Context Recall in RAG: How Retrieval Systems Measure Missing Information
Retrieval-Augmented Generation (RAG) systems have become one of the most important architectures in modern Artificial Intelligence. Enterprises increasingly use RAG-powered AI assistants, semantic search systems, enterprise knowledge platforms, customer support copilots, and document intelligence systems to improve AI grounding and reduce hallucinations.
However, retrieval quality remains one of the biggest challenges in enterprise AI systems.
Many organizations focus heavily on:
- embeddings
- vector databases
- Large Language Models
- semantic search pipelines
- chunking systems
while overlooking one of the most important retrieval evaluation metrics:
Context Recall
Even advanced retrieval systems can fail if they miss critical information during retrieval.
This creates a major problem.
The AI system may generate:
- incomplete answers
- partially correct responses
- misleading conclusions
- hallucinations
- unsupported reasoning
not because the knowledge is unavailable, but because retrieval failed to retrieve the necessary context.
This is exactly why context recall in RAG became a foundational metric in modern retrieval evaluation systems.
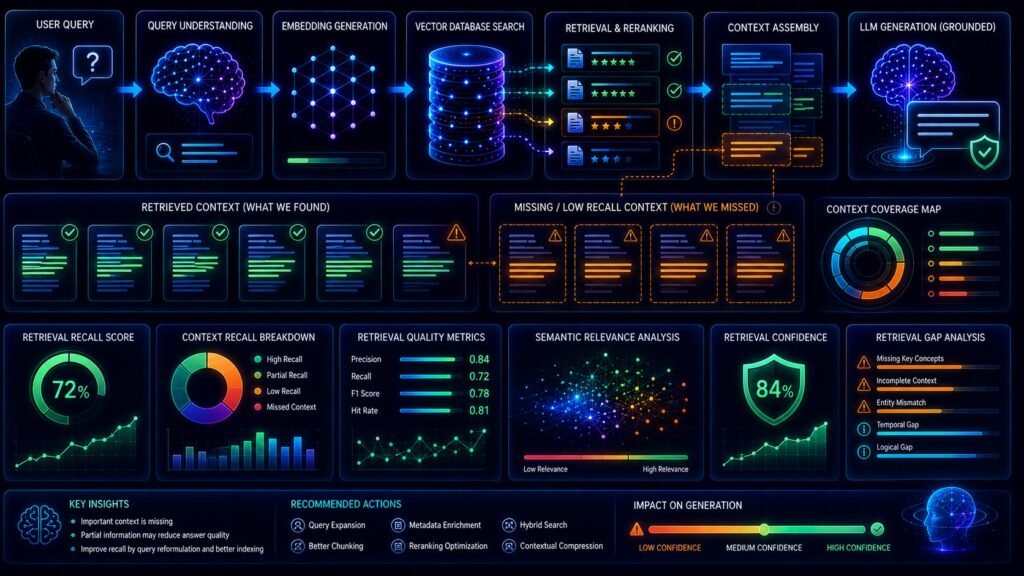
Context recall measures whether the retrieval pipeline successfully retrieved the information required to answer the user’s query correctly.
Today, context recall evaluation is widely used across:
- enterprise AI search
- legal AI systems
- healthcare retrieval systems
- customer support copilots
- AI research assistants
- semantic enterprise search platforms
- document intelligence systems
In this guide, you will learn what context recall means in RAG systems, why it matters for enterprise AI reliability, how it affects hallucinations and grounding, and how organizations improve retrieval recall quality in production AI systems.
In Simple Terms
What Is Context Recall in RAG?
Context recall measures whether the retrieval system successfully retrieved the information needed to answer the user’s question.
If important information exists in the knowledge base but retrieval fails to retrieve it, context recall becomes low.
High context recall means the retriever successfully found most or all of the necessary contextual information.
Easy Analogy
Imagine asking a research assistant to answer a legal question using a library.
The library already contains the correct answer.
However, the assistant only retrieves:
- half the documents
- incomplete pages
- outdated files
Even if the assistant is intelligent, the final answer may still become incomplete or incorrect because critical context was missing.
That is exactly what low context recall looks like inside a RAG system.
Why Context Recall Matters in RAG
Modern RAG systems depend heavily on retrieval quality.
