Why RAG Gives Wrong Answers: Understanding Retrieval Failures in AI Systems
Retrieval-Augmented Generation (RAG) systems became popular because they promised a major improvement over standalone Large Language Models.
Instead of relying only on model memory, RAG systems retrieve external information from:
- enterprise documents
- vector databases
- knowledge bases
- semantic search systems
- PDFs
- websites
- internal company repositories
before generating answers.
This retrieval layer helps reduce hallucinations and improves grounding.
However, despite these advantages, modern RAG systems still frequently produce:
- incorrect answers
- hallucinations
- misleading outputs
- incomplete responses
- outdated information
- irrelevant answers
This creates an important question:
Why does RAG still give wrong answers?
Many people incorrectly assume that adding retrieval automatically guarantees factual correctness.
In reality, Retrieval-Augmented Generation systems are highly complex AI architectures with multiple potential failure points.
A RAG system can fail because of:
- poor retrieval quality
- weak chunking
- bad embeddings
- retrieval noise
- query failures
- hallucinations
- grounding issues
- reranking problems
- outdated knowledge sources
Understanding these failure patterns is essential for building reliable enterprise AI systems.
Today, organizations increasingly use RAG architectures across:
- enterprise AI assistants
- customer support copilots
- legal AI systems
- healthcare retrieval platforms
- ecommerce AI assistants
- research copilots
- document intelligence systems
This makes RAG reliability one of the most important challenges in modern AI engineering.
In this guide, you will learn why RAG systems produce wrong answers, the most common retrieval failures, and how enterprises reduce hallucinations in production AI systems.
In Simple Terms
Why Does RAG Give Wrong Answers?
RAG systems give wrong answers when:
- retrieval fails
- irrelevant documents are retrieved
- important information is missing
- hallucinations occur during generation
- semantic search misunderstands user intent
Even though RAG improves grounding, the AI still depends heavily on retrieval quality.
Weak retrieval often creates weak answers.
Easy Analogy
Imagine asking a research assistant a question.
The assistant first searches through a library for relevant information.
Now imagine:
- the assistant retrieves the wrong books
- misses critical pages
- uses outdated documents
- misunderstands your question
Even if the assistant is intelligent, the final answer may still be incorrect.
That is exactly how RAG failures happen.
Why RAG Is More Complex Than Traditional AI Systems
Many beginners think RAG systems are simply:
“LLMs with document search.”
In reality, modern RAG pipelines contain multiple independent systems working together.
These include:
- embeddings
- vector databases
- chunking systems
- semantic retrieval
- reranking pipelines
- metadata filtering
- query rewriting
- grounding mechanisms
- generation models
Each layer introduces additional complexity and potential failure points.
This means RAG systems can fail in many different ways.
The Two Major Failure Areas in RAG
Most RAG failures happen in one of two major layers.
| RAG Layer | Main Risk |
| Retrieval Layer | Wrong or missing information |
| Generation Layer | Hallucinations and unsupported answers |
Understanding this distinction is critical for debugging RAG systems.
Retrieval Failures in RAG Systems
Retrieval problems are one of the most common causes of incorrect AI answers.
Poor Retrieval Quality
The retrieval system may fail to find the most relevant documents.
This often happens because:
- embeddings are weak
- semantic similarity is poor
- chunking quality is weak
- vector search is inaccurate
If retrieval quality fails, the AI receives weak grounding context.
Irrelevant Retrieval Results
Sometimes retrieval systems return semantically similar but contextually irrelevant chunks.
Example:
A query about:
“refund policy”
may retrieve:
- reimbursement workflows
- payment disputes
- financial reports
instead of the exact refund policy document.
This creates retrieval noise.
Missing Critical Context
The retriever may fail to retrieve important contextual information.
This often happens when:
- chunk sizes are poor
- retrieval depth is weak
- query wording is ambiguous
Incomplete retrieval frequently causes partially correct answers.
Weak Chunking Strategies
Chunking directly affects retrieval quality.
Poor chunking may:
- split workflows incorrectly
- break semantic continuity
- isolate incomplete information
- remove contextual meaning
Weak chunks create weak retrieval grounding.
Incorrect Chunk Sizes
Very small chunks may lose context.
Very large chunks may introduce retrieval noise.
Finding the right chunk size is critical.
Embedding Failures
Embeddings are numerical representations of semantic meaning.
Weak embedding quality can reduce retrieval precision significantly.
This happens when:
- embedding models are outdated
- domain terminology is poorly represented
- semantic similarity breaks down
Enterprise AI systems often require domain-specific embeddings.
Vector Database Retrieval Failures
Vector search systems may retrieve low-quality matches.
This may happen because of:
- poor indexing
- retrieval configuration issues
- low similarity thresholds
- scalability problems
Retrieval quality directly affects AI answer quality.
Query Understanding Failures
Users often ask vague or incomplete questions.
Example:
- “pricing issue”
- “latest workflow”
- “policy update”
The retrieval system may misunderstand the intended meaning.
This leads to weak semantic retrieval.
Why Query Rewriting Matters
Modern RAG systems increasingly use query rewriting systems to improve retrieval quality.
