How to Evaluate RAG System
Moving a Retrieval-Augmented Generation pipeline from a local prototype into a high-stakes production environment requires a systematic approach to validation. Implementing a rigorous framework for evaluating rag system performance is the only way to prevent silent data regressions and runaway model improvisations.
In this guide, we break down how to design modern, automated rag evaluation pipelines that stress-test your architecture from query to final generation. Whether you are figuring out how to evaluate rag agents managing complex multi-turn conversations or building an end-to-end rag evaluation workflow to trace document chunk ingestion, establishing clear rag quality metrics ensures your enterprise system operates with absolute factual dependability.
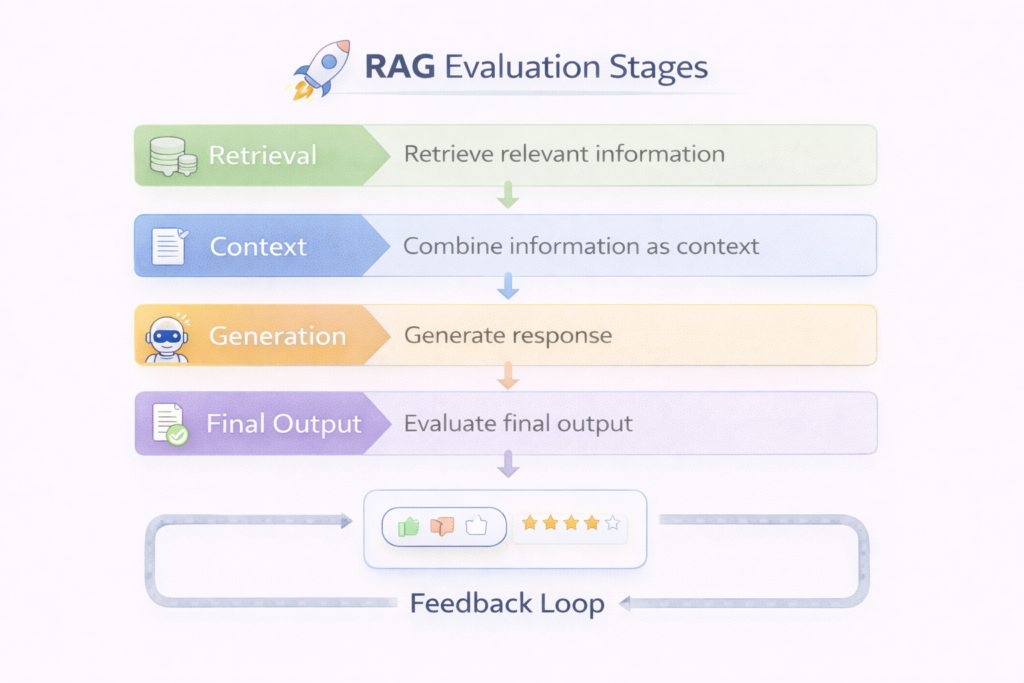
Evaluating a RAG (Retrieval-Augmented Generation) system is different from evaluating a standard LLM. You are not just measuring how good the model is—you are measuring how well retrieval and generation work together.
A strong RAG system depends on two things:
- retrieving the right information
- generating accurate answers from it
If either fails, the system fails. That is why RAG evaluation must be multi-layered.
In simple terms
Once your offline test sets are established, deploying dedicated rag evaluation tools like TruLens or DeepEval allows you to attach continuous feedback functions directly to individual execution spans. This real-time rag monitoring stack ensures that as production queries shift over time, your engineering team receives automated alerts the moment live system quality marks dip below your target thresholds, providing a clear blueprint for continuous rag pipeline evaluation.
RAG evaluation answers three questions:
- Did the system retrieve the right data?
- Did the model use that data correctly?
- Did the final answer solve the user’s problem?
You need to evaluate all three.
Automating Your Pipeline: Ragas Evaluation Metrics for RAG
Manually spot-checking input-output pairs does not scale. Modern engineering teams build programmatic validation layers using specialized open-source libraries. When establishing your testing harness, deploying ragas evaluation metrics for rag implementations allows you to compute reference-free data quality scores between 0 and 1 using an LLM-as-a-Judge architecture.
To isolate whether a system failure stems from poor search indexing or poor linguistic generation, your continuous integration environment must track the foundational dimensions of rag quality evaluation:
-
Faithfulness: Decomposes the generated response into individual claims to verify if every single statement is factually grounded in the retrieved chunks. A low faithfulness score signals model hallucination.
