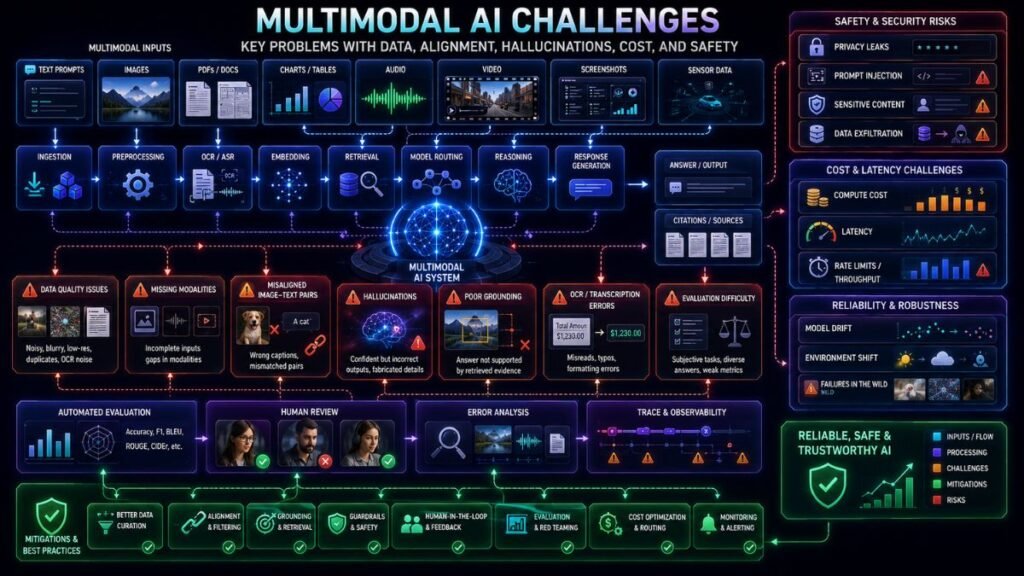
Multimodal AI Challenges: Key Problems With Data, Alignment, Hallucinations, Cost, and Safety
Multimodal AI challenges come from combining different data types such as text, images, audio, video, PDFs, charts, and sensor data. The hardest problems include data alignment, noisy inputs, hallucinations, weak grounding, expensive inference, difficult evaluation, privacy risks, security attacks, and unreliable performance on messy real-world files.
In Simple Terms
Multimodal AI is powerful because it can work with more than one kind of information. But that also makes it harder to build and trust.
A text-only model mostly deals with words. A multimodal AI system may need to read text, inspect images, understand audio, sample video frames, parse documents, and connect all of those signals correctly. Every extra modality adds another possible failure point.
What Are Multimodal AI Challenges?
Multimodal AI challenges are the technical, operational, and safety problems that appear when AI systems combine multiple data formats. These problems affect training, retrieval, inference, evaluation, deployment, and user trust.
A vision-language model may describe an image well but fail on small OCR text. A document AI system may read a page but lose table structure. A video model may understand individual frames but miss the sequence of events. These are not small edge cases; they are core issues when multimodal AI moves from demos to production.
1. Data Quality Is Harder Across Modalities
Data quality is one of the biggest multimodal AI challenges. Text, images, audio, video, and documents all have different noise patterns. Images can be blurry. Audio can include background noise. PDFs can have complex layouts. Videos can be long and redundant. Captions may not describe the image accurately.
This creates a serious problem for training and evaluation. If an image caption is wrong, the model may learn the wrong relationship. If a document parser loses table structure, a RAG system may retrieve misleading context. Large web-scale multimodal datasets can also contain noisy, duplicated, biased, or sensitive content.
2. Alignment Between Modalities Is Difficult
Multimodal alignment means connecting the right parts of one modality with the right parts of another. For example, the model must connect a sentence with the correct image region, an audio segment with the right video frame, or a table value with its correct label.
Alignment and fusion are long-standing multimodal learning problems. A recent survey on multimodal alignment and fusion describes the field as focused on integrating diverse data types such as text, images, audio, and video through generalizable alignment and fusion techniques.
Poor alignment causes confusing outputs. A model may answer from the wrong chart, describe the wrong object, or connect a user’s question to the wrong part of a screenshot.
3. Multimodal Hallucinations Are Hard to Detect
Multimodal hallucination happens when a model claims something about an image, document, chart, video, or audio clip that is not actually supported by the input. A model might say an object is present when it is not, invent chart values, misread a label, or describe a document section that does not exist.
A survey on hallucination in multimodal large language models describes this as a major issue in large vision-language models, where models can produce unsupported visual or cross-modal claims. Hallucinations are especially risky because multimodal answers often sound confident even when the visual evidence is weak.
4. Evaluation Is More Complex Than Text-Only Testing
Evaluating a text answer is already hard. Evaluating a multimodal answer is harder because the system may fail in several places: OCR, image recognition, retrieval, grounding, reasoning, or final generation.
