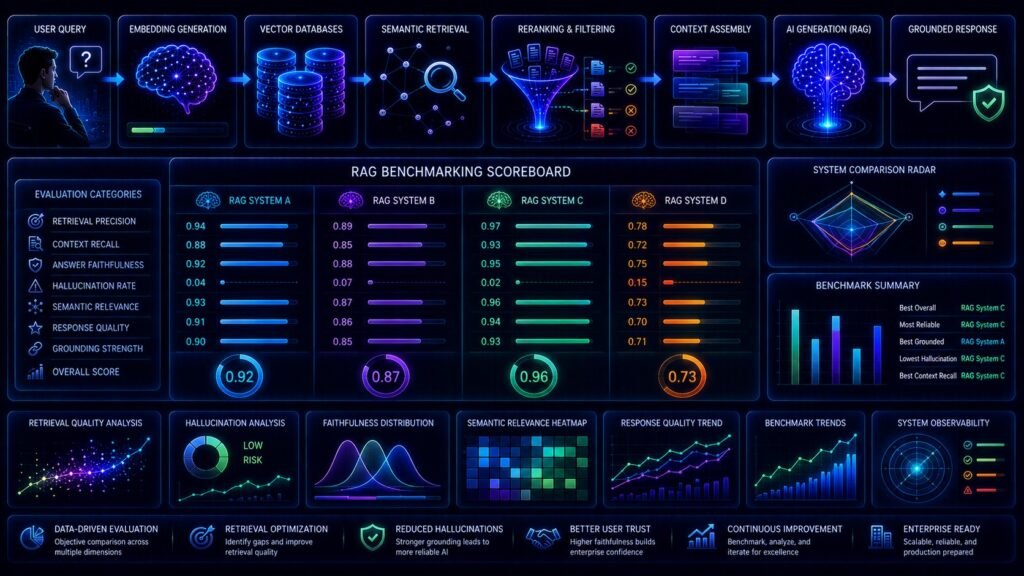
RAG Benchmark Basics: How AI Systems Are Evaluated and Compared
Retrieval-Augmented Generation (RAG) systems have become one of the most important architectures in modern Artificial Intelligence. Enterprises increasingly use RAG-powered AI assistants, semantic search systems, customer support copilots, enterprise knowledge platforms, and intelligent document retrieval systems to improve AI grounding and reduce hallucinations.
However, building a RAG pipeline is only one part of the challenge.
Organizations also need to answer a much more important question:
How do you know whether a RAG system is actually good?
Modern RAG systems contain multiple moving parts including:
- embeddings
- vector databases
- semantic search systems
- reranking pipelines
- chunking systems
- query rewriting layers
- Large Language Models
Each component affects overall AI quality.
This creates a major enterprise challenge:
How do you systematically evaluate and compare RAG systems?
That is exactly why RAG benchmarking became a foundational discipline in modern AI engineering.
RAG benchmarks help organizations measure:
- retrieval quality
- grounding reliability
- hallucination rates
- semantic relevance
- answer faithfulness
- latency
- enterprise reliability
Benchmarking enables enterprises to compare AI systems consistently and improve production performance over time.
Today, RAG benchmarking frameworks are widely used across:
- enterprise AI assistants
- healthcare AI systems
- legal AI platforms
- financial AI systems
- customer support copilots
- semantic search architectures
- research assistant systems
In this guide, you will learn the basics of RAG benchmarking, the most important benchmarking metrics, how enterprises evaluate retrieval systems, and why benchmarking became essential for grounded AI systems.
In Simple Terms
What Is a RAG Benchmark?
A RAG benchmark is a structured evaluation process used to measure how well a Retrieval-Augmented Generation system performs.
Benchmarking helps determine whether a RAG system can:
- retrieve relevant information
- generate grounded responses
- reduce hallucinations
- answer accurately
- maintain contextual relevance
Benchmarks allow organizations to compare different AI systems consistently.
Easy Analogy
Imagine testing different search engines.
You might compare them based on:
- accuracy
- relevance
- speed
- reliability
RAG benchmarks work similarly.