-
Answer Relevancy: Measures whether the generated text actually addresses the user’s initial question, penalizing responses that are technically truthful but off-topic.
-
Context Precision: Evaluates rag retrieval evaluation quality by checking whether the most relevant information chunks are ranked at the top of the vector database return set.
-
Context Recall: Determines whether the retriever successfully extracted all necessary context required to construct the ground-truth target response.
Incorporating these specific ragas rag evaluation metrics into your testing suite transforms subjective output checks into a deterministic data tracking framework, serving as a core component of any automated rag evaluation framework.
Why RAG evaluation is harder than LLM evaluation
RAG adds complexity because:
- retrieval can fail silently
- good answers may come from wrong context
- bad answers may come from good context
- multiple components affect output
This makes evaluation a system-level problem, not just a model problem.
The 3 Layers of RAG Evaluation
1. Retrieval evaluation
This measures how well your system finds relevant documents.
Key metrics
- Recall@K → Did relevant documents appear in top results?
- Precision@K → How many retrieved documents are relevant?
- MRR (Mean Reciprocal Rank) → How early the correct result appears
Example
User query:
“What is prompt engineering?”
Good retrieval:
Top results contain accurate explanations
Bad retrieval:
Irrelevant or loosely related documents
2. Context evaluation
This checks whether retrieved data is actually useful for answering.
What to evaluate
- relevance of chunks
- completeness of context
- noise (irrelevant information)
Key issue
Even if retrieval is correct, poor chunking or irrelevant sections can reduce answer quality.
3. Generation evaluation
This measures how well the LLM uses the retrieved context.
Key metrics
- answer correctness
- faithfulness (no hallucination)
- completeness
- clarity
Example
Good output:
- uses retrieved facts correctly
Bad output:
- ignores context or invents facts
Key RAG Evaluation Metrics
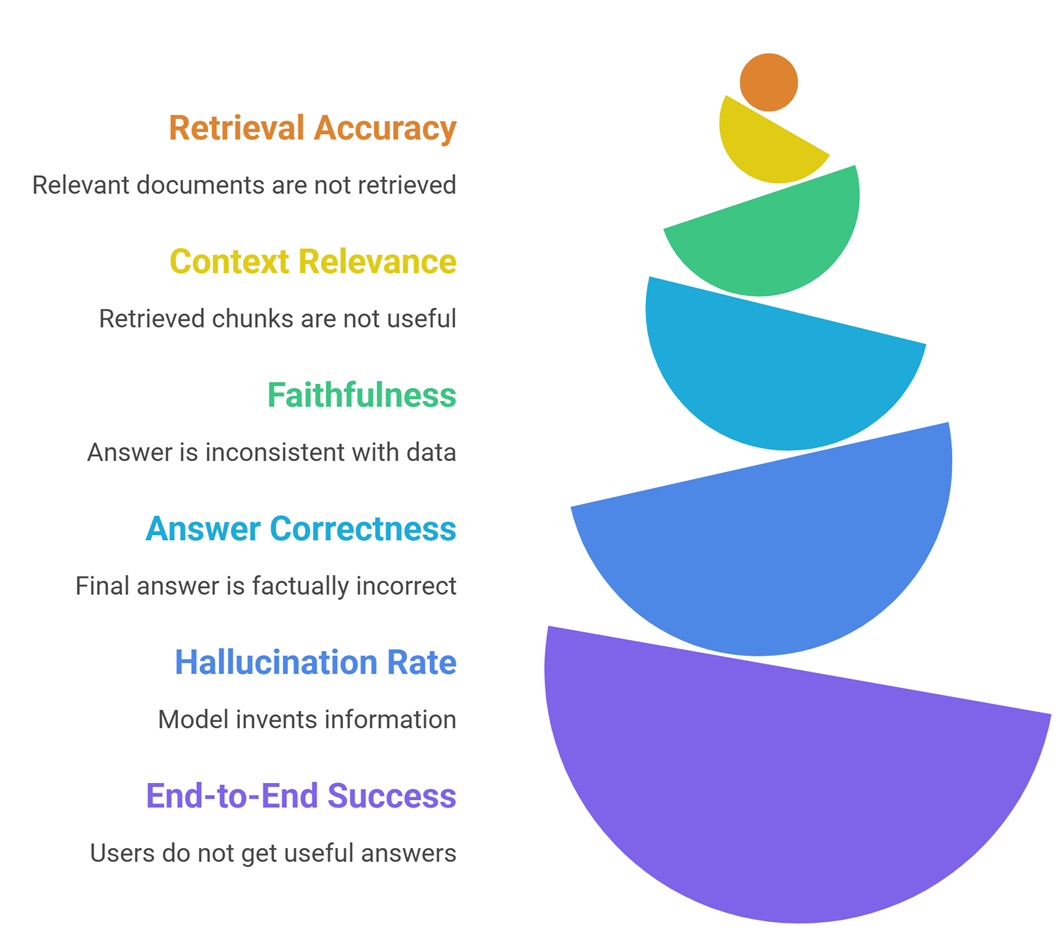
1. Retrieval accuracy
Measures how often relevant documents are retrieved.