The language model can only generate grounded answers using the context retrieved by the retrieval system.
If retrieval misses important information:
- grounding weakens
- hallucination risk increases
- reasoning quality decreases
- answer completeness declines
This makes context recall one of the most important retrieval evaluation metrics in enterprise AI systems.
Why Retrieval Quality Directly Affects AI Accuracy
Many people incorrectly assume that Large Language Models are the primary source of AI intelligence in RAG systems.
In reality, retrieval quality often determines:
- answer quality
- grounding reliability
- factual correctness
- semantic relevance
- hallucination rates
Even advanced LLMs struggle when critical retrieval context is missing.
Understanding the Retrieval Layer in RAG
Before understanding context recall deeply, it is important to understand how retrieval works in RAG systems.
Modern RAG pipelines typically contain:
- embeddings
- vector databases
- semantic search systems
- reranking models
- chunking systems
- metadata filtering
- query rewriting layers
The retrieval layer searches enterprise knowledge bases for relevant information before generation begins.
How Context Recall Works
Context recall evaluates whether the retriever successfully retrieved the information required for answering a question correctly.
This evaluation usually compares:
| Evaluation Component | Purpose |
| Retrieved Context | Information returned by retrieval |
| Ground Truth Context | Information actually needed |
The system checks how much important information was successfully retrieved.
High Context Recall vs Low Context Recall
| Recall Quality | Meaning |
| High Context Recall | Most critical information retrieved |
| Low Context Recall | Important information missing |
High recall improves grounding and answer completeness.
Low recall increases hallucination risks.
Why Low Context Recall Causes Hallucinations
Hallucinations often happen because retrieval failed to provide sufficient grounding information.
When important context is missing, the language model may:
- infer unsupported conclusions
- fill missing gaps using probabilities
- generate incomplete reasoning
- invent missing details
This creates hallucinations.
Retrieval Problems That Reduce Context Recall
Many retrieval failures reduce recall quality.
Weak Semantic Search
Semantic search systems sometimes fail to capture nuanced meaning.
This often happens when:
- embeddings are weak
- terminology is inconsistent
- queries are ambiguous
Poor semantic understanding reduces retrieval coverage.
Poor Chunking Strategies
Chunking directly affects retrieval recall.
Weak chunking may:
- split workflows incorrectly
- isolate incomplete information
- break semantic continuity
- remove contextual meaning
This increases the chance that important information remains unretrieved.
Incorrect Chunk Sizes
Very small chunks may lose contextual relationships.
Very large chunks may dilute semantic relevance.
Both problems can reduce retrieval recall.
Weak Embedding Models
Embeddings represent semantic meaning numerically.
Weak embedding quality reduces retrieval effectiveness.
This commonly happens when:
- general-purpose embeddings lack domain understanding
- enterprise terminology is complex
- semantic relationships are weak
Query Understanding Failures
Users frequently ask incomplete or vague questions.
Examples include:
- “pricing issue”
- “latest policy”
- “workflow update”
Weak query understanding reduces retrieval quality.
Why Query Rewriting Improves Recall
Modern RAG systems increasingly use query rewriting systems to improve recall quality.
Query rewriting clarifies:
- user intent
- semantic meaning
- domain terminology
This improves contextual retrieval coverage.
Metadata Filtering Problems
Metadata filtering helps narrow retrieval results.
However, overly aggressive filtering may accidentally remove useful documents.
This reduces context recall significantly.
Retrieval Depth Limitations
Many retrieval systems only return a small number of chunks.
If retrieval depth is too low:
- important context may remain hidden
- grounding becomes incomplete
- recall decreases
Increasing retrieval depth often improves recall quality.
Reranking Failures
Reranking systems prioritize the most relevant chunks.
Weak reranking may push important information lower in rankings.
This reduces effective recall.
Context Recall vs Context Precision
Many people confuse recall and precision.
However, they measure different retrieval behaviors.
| Metric | Purpose |
| Context Recall | Measures missing information |
| Context Precision | Measures irrelevant information |
High recall means retrieval finds enough information.
High precision means retrieval avoids irrelevant information.
Strong RAG systems require both.
Why Balancing Recall and Precision Is Difficult
Improving recall often increases retrieval breadth.
However, broader retrieval may introduce:
- irrelevant documents
- retrieval noise
- prompt pollution
This can reduce precision.