They evaluate how well AI retrieval systems perform across different tasks and scenarios.
Why RAG Benchmarking Matters
Modern enterprises increasingly depend on AI systems for critical workflows including:
- legal research
- healthcare assistance
- customer support
- enterprise search
- compliance analysis
- document intelligence
Weak AI systems create serious risks including:
- hallucinations
- inaccurate answers
- retrieval failures
- operational mistakes
- compliance problems
Benchmarking helps organizations detect these weaknesses systematically.
Why Evaluation and Benchmarking Are Different
Many people confuse evaluation and benchmarking.
Although related, they are not identical.
| Concept | Purpose |
| Evaluation | Measures system quality |
| Benchmarking | Compares systems consistently |
Evaluation focuses on measuring performance.
Benchmarking focuses on standardized comparison.
Understanding the Two Core Layers of RAG
Modern RAG systems contain two major architectural layers.
| RAG Layer | Function |
| Retrieval Layer | Retrieves contextual information |
| Generation Layer | Generates answers using retrieved context |
Both layers require independent benchmarking.
This distinction is one of the most important concepts in enterprise AI evaluation.
Why Benchmarking Retrieval Matters
Weak retrieval creates weak grounding.
Even advanced Large Language Models struggle when retrieval quality is poor.
Retrieval benchmarking helps organizations measure:
- semantic retrieval quality
- contextual relevance
- retrieval coverage
- retrieval precision
- retrieval recall
Why Benchmarking Generation Matters
Even strong retrieval systems may still produce hallucinations.
Generation benchmarking evaluates:
- groundedness
- faithfulness
- semantic relevance
- hallucination behavior
- answer quality
Core Metrics Used in RAG Benchmarks
Modern benchmarking frameworks evaluate several major categories.
Retrieval Precision
Retrieval precision measures how much retrieved information is actually relevant.
Low precision introduces retrieval noise.
Context Recall
Context recall measures whether retrieval successfully captured the information needed to answer the query.
Low recall creates missing contextual grounding.
Answer Faithfulness
Faithfulness measures whether generated responses remain supported by retrieved evidence.
This is one of the most important grounded AI metrics.
Answer Relevance
Answer relevance measures whether the generated response actually addresses the user’s question.
Hallucination Detection
Hallucination benchmarks measure whether the model generates unsupported or fabricated information.
Groundedness
Groundedness measures how strongly generated answers remain connected to retrieved evidence.
Latency Metrics
Enterprise systems also benchmark:
- retrieval speed
- response latency
- token usage
- infrastructure efficiency
Why Hallucination Benchmarks Became Important
One of the main goals of RAG systems is reducing hallucinations.
However, hallucinations still happen because of:
- retrieval failures
- weak grounding
- incomplete context
- unsupported reasoning
Benchmarking helps organizations measure hallucination risks systematically.
Common RAG Benchmarking Frameworks
Several benchmarking frameworks became popular in modern AI engineering.
RAGAS
RAGAS evaluates:
- faithfulness
- context recall
- context precision
- answer relevance
It became one of the most widely used RAG benchmarking frameworks.
DeepEval
DeepEval supports advanced LLM evaluation and benchmarking workflows.
TruLens
TruLens focuses heavily on groundedness and observability analysis.
LangSmith
LangSmith helps benchmark and monitor complex LLM pipelines.
Human Evaluation Frameworks
Many enterprises still rely heavily on human review for high-risk systems.
Why Human Benchmarking Still Matters
Automated benchmarks are powerful but imperfect.
Human reviewers better evaluate:
- nuanced reasoning
- compliance accuracy
- business correctness
- contextual interpretation
- domain-specific validity
This is especially important in:
- healthcare AI
- legal AI
- finance AI
How Benchmark Datasets Work
Benchmark datasets are foundational for evaluation systems.
