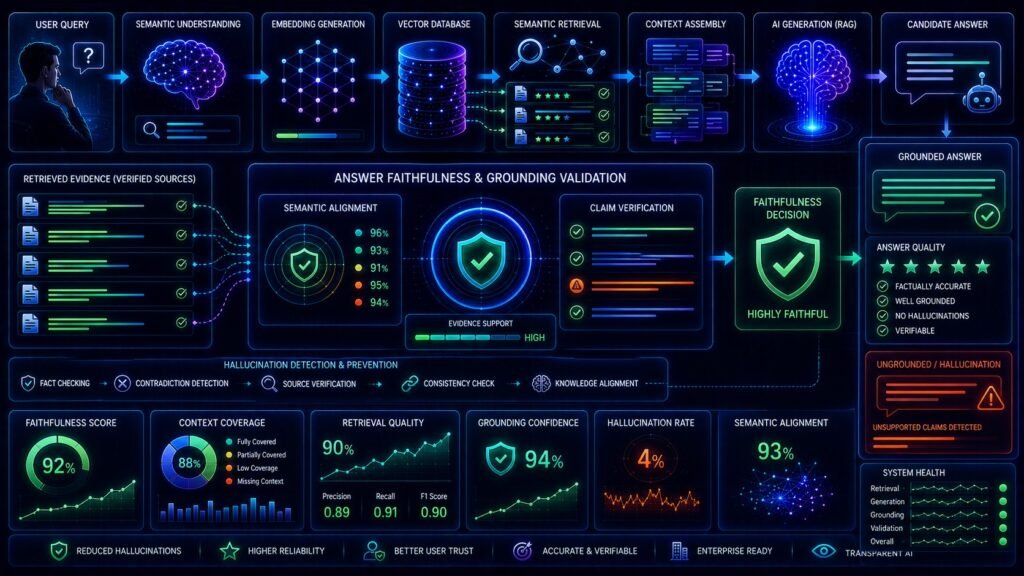
Answer Faithfulness in RAG: How AI Systems Stay Grounded in Facts
Retrieval-Augmented Generation (RAG) systems became one of the most important breakthroughs in modern Artificial Intelligence because they improved how Large Language Models access external knowledge.
Unlike standalone LLMs that rely mostly on pretrained model memory, RAG systems retrieve contextual information from:
- vector databases
- enterprise documents
- semantic search systems
- knowledge bases
- PDFs
- websites
- internal company repositories
before generating answers.
This retrieval layer helps AI systems produce more grounded and reliable responses.
However, retrieval alone does not guarantee factual correctness.
Modern RAG systems still generate:
- hallucinations
- unsupported claims
- misleading answers
- partially grounded responses
- fabricated reasoning
This created a major challenge in enterprise AI systems:
How do you know whether an answer is truly supported by retrieved evidence?
That is exactly why answer faithfulness in RAG became one of the most important evaluation concepts in modern AI engineering.
Answer faithfulness measures whether generated responses remain grounded in the retrieved contextual information.
In simple terms:
Does the answer actually match the retrieved evidence?
This metric became foundational for enterprise AI systems because trustworthy AI depends heavily on grounded generation.
Today, answer faithfulness evaluation is widely used across:
- enterprise AI assistants
- legal AI systems
- healthcare retrieval systems
- customer support copilots
- semantic search systems
- document intelligence platforms
- enterprise knowledge assistants
In this guide, you will learn what answer faithfulness means in RAG systems, why it matters for grounded AI generation, how enterprises evaluate faithfulness, and how organizations reduce hallucinations using better retrieval and grounding systems.
In Simple Terms
What Is Answer Faithfulness in RAG?
Answer faithfulness measures whether an AI-generated response is supported by the retrieved contextual information.
A faithful answer stays grounded in evidence.
An unfaithful answer introduces unsupported claims, fabricated details, or hallucinated reasoning.
Easy Analogy
Imagine a student answering questions using textbook material.
A faithful answer only includes information supported by the textbook.
An unfaithful answer adds assumptions, guesses, or invented facts that never appeared in the source material.
That is exactly how faithfulness works inside RAG systems.
Why Answer Faithfulness Matters
Modern enterprises increasingly deploy AI systems across high-risk environments including:
- healthcare
- legal workflows
- financial systems
- customer support
- compliance operations
In these environments, unsupported AI answers can create major risks.
