Chunking Strategies for RAG: How AI Retrieval Systems Improve Context
Retrieval-Augmented Generation (RAG) systems have become one of the most important architectures in modern Artificial Intelligence. Enterprises increasingly use RAG-powered AI assistants, enterprise search systems, customer support copilots, and document intelligence platforms to improve AI accuracy and reduce hallucinations.
However, many beginners focus heavily on:
- Large Language Models
- vector databases
- embeddings
- semantic search
while overlooking one of the most critical components of retrieval quality:
Chunking
Chunking directly affects how information is stored, retrieved, and delivered to Large Language Models.
Poor chunking can severely reduce retrieval quality, causing AI systems to retrieve incomplete, irrelevant, or fragmented information.
Strong chunking strategies dramatically improve:
- retrieval precision
- contextual understanding
- semantic search quality
- grounded AI responses
- enterprise search performance
Today, chunking strategies are foundational to modern RAG pipelines used across:
- enterprise AI systems
- semantic search engines
- AI customer support
- legal AI assistants
- healthcare AI platforms
- research retrieval systems
- knowledge management systems
In this guide, you will learn what chunking is, why chunking matters in RAG, and the best chunking strategies used in modern AI retrieval systems.
In Simple Terms
What Is Chunking in RAG?
Chunking is the process of splitting large documents into smaller sections before storing them inside a retrieval system.
These smaller sections are called:
Chunks
Instead of storing entire documents as one massive block, RAG systems divide documents into manageable semantic units.
Each chunk is then converted into embeddings and stored inside vector databases for semantic retrieval.
Why Chunking Is Important
Large Language Models have limited context windows.
Retrieval systems also work better when searching smaller semantic units instead of huge documents.
Chunking helps AI systems:
- retrieve precise information
- improve semantic relevance
- reduce retrieval noise
- improve grounding quality
- optimize vector search
Without chunking, retrieval quality would degrade significantly.
Easy Analogy
Imagine searching for one paragraph inside a 500-page book.
Without chunking, the AI must retrieve the entire book.
With chunking, the AI retrieves only the relevant section.
This dramatically improves retrieval precision.
That is exactly why chunking became critical in RAG systems.
Why Chunking Became Essential in Modern RAG
Modern enterprise datasets are enormous.
Organizations manage:
- PDFs
- manuals
- support documents
- legal contracts
- research papers
- cloud files
- internal wikis
If entire documents were stored as single embeddings:
- retrieval precision would decrease
- semantic relevance would weaken
- prompt sizes would become inefficient
- hallucinations would increase
Chunking solves these retrieval problems.
Chunking Improves Retrieval Granularity
Smaller chunks allow retrieval systems to identify highly relevant contextual information more precisely.
Instead of retrieving entire documents, the system retrieves:
- specific paragraphs
- workflows
- policies
- technical explanations
- answer-focused context
This improves semantic search quality dramatically.
Chunking Improves Prompt Efficiency
Large Language Models have finite context windows.
Sending entire documents into prompts is inefficient and expensive.
Chunking ensures only the most relevant information enters the prompt.
This improves:
- inference efficiency
- prompt quality
- token optimization
- AI grounding
Chunking Reduces Retrieval Noise
Large documents often contain irrelevant contextual information.
Chunking isolates semantically relevant sections more effectively.
This improves retrieval precision significantly.