These datasets usually contain:
- user questions
- expected answers
- reference documents
- contextual ground truth
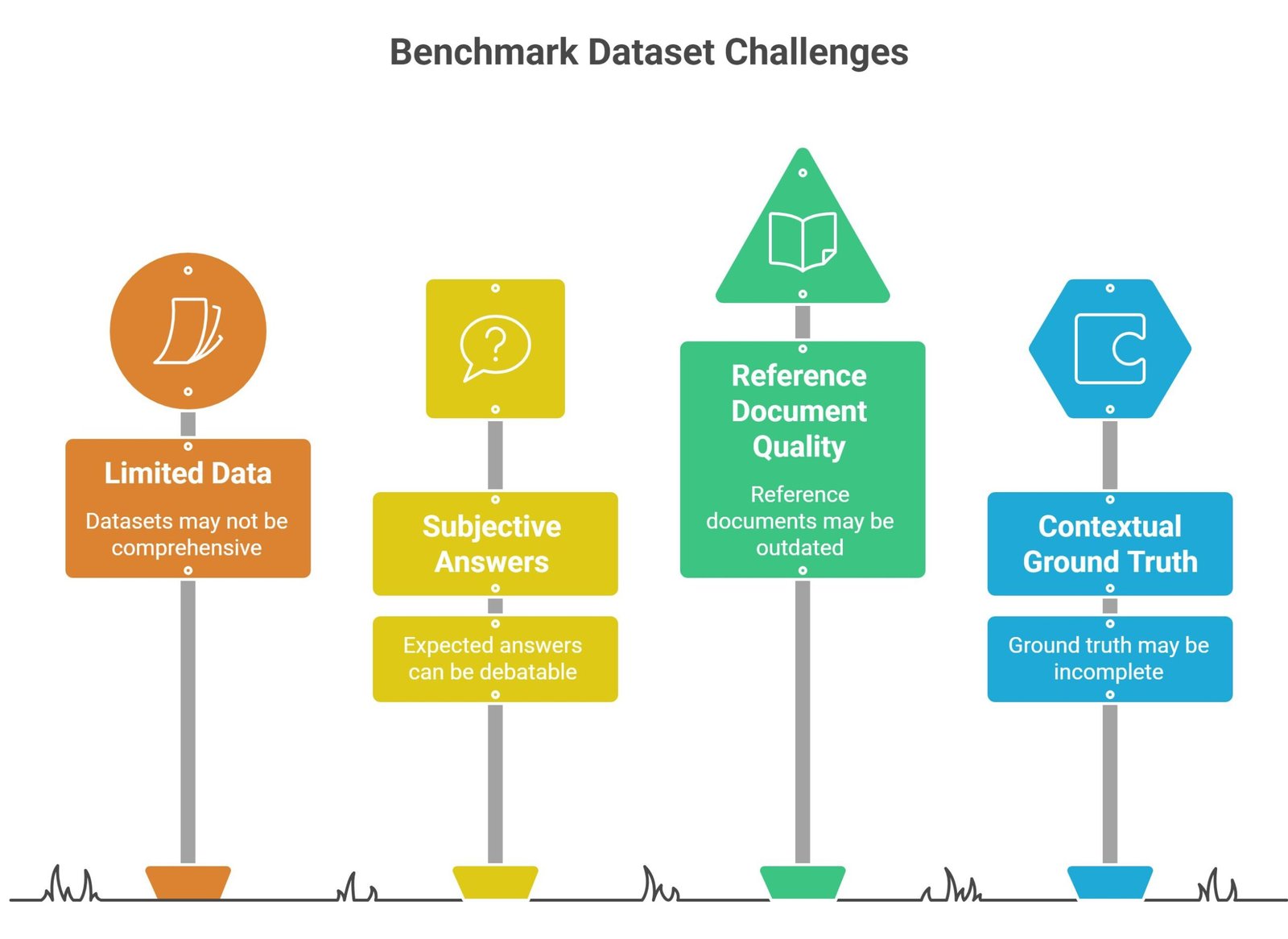
The benchmark compares AI outputs against these reference standards.
Why Real Enterprise Queries Matter
Synthetic datasets alone are often insufficient.
Real enterprise environments contain:
- ambiguous queries
- inconsistent terminology
- fragmented knowledge systems
- complex workflows
Good benchmarks include realistic enterprise use cases.
Common Benchmarking Challenges in RAG
RAG benchmarking remains difficult for several reasons.