Enterprise retrieval systems constantly balance both metrics.
How Enterprises Measure Context Recall
Modern enterprises increasingly use structured retrieval evaluation frameworks.
Evaluation systems compare:
- retrieved chunks
- expected ground truth information
- semantic coverage quality
This helps organizations benchmark retrieval performance.
Common Context Recall Evaluation Methods
Human Evaluation
Experts manually review retrieval quality.
This is common in:
- legal AI
- healthcare AI
- compliance systems
LLM-as-a-Judge Evaluation
AI models evaluate retrieval coverage and contextual completeness.
Benchmark Datasets
Organizations create datasets containing:
- user queries
- reference answers
- required contextual documents
This enables systematic benchmarking.
Retrieval Coverage Analysis
Evaluation systems analyze whether critical semantic concepts were successfully retrieved.
Why Context Recall Is Critical in Enterprise AI
Enterprise AI systems operate in highly complex environments.
Organizations manage:
- massive document repositories
- changing workflows
- fragmented knowledge systems
- inconsistent terminology
- multilingual datasets
Low recall creates serious enterprise risks.
Enterprise Search Systems
Employees may miss critical documents.
This reduces productivity and trust.
Healthcare AI
Medical retrieval systems may miss essential clinical guidance.
This creates safety risks.
Legal AI Systems
Missing legal clauses may create incomplete or inaccurate interpretations.
Customer Support AI
Support assistants may retrieve incomplete troubleshooting workflows.
This creates poor customer experiences.
Research Assistants
Scientific AI systems may miss important papers or citations.
This weakens research quality.
Best Practices for Improving Context Recall
Modern AI teams increasingly optimize retrieval pipelines using multiple techniques.
Improve Semantic Retrieval
Better semantic search improves contextual coverage.
Use Better Embedding Models
Domain-specific embeddings improve semantic understanding significantly.
Optimize Chunking Strategies
Semantic chunking preserves contextual meaning more effectively.
Increase Retrieval Depth
Retrieving more candidate chunks often improves recall quality.
Use Hybrid Search
Combining:
- dense retrieval
- sparse retrieval
improves retrieval coverage.
Add Query Rewriting
Query rewriting improves semantic retrieval quality.
Improve Metadata Systems
Better metadata improves retrieval targeting and coverage.
Use Reranking Carefully
Strong reranking improves retrieval prioritization without harming recall.
Continuously Evaluate Retrieval Quality
Enterprise AI systems require ongoing retrieval evaluation and benchmarking.
Future of Context Recall in RAG
Retrieval systems are evolving rapidly.
Major trends include:
- adaptive retrieval systems
- reasoning-aware retrieval
- agentic search systems
- multimodal retrieval pipelines
- autonomous retrieval orchestration
- retrieval-aware reasoning models
Future enterprise AI systems will increasingly depend on intelligent retrieval optimization and continuous evaluation infrastructure.
Suggested Read:
- How to Evaluate RAG
- RAG Evaluation Metrics
- Chunking Strategies for RAG
- Best Chunk Size for RAG
- Query Rewriting for RAG
- Reranking in RAG
- Hybrid Search in RAG
FAQ: Context Recall in RAG Explained
What is context recall in RAG?
Context recall measures whether the retriever successfully retrieved the information required to answer a query.
Why is context recall important?
Low recall causes missing context, weak grounding, and hallucinations.
What is the difference between recall and precision?
Recall measures missing information. Precision measures irrelevant information.
How can you improve context recall?
Organizations improve embeddings, chunking, retrieval depth, reranking, and query rewriting.
Why does low context recall cause hallucinations?
Missing retrieval context forces the language model to infer unsupported information.
Final Takeaway
Understanding context recall in RAG is essential because retrieval coverage directly affects grounded generation, semantic relevance, hallucination reduction, and enterprise AI reliability.
Even advanced Large Language Models struggle when critical contextual information is missing from retrieval pipelines.
Organizations that optimize context recall can build more reliable, scalable, and trustworthy Retrieval-Augmented Generation systems.
That capability is becoming foundational for enterprise AI assistants, semantic search systems, legal AI platforms, healthcare retrieval systems, document intelligence architectures, and intelligent enterprise knowledge systems across industries.