2. Context relevance
Measures how useful retrieved chunks are.
3. Faithfulness (groundedness)
Measures whether the answer stays consistent with retrieved data.
4. Answer correctness
Checks if the final answer is factually correct.
5. Hallucination rate
Tracks how often the model invents information.
6. End-to-end success rate
Measures whether users get useful answers.
Evaluate RAG Systems (Comparison Table)
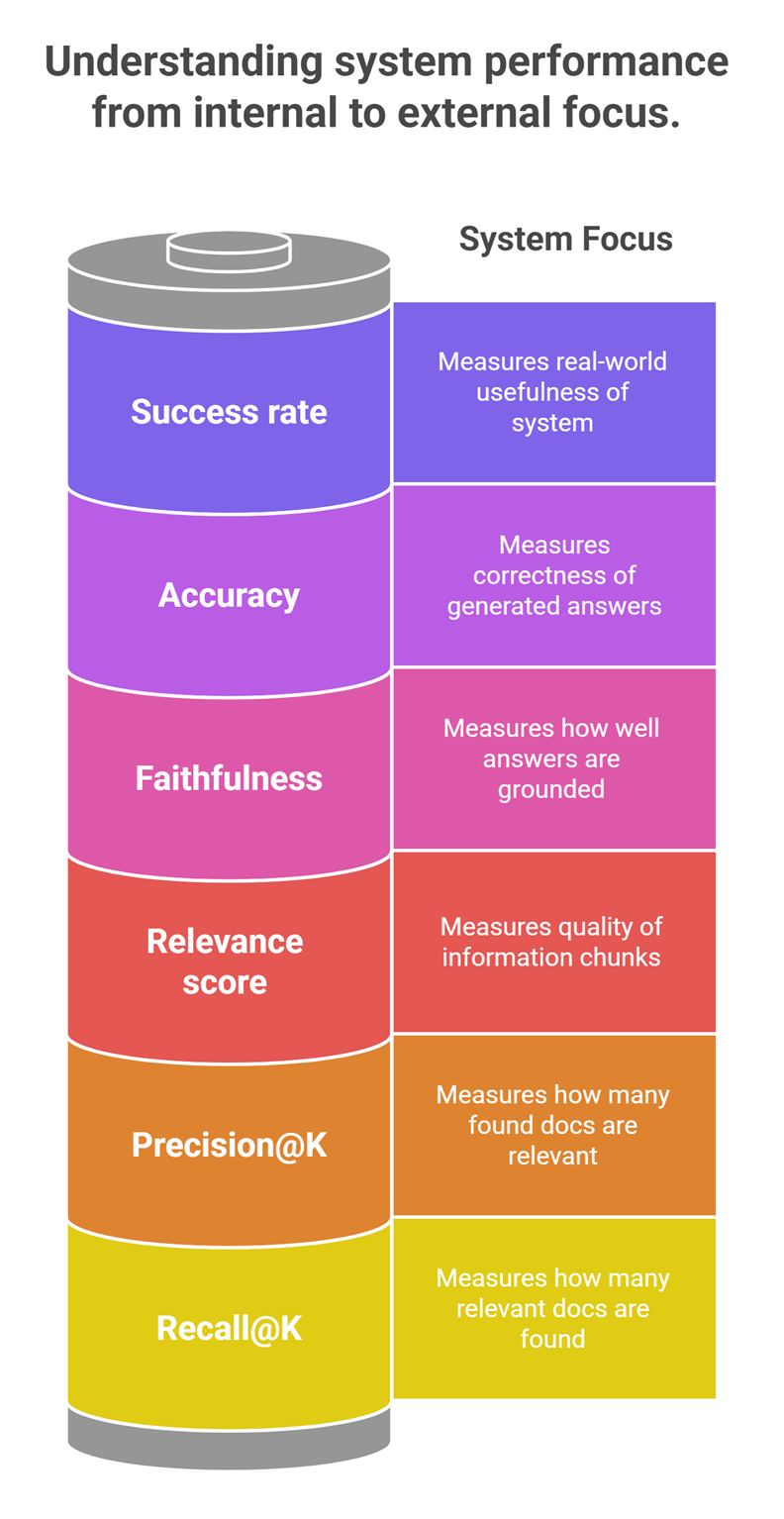
| Layer | Metric | What it measures |
| Retrieval | Recall@K | Coverage of relevant docs |
| Retrieval | Precision@K | Relevance of results |
| Context | Relevance score | Quality of chunks |
| Generation | Faithfulness | Grounded answers |
| Generation | Accuracy | Correctness |
| System | Success rate | Real-world usefulness |
How to evaluate a RAG system step-by-step
Step 1: Create a test dataset
Build a dataset of:
- queries
- expected answers
- relevant documents
This is your evaluation baseline.