Without query optimization:
- semantic ambiguity increases
- retrieval precision decreases
- hallucination risk grows
Outdated Knowledge Sources
RAG systems only retrieve information from indexed data sources.
If documents are outdated:
- AI answers become outdated
- compliance risks increase
- operational accuracy decreases
This is a major enterprise challenge.
Metadata Filtering Problems
Metadata filtering helps narrow retrieval results.
Weak metadata systems may retrieve:
- wrong departments
- outdated policies
- unauthorized documents
- irrelevant contextual information
This weakens enterprise retrieval reliability.
Reranking Failures
Many RAG systems use reranking models after retrieval.
Rerankers prioritize the most relevant chunks.
If reranking quality is weak:
- irrelevant chunks may dominate
- important documents may be ignored
This affects final answer quality significantly.
Hallucinations in the Generation Layer
Even with strong retrieval, Large Language Models may still hallucinate.
What Is a Hallucination?
A hallucination occurs when the AI generates unsupported or fabricated information.
This can happen even when retrieval quality is strong.
Why Hallucinations Still Happen in RAG
RAG reduces hallucinations but does not eliminate them completely.
The language model still performs probabilistic text generation.
This means the model may:
- infer unsupported conclusions
- invent missing details
- combine unrelated information incorrectly
Weak Grounding
Grounding means staying connected to retrieved evidence.
Weak grounding occurs when the model ignores retrieved context partially or completely.
Overconfident Generation
LLMs are designed to generate fluent responses.
Sometimes the model prioritizes linguistic confidence over factual correctness.
This creates convincing but inaccurate answers.
Multi-Step Reasoning Failures
Complex reasoning tasks are difficult for RAG systems.
The model may:
- connect facts incorrectly
- perform weak logical reasoning
- misunderstand relationships between retrieved documents
This becomes especially problematic in enterprise AI systems.
Why Enterprise RAG Systems Struggle
Enterprise AI environments are extremely complex.
Organizations manage:
- massive document repositories
- changing workflows
- inconsistent terminology
- fragmented knowledge bases
- multilingual datasets
This creates major retrieval challenges.
Enterprise Documents Are Often Messy
Real enterprise data frequently contains:
- duplicate documents
- outdated information
- inconsistent formatting
- incomplete metadata
- conflicting policies
RAG systems struggle when enterprise knowledge quality is weak.
Domain-Specific Terminology Challenges
Industries like:
- healthcare
- legal
- finance
- engineering
contain highly specialized terminology.
General embedding models may fail to capture domain-specific meaning accurately.
Access Control Complexity
Enterprise systems often require permission-aware retrieval.
If access filtering fails:
- wrong documents may appear
- sensitive data may leak
- retrieval precision may decrease
Common Examples of RAG Failures
Customer Support AI
The system retrieves outdated support workflows.
The AI gives incorrect troubleshooting guidance.
Legal AI Systems
The retriever misses relevant clauses.
The AI generates incomplete legal interpretations.
Healthcare AI
Medical retrieval systems retrieve partially relevant clinical guidance.
The AI generates risky recommendations.
Enterprise Search Systems
Employees receive irrelevant internal documentation.
This reduces productivity and trust.
Ecommerce AI
Shopping assistants retrieve incorrect product specifications.
The AI generates misleading recommendations.
Research Assistants
Scientific AI systems retrieve unrelated research papers.
The generated summaries become inaccurate.
How Enterprises Reduce RAG Errors
Modern AI teams use several techniques to improve RAG reliability.
Better Chunking Strategies
Improved semantic chunking enhances retrieval quality.
Hybrid Search Systems
Combining dense and sparse retrieval improves precision.
Query Rewriting
Query rewriting improves semantic retrieval quality.
Metadata Filtering
Better metadata improves retrieval targeting.
Reranking Models
Rerankers help prioritize the best contextual information.
Better Embedding Models
Domain-specific embeddings improve semantic understanding.
Continuous Evaluation
Organizations continuously benchmark:
- faithfulness
- groundedness
- retrieval precision
- hallucination rates
Human-in-the-Loop Systems
Human review remains important for high-stakes AI applications.
Why RAG Evaluation Is Critical
RAG systems require continuous monitoring and benchmarking.