Even if an answer sounds fluent and convincing, it may still be factually unsupported.
This makes answer faithfulness one of the most important AI trust metrics.
Why RAG Systems Still Produce Unfaithful Answers
Many people incorrectly assume that retrieval automatically eliminates hallucinations.
In reality, Large Language Models still generate text probabilistically.
This means the model may:
- infer unsupported conclusions
- invent missing information
- combine unrelated facts
- misinterpret retrieved context
Even strong retrieval systems cannot fully eliminate these behaviors.
Understanding the Two Layers of RAG
To understand faithfulness deeply, it is important to separate the two major layers of a RAG system.
| RAG Layer | Function |
| Retrieval Layer | Retrieves contextual information |
| Generation Layer | Generates answers using retrieved context |
Faithfulness evaluation primarily focuses on the generation layer.
However, retrieval quality also affects faithfulness significantly.
What Makes an Answer Faithful?
A faithful answer:
- remains grounded in retrieved evidence
- avoids unsupported claims
- accurately reflects source context
- does not invent missing information
- preserves factual alignment
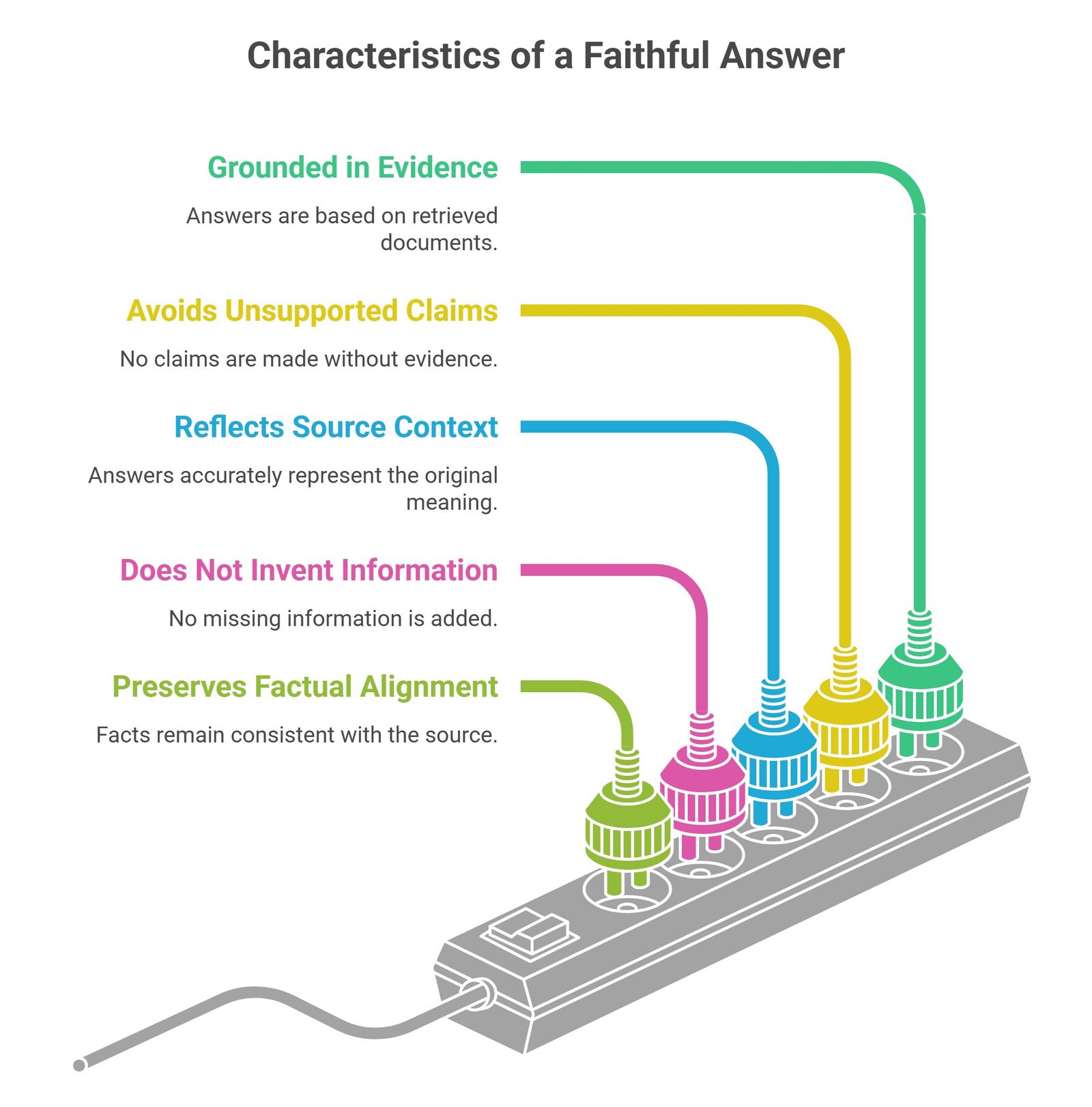
Faithful answers stay connected to retrieved documents.