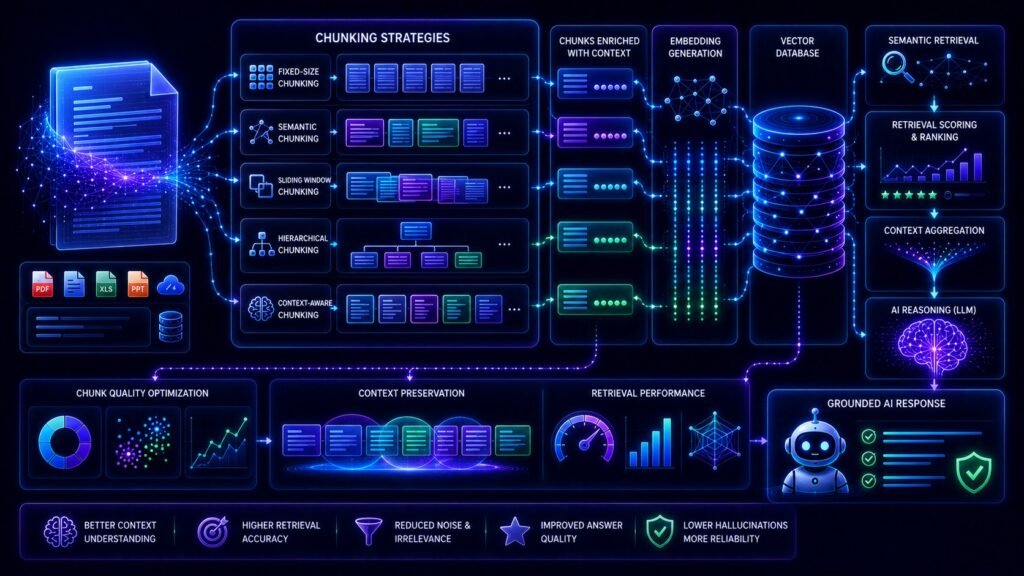
How Chunking Works in RAG Systems
Understanding chunking becomes easier when broken into stages.
Step 1: Documents Are Collected
The RAG system gathers external knowledge sources such as:
- PDFs
- websites
- enterprise documents
- support manuals
- cloud files
- databases
- research papers
These become searchable knowledge repositories.
Step 2: Documents Are Split Into Chunks
The system divides documents into smaller sections.
This process is called chunking.
The chunking strategy determines how documents are segmented.
Step 3: Chunks Are Converted Into Embeddings
Each chunk is converted into embeddings using embedding models.
Embeddings represent semantic meaning numerically.
Step 4: Chunks Are Stored in Vector Databases
The embeddings are stored inside vector databases such as:
This enables semantic retrieval.
Step 5: User Queries Enter the Retrieval System
A user submits a question.
The query is converted into embeddings.
Step 6: Relevant Chunks Are Retrieved
The vector database retrieves semantically relevant chunks.
The retrieved chunks become contextual grounding for the language model.
Step 7: The LLM Generates a Response
The retrieved chunks are inserted into the prompt.
The Large Language Model generates grounded responses using the retrieved context.
This completes the RAG workflow.
Why Chunk Size Matters in RAG
Chunk size directly affects retrieval quality.
Choosing the wrong chunk size can create major retrieval problems.
Small Chunks Improve Precision
Smaller chunks improve retrieval granularity.
Benefits include:
- precise retrieval
- lower retrieval noise
- stronger contextual matching
However, extremely small chunks may lose important context.
Large Chunks Preserve Context
Larger chunks preserve more contextual information.
Benefits include:
- better contextual continuity
- stronger semantic grouping
However, large chunks may introduce retrieval noise.
The Goal Is Contextual Balance
The best chunk size balances:
- retrieval precision
- semantic continuity
- prompt efficiency
- contextual completeness
There is no universal chunk size for every RAG system.
Common Chunking Strategies for RAG
Modern RAG systems use several chunking strategies.
Fixed-Size Chunking
Fixed-size chunking splits documents into chunks using a predefined token or character limit.
Example:
- 500-token chunks
- 1000-character chunks
This is one of the simplest chunking methods.
Advantages of Fixed-Size Chunking
- simple implementation
- scalable processing
- predictable chunk sizes
- efficient indexing
Limitations of Fixed-Size Chunking
Fixed chunking may split:
- paragraphs
- sentences
- workflows
- semantic concepts
in unnatural ways.
This may reduce contextual quality.
Semantic Chunking
Semantic chunking splits documents based on meaning and contextual structure.
Instead of arbitrary token limits, semantic chunking identifies:
- topic boundaries
- paragraph groups
- contextual transitions
- semantic relationships
This creates more meaningful chunks.
Why Semantic Chunking Is Powerful
Semantic chunking improves:
- retrieval relevance
- contextual continuity
- grounding quality
- semantic precision
This makes it especially useful for enterprise RAG systems.
Sliding Window Chunking
Sliding window chunking introduces overlap between chunks.
Example:
Chunk 1:
Tokens 1–500
Chunk 2:
Tokens 400–900
This overlap preserves contextual continuity.