Step 2: Evaluate retrieval
Check:
- are relevant documents retrieved?
- how high do they rank?
Use metrics like Recall@K and MRR.
Step 3: Evaluate context quality
Inspect retrieved chunks:
- are they relevant?
- are they too long or too short?
- is important information missing?
Step 4: Evaluate generation
Check outputs for:
- correctness
- hallucination
- clarity
You can use:
- automated scoring
- human evaluation
Step 5: Run end-to-end testing
Test the full system:
- does it answer real user queries well?
- does it fail gracefully?
Step 6: Iterate and improve
Improve:
- chunking strategy
- embedding model
- retrieval method
- prompt structure
Evaluation is not one-time—it is continuous.
Tools for RAG evaluation
Common tools include:
- RAGAS (automated RAG evaluation)
- LangChain evaluation tools
- OpenAI eval frameworks
- custom evaluation pipelines
These tools help automate scoring and testing.
Real-world evaluation strategy
Most production systems use:
- offline evaluation (metrics)
- human review (quality)
- online testing (user feedback)
This layered approach ensures reliability.
Advanced Frontiers: How to Evaluate RAG Agents & Technical Documentation
As architectures move away from single-hop semantic searches toward autonomous execution, understanding how to evaluate rag systems becomes significantly more complex. Modern agentic systems dynamically choose between multiple vector indices, rewrite user queries, or decide whether to trigger loops for additional context.
Executing Agentic Trajectory Analysis
To properly manage a rag performance evaluation over multi-turn agents, teams rely on scenario-based conversational simulation. Evaluation pipelines must trace the agent’s complete decision-making path, measuring whether it maintains topical coherence across an entire dialogue and successfully pulls accurate references as the context evolves.
Evaluating Retrieval Accuracy for Technical Documentation
A distinct failure mode emerges when evaluating rag retrieval accuracy for technical documentation. Specialized code repositories, hardware manuals, and legal texts use dense, domain-specific terminology that standard embedding models often misinterpret.
When assembling a rag evaluation checklist for technical text corpora, you must measure if retrieval helps in rag system evaluation metrics by running comparative A/B tests on your chunking layouts. Tracking Precision@K and Mean Reciprocal Rank (MRR) across various chunk sizes and overlap thresholds prevents your retriever from burying critical engineering specifications under irrelevant context blocks, protecting downstream logic from systemic processing failures.
Common mistakes
- evaluating only the LLM
- ignoring retrieval quality
- using small or biased datasets
- not testing real queries
- over-relying on automatic metrics
Many systems fail because they optimize the wrong layer.
Suggested Read:
- What Is RAG in AI? A Beginner-Friendly Guide
- How RAG Systems Work in Practice
- Best Chunking Strategies for RAG
- RAG vs Fine-Tuning: Which One Should You Use?
- Why LLMs Hallucinate and How to Reduce It
FAQ: How to Evaluate RAG Systems
What is the most important metric in RAG?
There is no single metric. Retrieval + generation must both be evaluated.
Can RAG be evaluated automatically?
Partially. Human evaluation is still important.
Why is faithfulness important?
Because correct-looking answers can still be wrong.
How often should RAG systems be evaluated?
Continuously, especially when data changes.
Final takeaway
Evaluating a RAG system is about measuring the full pipeline, not just the model. Retrieval, context, and generation must all work together.
If you want a reliable RAG system, focus on evaluation early—and treat it as an ongoing process, not a one-time test.