What Makes an Answer Unfaithful?
An unfaithful answer may:
- add fabricated facts
- infer unsupported conclusions
- exaggerate claims
- hallucinate relationships
- generate speculative reasoning
This creates hallucinations.
Example of Answer Faithfulness in Rag
User Question
“What is the company refund policy?”
Retrieved Context
“The company allows refunds within 30 days for eligible purchases.”
Faithful Answer
“The company allows eligible refunds within 30 days.”
Unfaithful Answer
“The company provides instant refunds globally with no restrictions.”
The second answer introduces unsupported claims.
That is an answer faithfulness failure.
Why Faithfulness Is Critical for Grounded AI
Grounded AI systems depend heavily on factual alignment between:
- retrieved context
- generated responses
Weak faithfulness reduces AI trustworthiness significantly.
How Unfaithful Answers Cause Hallucinations
Hallucinations often happen when generated responses drift away from retrieved evidence.
This may happen because:
- retrieval context is incomplete
- reasoning becomes speculative
- the model fills missing gaps probabilistically
Faithfulness evaluation helps detect these failures.
Retrieval Problems That Affect Faithfulness
Although faithfulness mainly evaluates generation quality, retrieval failures strongly influence groundedness.
Poor Retrieval Quality
Weak retrieval may provide incomplete or irrelevant evidence.
This increases hallucination risk.
Missing Context
If retrieval misses important information, the model may infer unsupported details.
Weak Chunking Strategies
Poor chunking can fragment contextual meaning.
This weakens grounding quality.
Incorrect Chunk Sizes
Very small chunks may lose semantic relationships.
Very large chunks may introduce irrelevant information.
Both problems reduce faithfulness reliability.
Weak Embedding Models
Weak semantic embeddings reduce retrieval precision.
This affects contextual grounding quality.
Query Understanding Failures
Ambiguous user queries often produce weak retrieval grounding.
This increases the probability of unsupported generation.
Why Query Rewriting Helps Faithfulness
Modern RAG systems increasingly use query rewriting to improve retrieval precision and grounding quality.
Better retrieval improves answer faithfulness.
Why Large Language Models Produce Unfaithful Answers
Even with strong retrieval, generation models may still hallucinate.
Probabilistic Text Generation
LLMs predict likely next tokens statistically.
They are not inherently truth-aware.
Overconfident Language Generation
Models prioritize fluent responses.
This sometimes creates convincing but unsupported answers.
Unsupported Reasoning
The model may combine facts incorrectly or infer relationships that were never retrieved.
Multi-Step Reasoning Errors
Complex reasoning tasks increase hallucination risks.
This is especially problematic in enterprise AI systems.
Why Enterprise AI Systems Need Faithfulness Evaluation
Enterprise environments contain highly sensitive workflows.
Organizations increasingly use AI systems for:
- legal analysis
- medical support
- compliance workflows
- enterprise search
- customer support
- financial operations
Unfaithful AI responses create major business risks.
Healthcare AI Systems
Medical hallucinations may create safety risks.
Legal AI Systems
Unsupported legal interpretations may create compliance problems.
Customer Support AI
Hallucinated support guidance damages customer trust.
Enterprise Search Systems
Employees may receive misleading internal information.
Research Assistants
Scientific hallucinations may distort research understanding.