Why Chunk Overlap Matters
Without overlap, important contextual transitions may be lost.
Overlap helps preserve:
- sentence continuity
- workflow context
- semantic relationships
This improves retrieval quality.
Hierarchical Chunking
Hierarchical chunking organizes information into multiple levels.
Example:
- document level
- section level
- paragraph level
- sentence level
This enables multi-level retrieval architectures.
Recursive Chunking
Recursive chunking progressively splits documents into smaller units until chunk requirements are satisfied.
This creates more flexible semantic segmentation.
Context-Aware Chunking
Context-aware chunking uses AI models to determine optimal chunk boundaries dynamically.
This is one of the most advanced chunking strategies.
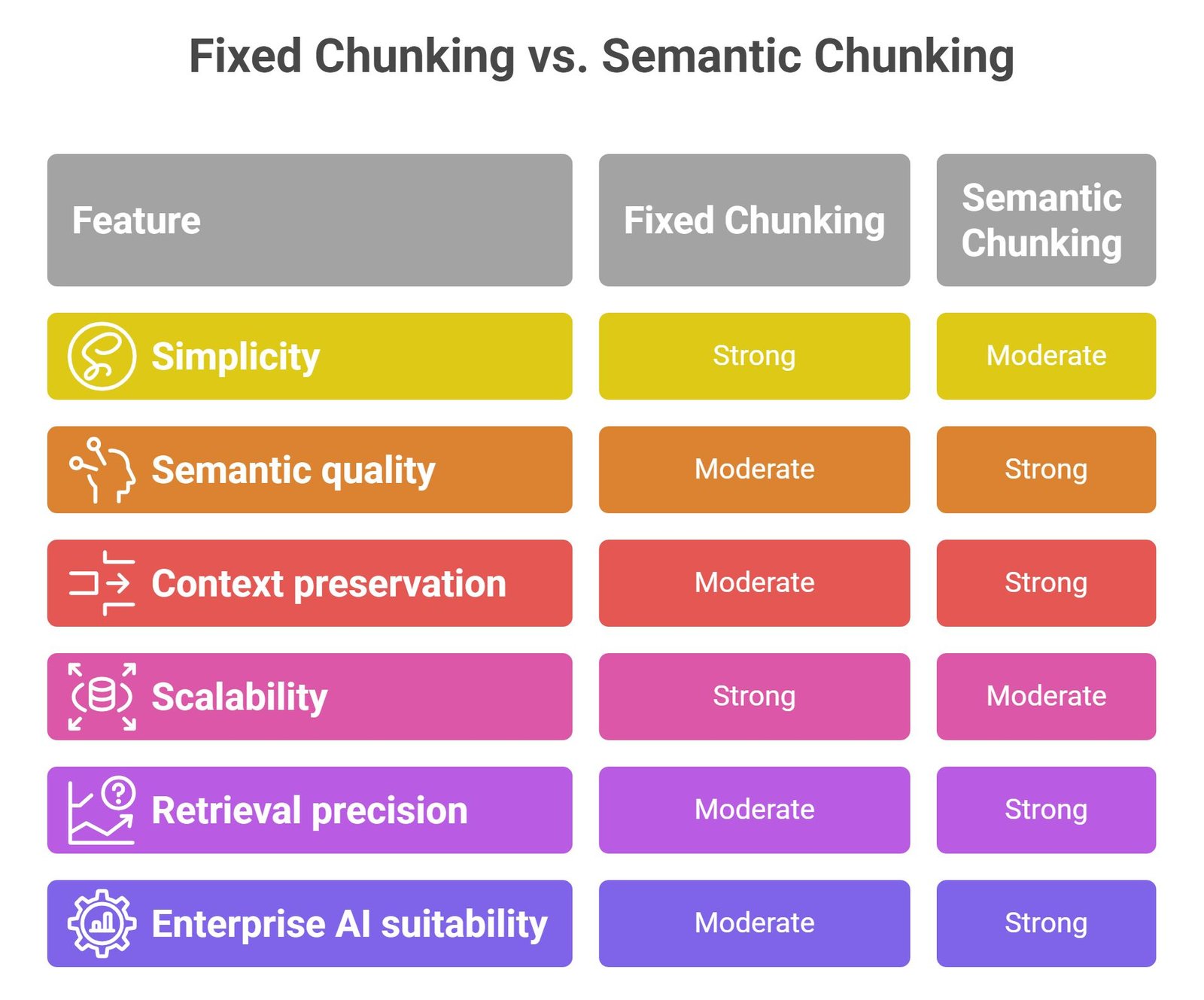
Fixed Chunking vs Semantic Chunking
| Feature | Fixed Chunking | Semantic Chunking |
| Simplicity | Strong | Moderate |
| Semantic quality | Moderate | Strong |
| Context preservation | Moderate | Strong |
| Scalability | Strong | Moderate |
| Retrieval precision | Moderate | Strong |
| Enterprise AI suitability | Moderate | Strong |
Why Chunking Directly Affects Hallucinations
Hallucinations often happen because retrieval quality is weak.