Modern enterprises increasingly evaluate:
- retrieval quality
- hallucination rates
- semantic relevance
- answer grounding
- enterprise trustworthiness
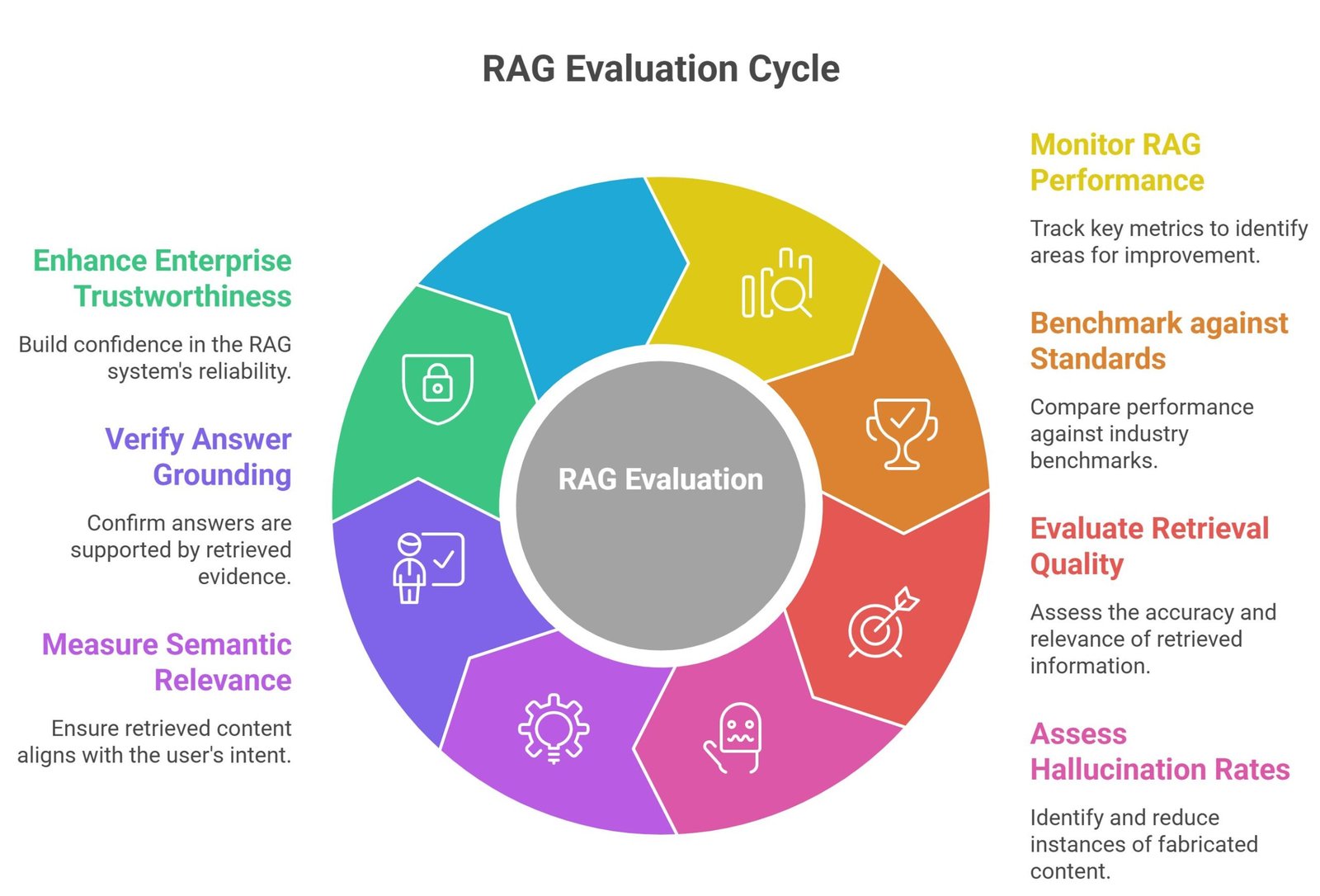
Evaluation frameworks became essential for production AI systems.
Future of RAG Reliability
RAG systems are evolving rapidly.
Major trends include:
- agentic retrieval systems
- reasoning-aware retrieval
- adaptive semantic search
- autonomous query rewriting
- multimodal retrieval
- grounded reasoning systems
- real-time evaluation frameworks
Future enterprise AI systems will increasingly rely on intelligent retrieval orchestration and continuous evaluation infrastructure.
Suggested Read:
- How to Evaluate RAG
- RAG Evaluation Metrics
- Chunking Strategies for RAG
- Best Chunk Size for RAG
- Query Rewriting for RAG
- Reranking in RAG
- Hybrid Search in RAG
- Dense Retrieval vs Sparse Retrieval
FAQ: Why RAG Gives Wrong Answers
Why does RAG give wrong answers?
RAG systems fail when retrieval quality is weak or hallucinations occur during generation.
Can RAG completely eliminate hallucinations?
No. RAG reduces hallucinations but cannot eliminate them entirely.
What causes retrieval failures in RAG?
Common causes include weak embeddings, poor chunking, retrieval noise, and ambiguous queries.
Why is chunking important in RAG?
Chunking affects retrieval precision and contextual grounding.
How do enterprises reduce RAG hallucinations?
Organizations improve chunking, retrieval systems, reranking, query rewriting, and continuous evaluation.
Final Takeaway
Understanding why RAG gives wrong answers is essential because retrieval quality directly affects AI reliability, grounded generation, semantic relevance, and enterprise trustworthiness.
Although Retrieval-Augmented Generation significantly improves AI grounding, modern RAG systems still face complex challenges across retrieval, chunking, embeddings, semantic search, reranking, and hallucination control.
Organizations that understand these failure patterns can build more reliable, scalable, and trustworthy enterprise AI systems.
That capability is becoming foundational for customer support AI, enterprise search systems, legal AI platforms, healthcare retrieval systems, semantic search engines, and intelligent document assistants across industries.