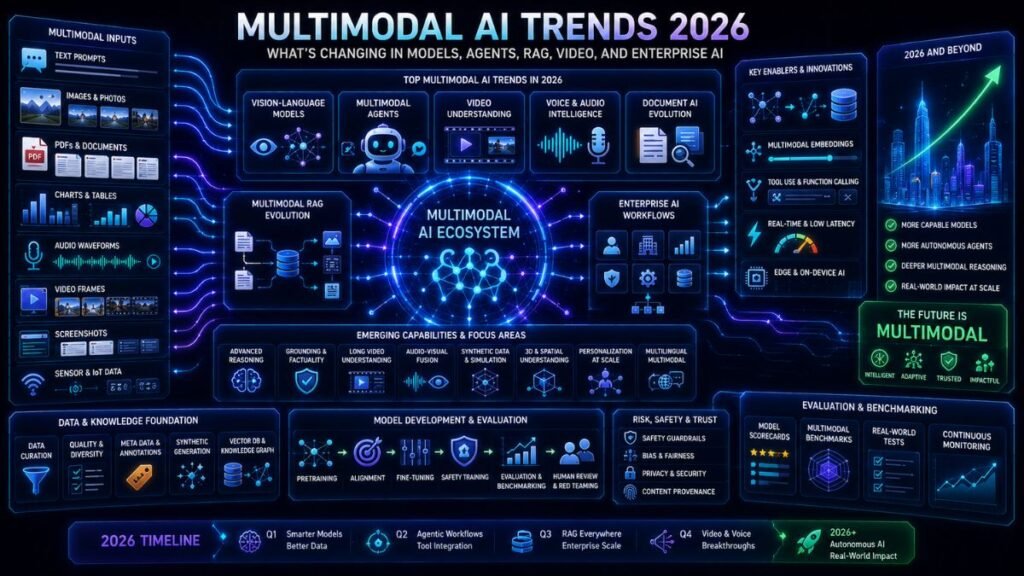
Multimodal AI Trends 2026: What’s Changing in Models, Agents, RAG, Video, and Enterprise AI
Multimodal AI trends 2026 are moving beyond simple image upload features. The biggest shifts are multimodal agents, stronger vision-language models, video and audio reasoning, multimodal RAG, unified embeddings, document intelligence, enterprise automation, better evaluation, and stronger safety controls for synthetic and sensitive media.
In Simple Terms
Multimodal AI means AI that works with more than text. It can understand or generate across images, audio, video, documents, charts, screenshots, and structured data.
In 2026, the important change is that multimodal AI is becoming part of real workflows. It is not only “upload an image and ask a question.” It is becoming the foundation for visual search, document automation, voice agents, video understanding, customer support, research assistants, and enterprise copilots.
Trend 1: Multimodal Models Are Becoming the Default
One of the biggest multimodal AI trends in 2026 is that major AI models are no longer text-only by default. Users and developers increasingly expect models to handle images, screenshots, documents, voice, and sometimes video.
OpenAI’s API model documentation says its latest models support text and image input, text output, multilingual capabilities, and vision. Google’s Gemini API documentation says Gemini can understand and combine language, images, audio, video, and code.
This changes product expectations. A chatbot that cannot inspect a screenshot, read a document, or understand a visual prompt may feel limited compared with newer multimodal systems.
Trend 2: Vision-Language Models Are Moving Into Real Workflows
Vision-language models, or VLMs, connect visual input with language reasoning. They can inspect screenshots, answer image questions, describe charts, read document pages, and explain visual context.
In 2026, VLMs are moving from demos into customer support, ecommerce, education, healthcare support workflows, research, and internal business tools. The practical trend is not just better image captioning. It is visual reasoning inside workflows: “What does this screenshot show?” “Which part of this chart supports the claim?” “What is wrong with this invoice?”
This creates demand for better grounding, OCR, chart reasoning, and evaluation.
Trend 3: Multimodal RAG Is Becoming More Practical
Traditional RAG retrieves text before an AI model answers. Multimodal RAG retrieves multiple evidence types: text chunks, images, PDF pages, charts, tables, screenshots, audio transcripts, or video frames.
Google’s Gemini API File Search documentation says File Search imports, chunks, indexes, and retrieves data for RAG. Its 2026 changelog adds multimodal search support for images through Gemini Embedding 2, with grounding metadata such as media IDs and page numbers.
This is a major trend because enterprise knowledge is not text-only. Important information often lives in slide decks, scanned PDFs, charts, diagrams, product photos, videos, and screenshots.
Trend 4: Multimodal Embeddings Will Power Search and Discovery
Multimodal embeddings map different data types into one shared vector space. This means a system can compare text, images, video, audio, and documents by meaning.
Google’s Gemini Embedding 2 documentation describes it as mapping text, images, video, audio, and PDFs into a unified embedding space for cross-modal semantic search, document retrieval, and recommendation systems.
This trend matters for visual search, media search, ecommerce discovery, document retrieval, research search, and enterprise knowledge systems. Instead of searching only by keywords, users can search with an image, a document, a phrase, or a mixed query.
Trend 5: Multimodal Agents Will Combine Perception and Action
AI agents are becoming more useful when they can see, hear, read, retrieve, and act. A multimodal agent can inspect a screenshot, listen to a voice request, read a PDF, retrieve policy context, and update a workflow system.