Poor chunking may cause:
- incomplete context retrieval
- fragmented information
- missing semantic relationships
- irrelevant retrieval results
Better chunking improves retrieval grounding.
This helps reduce hallucinations significantly.
Best Chunking Practices for RAG
Modern enterprise systems increasingly follow several chunking best practices.
Preserve Semantic Meaning
Chunks should preserve coherent contextual information.
Avoid splitting important ideas unnaturally.
Use Chunk Overlap Carefully
Overlap improves continuity but excessive overlap increases redundancy.
Optimize for Retrieval Quality
Chunking should improve semantic relevance rather than simply reduce document size.
Match Chunking to Use Cases
Different applications require different chunking strategies.
Examples:
- legal AI
- customer support
- healthcare retrieval
- enterprise search
all benefit from different chunking approaches.
Combine Chunking With Metadata
Metadata-aware chunking improves enterprise retrieval precision.
Real-World Use Cases: Chunking Strategies for RAG
Enterprise Search Systems
Employees retrieve highly specific enterprise knowledge efficiently.
AI Customer Support
Support assistants retrieve troubleshooting workflows more accurately.
Legal AI Systems
Legal assistants retrieve clause-specific information contextually.
Healthcare AI
Medical retrieval systems retrieve clinically relevant guidance more precisely.
Research Assistants
Scientific retrieval systems retrieve semantically relevant research sections.
Ecommerce AI
Shopping assistants retrieve product-specific contextual information.
Common Chunking Challenges
Chunking also introduces several engineering challenges.
Over-Chunking
Chunks that are too small lose contextual meaning.
Under-Chunking
Chunks that are too large reduce retrieval precision.
Scalability Complexity
Advanced semantic chunking requires more processing resources.
Retrieval Redundancy
Chunk overlap may create repetitive retrieval results.
Domain-Specific Optimization
Different industries require different chunking strategies.
Future of Chunking in RAG
Chunking systems are evolving rapidly.
Major trends include:
- AI-generated chunking
- adaptive semantic chunking
- multimodal chunking
- graph-enhanced chunking
- agentic retrieval optimization
- dynamic contextual segmentation
Future enterprise RAG systems will likely rely heavily on intelligent chunk orchestration.
Suggested Read:
- Embeddings for RAG
- Vector Database for RAG
- RAG Pipeline Explained
- Reranking in RAG
- Metadata Filtering in RAG
- Dense Retrieval vs Sparse Retrieval
FAQ: Chunking Strategies for RAG
What is chunking in RAG?
Chunking is the process of splitting large documents into smaller sections for semantic retrieval.
Why is chunking important?
Chunking improves retrieval precision, grounding quality, and semantic relevance.
What is semantic chunking?
Semantic chunking divides documents based on contextual meaning rather than arbitrary token limits.
What is chunk overlap?
Chunk overlap preserves contextual continuity between adjacent chunks.
What is the best chunking strategy for RAG?
The best strategy depends on the use case, but semantic chunking with intelligent overlap is often highly effective.
Final Takeaway
Understanding chunking strategies for RAG is important because chunking directly affects retrieval quality, semantic relevance, grounded AI generation, and enterprise search performance.
Strong chunking strategies help AI systems retrieve more accurate contextual information while improving prompt efficiency and reducing hallucinations.
That capability is transforming how enterprise AI assistants, semantic search systems, document intelligence platforms, and Retrieval-Augmented Generation architectures operate today.