A good multimodal evaluation setup should test visual grounding, OCR accuracy, chart interpretation, retrieval relevance, answer faithfulness, latency, and user usefulness. Public benchmarks help, but production teams still need custom tests with real screenshots, PDFs, images, videos, and noisy files.
This is why multimodal evaluation and multimodal benchmarking should be treated as core development work, not optional cleanup.
5. Missing or Noisy Modalities Break Reliability
Real-world multimodal inputs are often incomplete. A user may upload a blurry screenshot without context. A video may lack audio. A scanned PDF may have missing pages. A product image may not show the relevant label.
A robust multimodal AI system should handle missing or weak inputs gracefully. Instead of guessing, it should say what it can verify, ask for a clearer file, or route the case to a human. This is especially important in healthcare, finance, insurance, legal, and customer support workflows.
6. Cost and Latency Increase Quickly
Multimodal AI often costs more than text-only AI because images, audio, video, and documents require extra processing. A system may need OCR, image encoders, audio transcription, video frame sampling, embeddings, reranking, and a large multimodal model.
Latency also becomes harder to control. A simple text answer may be fast, but a multimodal workflow involving a PDF, images, retrieval, and reasoning can take much longer. Teams need preprocessing, caching, model routing, smaller specialist models, and careful context selection to keep the app usable.
7. Privacy Risks Are Larger
Multimodal AI systems often process sensitive information: faces, voices, medical scans, customer screenshots, contracts, invoices, identity documents, location clues, and workplace recordings.
This makes privacy more complicated than text-only workflows. A screenshot may expose personal data. A voice clip may identify a speaker. A medical image may contain protected health information. Teams need consent, access controls, data retention rules, encryption, audit logs, and careful vendor review before deploying multimodal AI in real workflows.
8. Security Risks Include Prompt Injection Through Images
Multimodal AI also expands the attack surface. Malicious instructions can be hidden in documents, images, screenshots, or web pages. OWASP defines prompt injection as a vulnerability where user prompts alter the LLM’s behavior or output in unintended ways, and notes that these inputs do not need to be human-visible if the model can parse them.
Research in Nature Communications showed that vision-language models used in medical contexts could be compromised by prompt injection attacks embedded in visual inputs. This matters for multimodal agents because an image or document could influence tool use, data access, or workflow actions if guardrails are weak.
9. Interpretability and Trust Are Still Limited
It is often hard to know why a multimodal model produced a specific answer. Did it rely on the image, the OCR text, the caption, retrieved context, or its internal prior knowledge?
This lack of transparency makes debugging difficult. Teams need traces, evidence display, citations, visual grounding, confidence scores, and human review. The goal is not perfect interpretability, but enough visibility to diagnose and reduce failure.
Common Mistakes to Avoid
The biggest mistake is assuming that adding more modalities automatically improves accuracy. More input can help, but it can also add noise.
Another mistake is using one large model for everything. Production systems often work better when they combine specialist OCR, document parsing, retrieval, vision models, and smaller routing models.
A third mistake is skipping evaluation. Multimodal systems should be tested on messy real-world files, not only polished demos.
How Teams Can Reduce Multimodal AI Challenges
Teams can reduce risk by starting with a narrow use case, using high-quality data, preserving metadata, evaluating each pipeline stage, and adding human review for sensitive workflows.
They should also design for uncertainty. If the model cannot verify an answer from the image, page, chart, or audio segment, it should say so. Strong multimodal systems are not the ones that always answer. They are the ones that know when the evidence is not enough.
Suggested Read:
- What Is Multimodal AI? Simple Explanation With Examples
- Multimodal Evaluation
- Multimodal Benchmarking
- Building Multimodal Apps
- Multimodal AI Datasets
- Multimodal RAG Explained
- Image Grounding in AI
- Multimodal Agents Use Cases
FAQ: Multimodal AI Challenges Explained Clearly
What are the main multimodal AI challenges?
The main challenges include data quality, modality alignment, hallucinations, weak grounding, evaluation difficulty, latency, cost, privacy, security, and deployment reliability.
Why is multimodal AI hard to build?
It is hard because each modality has different formats, noise patterns, preprocessing needs, context limits, and failure modes.
What are the limitations of multimodal AI?
Current systems can misread images, miss small text, misunderstand charts, hallucinate visual details, fail on noisy data, and struggle with complex reasoning.
Why do multimodal AI models hallucinate?
They may rely on learned patterns instead of verified visual evidence, misalign modalities, retrieve weak context, or generate answers that are not grounded in the input.
How do you evaluate multimodal AI systems?
Evaluate OCR, visual grounding, retrieval relevance, answer faithfulness, latency, cost, privacy, and performance on real-world edge cases.
What are the privacy risks of multimodal AI?
Privacy risks include exposure of faces, voices, medical data, identity documents, screenshots, financial records, and confidential business files.
Final Takeaway
Multimodal AI challenges are not only research problems. They affect real products, workflows, and users. Data quality, alignment, hallucinations, evaluation, latency, privacy, security, and human oversight all matter when AI systems process text, images, audio, video, and documents together.
To continue learning, read Multimodal Evaluation, Multimodal Benchmarking, and Building Multimodal Apps next.