The 2026 trend is not “agents that chat.” It is agents that use multimodal context to complete tasks. Examples include customer support agents that analyze screenshots, finance agents that process invoices, field-service agents that use photos and voice notes, and accessibility agents that convert visual content into speech.
The key challenge is safety. Agents that can take actions need permissions, logs, human review, and clear handoff rules.
Trend 6: Video and Audio AI Will Become More Useful
Video and audio are becoming more important because many workflows contain meetings, tutorials, calls, lectures, demos, inspections, and surveillance-style business footage.
OpenAI’s realtime documentation and model listings show continued investment in voice and audio workflows, including realtime voice interaction and speech models. Google’s Gemini documentation also highlights multimodal work across audio and video.
The practical trend is time-aware understanding. Good video AI needs transcripts, frame sampling, timestamps, scene changes, and retrieval. Good audio AI needs transcription, speaker awareness, tone context, and reliable summarization.
Trend 7: Document AI Will Merge With Multimodal RAG
Document AI is becoming a core part of multimodal AI. Businesses need systems that understand PDFs, invoices, forms, receipts, contracts, scanned pages, tables, signatures, and charts.
In 2026, the trend is moving from simple OCR to document understanding plus retrieval. A strong document AI system should preserve layout, metadata, tables, page references, and visual context before sending content into RAG or an AI agent.
This matters for finance, legal, healthcare administration, insurance, procurement, compliance, and research workflows.
Trend 8: Evaluation and Benchmarking Will Become a Competitive Advantage
As multimodal AI becomes more common, quality testing becomes harder. A model may answer text questions well but fail on charts, OCR, screenshots, document tables, or video timestamps.
This makes multimodal evaluation and multimodal benchmarking major 2026 trends. Teams will need to test visual grounding, OCR accuracy, retrieval relevance, answer faithfulness, latency, cost, safety, and real user edge cases.
The companies that evaluate multimodal systems properly will build more reliable products than teams that rely only on demos and leaderboard scores.
Trend 9: Synthetic Media Provenance Will Matter More
As multimodal AI generates and edits images, audio, and video, content authenticity becomes more important. Users and platforms need ways to understand whether media is real, edited, generated, or provenance-tagged.
This trend affects journalism, education, elections, marketing, legal evidence, platform moderation, and enterprise communications. Provenance, watermarking, metadata, and detection workflows will become part of responsible multimodal AI strategy.
For businesses, the message is simple: do not only ask what AI can create. Ask how the source, edits, rights, and usage can be verified.
Trend 10: Privacy and Security Risks Will Grow
Multimodal AI handles sensitive inputs: faces, voices, medical images, financial documents, screenshots, contracts, IDs, call recordings, and internal dashboards.
This expands risk. Prompt injection can hide inside documents or screenshots. Voice systems can capture sensitive speech. Image uploads may expose personal data. Agent workflows may take actions based on misread visual information.
In 2026, serious multimodal AI adoption will require privacy policies, access controls, redaction, audit logs, secure storage, human review, and model-risk evaluation.
What These Trends Mean for Developers
Developers should learn multimodal APIs, file ingestion, OCR, transcription, embeddings, vector databases, RAG, tool calling, structured outputs, and evaluation.
The best projects will not be simple API wrappers. Strong multimodal apps will show architecture: preprocessing, retrieval, model routing, evidence display, monitoring, and failure handling.
A good 2026 portfolio project could be a screenshot support assistant, multimodal document RAG app, visual search engine, video summarizer, accessibility assistant, or multimodal agent.
What These Trends Mean for Businesses
Businesses should focus on workflows where multimodal AI solves a real bottleneck. Examples include support tickets with screenshots, invoice processing, product visual search, document review, meeting summaries, field reports, and training video search.
The best approach is to start narrow. Pick one workflow, collect real examples, test models, measure accuracy, and add human review before scaling.
Suggested Read:
- What Is Multimodal AI? Simple Explanation With Examples
- Multimodal AI Challenges
- Multimodal RAG Explained
- Multimodal Agents Use Cases
- Building Multimodal Apps
- Multimodal API Comparison
- Multimodal Benchmarking
- Multimodal AI Datasets
FAQ: Multimodal AI Trends 2026
What are the top multimodal AI trends in 2026?
Top trends include stronger VLMs, multimodal agents, multimodal RAG, unified embeddings, video/audio reasoning, document AI, synthetic media provenance, and better evaluation.
How is multimodal AI changing in 2026?
It is moving from simple image understanding into real workflows involving documents, video, audio, search, agents, automation, and enterprise systems.
Why are multimodal agents important in 2026?
They combine perception and action. They can read documents, inspect images, process voice, retrieve context, use tools, and hand off to humans.
What is the future of multimodal RAG?
Multimodal RAG will retrieve not only text, but also images, charts, PDF pages, video frames, audio transcripts, and structured metadata.
What multimodal AI trends should developers watch?
Developers should watch multimodal APIs, embeddings, file search, video understanding, voice agents, document AI, evaluation tools, and agent frameworks.
What are the risks of multimodal AI in 2026?
Risks include hallucinations, weak visual grounding, privacy exposure, prompt injection, deepfake misuse, high cost, latency, and unsafe agent actions.
Final Takeaway
Multimodal AI trends 2026 point toward AI systems that can see, hear, read, search, reason, and act across real-world data. The biggest opportunities are multimodal agents, document AI, visual search, video/audio understanding, multimodal RAG, and enterprise automation.
To continue learning, read Multimodal RAG Explained, Multimodal AI Challenges, and Building Multimodal Apps next.