Dynamic Enterprise Data
Enterprise knowledge changes constantly.
Benchmarks must stay updated.
Subjective Answer Quality
Different evaluators may score responses differently.
Retrieval and Generation Interdependence
Weak retrieval often creates weak generation quality.
Separating failures is difficult.
Multi-Step Reasoning Complexity
Complex reasoning tasks are difficult to benchmark accurately.
Hallucination Detection Challenges
Subtle hallucinations can be difficult to identify automatically.
Why Enterprise AI Systems Need Continuous Benchmarking
Benchmarking is not a one-time process.
Enterprise AI systems continuously evolve because:
- documents change
- workflows evolve
- embeddings improve
- retrieval systems update
- models change over time
Continuous benchmarking helps maintain AI reliability.
Enterprise Search Systems
Organizations benchmark retrieval relevance and contextual grounding.
Customer Support AI
Support copilots benchmark hallucination rates and response quality.
Healthcare AI Systems
Medical systems benchmark groundedness and factual accuracy.
Legal AI Systems
Legal assistants benchmark citation grounding and contextual precision.
Ecommerce AI
Shopping assistants benchmark semantic relevance and recommendation quality.
Research Assistants
Scientific AI systems benchmark citation accuracy and retrieval quality.
Best Practices for RAG Benchmarking Basics
Modern enterprises increasingly follow several benchmarking best practices.
Separate Retrieval and Generation Evaluation
Evaluate both layers independently.
Use Multiple Metrics Together
No single metric captures complete AI quality.
Continuously Benchmark Production Systems
Enterprise AI systems require ongoing evaluation.
Include Real Enterprise Workflows
Real-world testing improves reliability.
Combine Human and Automated Evaluation
Hybrid benchmarking improves consistency.
Benchmark Hallucination Risks
Groundedness and faithfulness evaluation are critical.
Why Benchmarking Directly Improves AI Reliability
Strong benchmarking helps organizations:
- improve retrieval quality
- reduce hallucinations
- optimize grounding
- compare models consistently
- improve enterprise trustworthiness
This makes benchmarking foundational for production AI systems.
Future of RAG Benchmarking
RAG benchmarking systems are evolving rapidly.
Major trends include:
- reasoning-aware evaluation
- multimodal benchmarking
- autonomous evaluation agents
- real-time observability systems
- agentic retrieval evaluation
- personalized AI benchmarking
Future enterprise AI systems will increasingly rely on intelligent continuous benchmarking infrastructure.
Suggested Read:
- RAG Evaluation Metrics
- How to Evaluate RAG
- Answer Faithfulness in RAG
- Context Recall in RAG
- Retrieval Precision in RAG
- Reducing Hallucinations in RAG
- Query Rewriting for RAG
- Reranking in RAG
FAQ: RAG Benchmark Basics
What is a RAG benchmark?
A RAG benchmark is a structured framework used to evaluate and compare Retrieval-Augmented Generation systems.
Why is RAG benchmarking important?
Benchmarking helps organizations measure retrieval quality, groundedness, hallucinations, and AI reliability.
What metrics are used in RAG benchmarks?
Common metrics include retrieval precision, context recall, faithfulness, groundedness, and answer relevance.
Why do enterprises benchmark RAG systems?
Organizations benchmark AI systems to improve reliability, reduce hallucinations, and optimize enterprise performance.
What is the difference between evaluation and benchmarking?
Evaluation measures quality. Benchmarking compares systems consistently using standardized tests.
Final Takeaway
Understanding RAG benchmark basics is essential because benchmarking directly affects grounded AI quality, hallucination reduction, retrieval reliability, and enterprise AI trustworthiness.
Even advanced Retrieval-Augmented Generation systems require continuous evaluation across retrieval quality, semantic relevance, grounded generation, contextual precision, and hallucination control.
Organizations that build strong benchmarking systems can create more reliable, scalable, and trustworthy enterprise AI architectures.
That capability is becoming foundational for enterprise AI assistants, semantic search systems, healthcare AI platforms, legal retrieval systems, customer support copilots, and intelligent document intelligence systems across industries.