How Enterprises Measure Answer Faithfulness
Modern AI systems increasingly use advanced evaluation frameworks.
These systems compare:
- retrieved evidence
- generated responses
- semantic alignment quality
to determine grounding reliability.
Common Answer Faithfulness in Rag Evaluation Methods
Human Evaluation
Experts manually review whether answers remain supported by retrieved evidence.
This is common in:
- legal AI
- healthcare AI
- financial systems
LLM-as-a-Judge Evaluation
AI evaluator models analyze grounding quality and hallucination risks.
Semantic Similarity Analysis
Embedding systems compare generated answers against retrieved context semantically.
Groundedness Evaluation
Groundedness systems measure how strongly answers remain connected to evidence.
Hallucination Detection Systems
Modern AI observability systems continuously monitor unsupported generation behavior.
Faithfulness vs Answer Relevance
Many people confuse faithfulness and relevance.
However, they evaluate different behaviors.
| Metric | Purpose |
| Faithfulness | Measures grounding in evidence |
| Answer Relevance | Measures whether the answer addresses the question |
An answer can be relevant but still unfaithful.
Example:
A fluent answer may address the question correctly while still adding unsupported claims.
Why Faithfulness Became a Core RAG Metric
Modern AI evaluation increasingly prioritizes:
- grounded generation
- factual correctness
- retrieval alignment
- hallucination reduction
Faithfulness became central because enterprises need trustworthy AI systems.
Best Practices for Improving Answer Faithfulness
Organizations increasingly use multiple optimization strategies together.
Improve Retrieval Quality
Better retrieval improves grounding significantly.
Use Better Embedding Models
Domain-specific embeddings improve semantic retrieval precision.
Optimize Chunking
Semantic chunking preserves contextual meaning more effectively.
Add Query Rewriting
Query rewriting improves retrieval alignment and grounding.
Use Reranking Models
Rerankers prioritize the most relevant contextual evidence.
Add Grounding Validation Systems
Modern enterprises increasingly validate whether generated claims are supported by retrieved evidence.
Use Hallucination Detection Systems
AI observability platforms monitor unsupported generation continuously.
Continuously Evaluate AI Outputs
Enterprise AI systems require ongoing evaluation and benchmarking.
Human-in-the-Loop Validation
Human review remains important for high-risk enterprise workflows.
Future of Answer Faithfulness in RAG
Grounded AI systems are evolving rapidly.
Major trends include:
- reasoning-aware grounding systems
- autonomous hallucination detection
- agentic retrieval validation
- multimodal grounding systems
- real-time faithfulness monitoring
- retrieval-aware reasoning architectures
Future enterprise AI systems will increasingly rely on intelligent grounding infrastructure and continuous observability systems.
Suggested Read:
- Reducing Hallucinations in RAG
- Why RAG Gives Wrong Answers
- How to Evaluate RAG
- RAG Evaluation Metrics
- Context Recall in RAG
- Reranking in RAG
- Query Rewriting for RAG
- Chunking Strategies for RAG
FAQ: Answer Faithfulness in RAG
What is answer faithfulness in RAG?
Answer faithfulness measures whether generated responses are supported by retrieved evidence.
Why is faithfulness important?
Faithfulness reduces hallucinations and improves AI trustworthiness.
What causes unfaithful answers?
Weak retrieval, unsupported reasoning, and probabilistic generation behaviors commonly cause hallucinations.
What is the difference between faithfulness and relevance?
Faithfulness measures grounding in evidence. Relevance measures whether the answer addresses the query.
How do enterprises improve faithfulness?
Organizations improve retrieval quality, chunking, embeddings, reranking, grounding validation, and continuous evaluation.
Final Takeaway
Understanding answer faithfulness in RAG is essential because grounded generation directly affects enterprise AI trustworthiness, hallucination reduction, semantic reliability, and production safety.
Even advanced Retrieval-Augmented Generation systems can produce unsupported answers when retrieval pipelines, chunking strategies, embeddings, grounding mechanisms, or reasoning systems fail.
Organizations that optimize faithfulness can build more reliable, scalable, and trustworthy AI systems.
That capability is becoming foundational for enterprise AI assistants, semantic search systems, healthcare AI platforms, legal retrieval systems, customer support copilots, and intelligent enterprise knowledge architectures across industries.