases often contain:
- overlapping terminology
- duplicate documentation
- outdated workflows
- loosely related policies
Reranking helps prioritize the most contextually useful information.
Better Use of Context Windows
LLMs have limited context windows.
Reranking ensures the most important information enters the prompt first.
This improves prompt efficiency significantly.
Improved Conversational Accuracy
Reranking improves alignment between:
- user intent
- retrieved context
- generated responses
This creates more accurate conversational AI systems.
Retrieval vs Reranking
| Feature | Retrieval | Reranking |
| Main purpose | Find candidate chunks | Improve ranking precision |
| Speed optimization | Strong | Moderate |
| Deep contextual analysis | Limited | Strong |
| Retrieval scalability | Very high | Moderate |
| Semantic precision | Moderate | Strong |
| Position in pipeline | First stage | Second-stage optimization |
Common Types of Reranking Models
Modern RAG systems use several reranking architectures.
Cross-Encoder Rerankers
Cross-encoders analyze:
- user query
- retrieved chunk
together inside the same model.
This enables deeper contextual understanding.
Cross-encoders are highly accurate but computationally expensive.
Bi-Encoder + Cross-Encoder Pipelines
One of the most common enterprise architectures combines:
- fast bi-encoder retrieval
- cross-encoder reranking
- grounded generation
This balances scalability and precision.
LLM-Based Reranking
Some advanced systems use Large Language Models themselves for reranking.
This enables deeper reasoning during retrieval optimization.
Hybrid Reranking
Hybrid reranking combines:
- semantic similarity
- keyword relevance
- metadata filtering
- business logic
- enterprise policies
into one ranking workflow.
Metadata-Aware Reranking
Some rerankers also evaluate:
- timestamps
- permissions
- departments
- regions
- source systems
This improves enterprise retrieval precision significantly.
Why Cross-Encoder Rerankers Are Powerful
Cross-encoder rerankers became especially important because they evaluate relationships more deeply than standard vector similarity systems.
Instead of comparing embeddings independently, cross-encoders evaluate:
- full query meaning
- document meaning
- contextual interaction
inside the same inference pass.
This allows stronger ranking accuracy.
However, cross-encoders require more computation, which is why they are usually applied after initial retrieval instead of during the first search stage.
Reranking and Hallucination Reduction
Hallucinations often happen because the AI receives weak retrieval context.
If irrelevant chunks enter the prompt:
- unsupported responses increase
- factual grounding weakens
- contextual reliability decreases
Reranking improves retrieval quality before generation occurs.
This creates stronger grounding for the model.
As a result:
- factual accuracy improves
- contextual precision improves
- hallucinations decrease
This is one reason why reranking became critical for enterprise-grade RAG systems.
Real-World Use Cases: Reranking in RAG
Enterprise Search Systems
Employees retrieve more accurate company knowledge conversationally.
AI Customer Support
Support copilots prioritize the best troubleshooting workflows before answering customers.
Legal AI Systems
Legal assistants prioritize highly relevant contracts and compliance documentation.
Healthcare AI
Medical retrieval systems prioritize clinically relevant guidelines.
Ecommerce AI
Shopping assistants rank the most useful products and support content.
Research Assistants
Research systems prioritize the most relevant scientific papers and technical findings.
Common Challenges With Reranking
While reranking is powerful, it also introduces complexity.
Higher Latency
Reranking requires additional inference steps.
This increases retrieval latency.
Infrastructure Costs
Advanced rerankers require additional computational resources.
Large-scale enterprise systems may need GPU acceleration.
Scaling Complexity
Massive enterprise retrieval systems require optimized reranking infrastructure.
Model Selection Challenges
Different rerankers perform differently across industries and domains.
Contextual Bias Risks
Poor reranking models may prioritize incorrect relevance patterns.
Future of Reranking in RAG
Reranking systems are evolving rapidly.
Major trends include:
- multimodal reranking
- graph-enhanced reranking
- reasoning-based reranking
- personalized retrieval ranking
- autonomous retrieval optimization
- agentic AI retrieval systems
Many future enterprise AI systems will likely depend heavily on intelligent reranking architectures.
Suggested Read:
- Metadata Filtering in RAG
- Hybrid Search in RAG
- Semantic Search vs RAG
- Vector Database for RAG
- Embeddings for RAG
- RAG Pipeline Explained
FAQ: Reranking in RAG
What is reranking in RAG?
Reranking improves retrieval quality by reordering retrieved results according to contextual relevance.
Why is reranking important?
It improves retrieval precision, grounding quality, and answer relevance.
Does reranking reduce hallucinations?
Yes. Better retrieval quality improves factual grounding and reduces hallucinations.
What is the difference between retrieval and reranking?
Retrieval finds candidate chunks, while reranking improves their order and contextual precision.
What are cross-encoder rerankers?
Cross-encoders evaluate queries and retrieved chunks together for deeper contextual understanding.
Final Takeaway
Understanding reranking in RAG is important because retrieval quality directly affects AI accuracy, enterprise reliability, and grounded response generation.
By intelligently optimizing retrieval results before information reaches the language model, reranking systems dramatically improve contextual precision, semantic relevance, and enterprise AI performance.
That capability is transforming how AI assistants, enterprise search systems, customer support copilots, legal AI platforms, and intelligent retrieval architectures operate today.