
Context engineering in agentic AI is the practice of selecting, organizing, filtering, and updating the information an AI agent needs to complete a task. It goes beyond writing a good prompt by managing memory, retrieved documents, tool results, user preferences, rules, examples, and constraints inside an agent workflow.
In Simple Terms
Context engineering means giving an AI agent the right information at the right time.
A prompt tells the model what to do. Context tells the model what it needs to know before doing it. For an AI agent, that context may include task history, company policy, customer data, tool outputs, document snippets, previous decisions, and safety rules.
The goal is simple: reduce guessing and improve task success.
What Is Context Engineering in Agentic AI?
Context engineering in agentic AI is the design of the information environment around an AI agent. It decides what context enters the model, what stays outside, what gets retrieved, what gets summarized, and what should be removed.
Anthropic describes context as a critical but finite resource for AI agents and discusses strategies for curating and managing it effectively. That idea is important because agentic AI systems often run across multiple steps. They do not only answer one prompt; they plan, retrieve, use tools, take actions, and check results.
For example, a customer support agent may need the user’s message, account history, refund policy, recent tool outputs, product documentation, and escalation rules. Too little context leads to weak answers. Too much context can overload the model, increase cost, and introduce irrelevant noise.
Context Engineering vs Prompt Engineering
Prompt engineering focuses on how instructions are written. Context engineering focuses on what information is assembled around the task.
| Area | Prompt Engineering | Context Engineering |
| Main focus | Instruction wording | Information design |
| Typical question | “How should I ask?” | “What should the agent know?” |
| Scope | Usually one prompt | Full workflow context |
| Key elements | Role, format, tone, task | Memory, retrieval, tools, rules, examples |
| Best for | Improving model response style | Improving agent reliability |
Prompt engineering still matters. But in agentic AI, a perfect instruction is not enough if the agent has the wrong documents, stale memory, missing tool results, or irrelevant examples.
Why AI Agents Need Context Engineering
AI agents need context engineering because they make decisions over time. They may call tools, read results, choose the next step, and act inside software systems.
Google Cloud describes AI agents as systems that pursue goals and complete tasks, often using reasoning, planning, and memory.IBM describes agentic AI as an AI system that can accomplish a specific goal with limited supervision.These systems need more than a single prompt because their decisions depend on changing information.
A coding agent needs repository structure, coding guidelines, relevant files, test output, and issue history. A sales agent needs CRM context, meeting notes, product details, pricing rules, and follow-up history. A research agent needs sources, citations, constraints, and evaluation criteria.
Without context engineering, agents behave like smart workers dropped into a task with missing instructions and messy files.
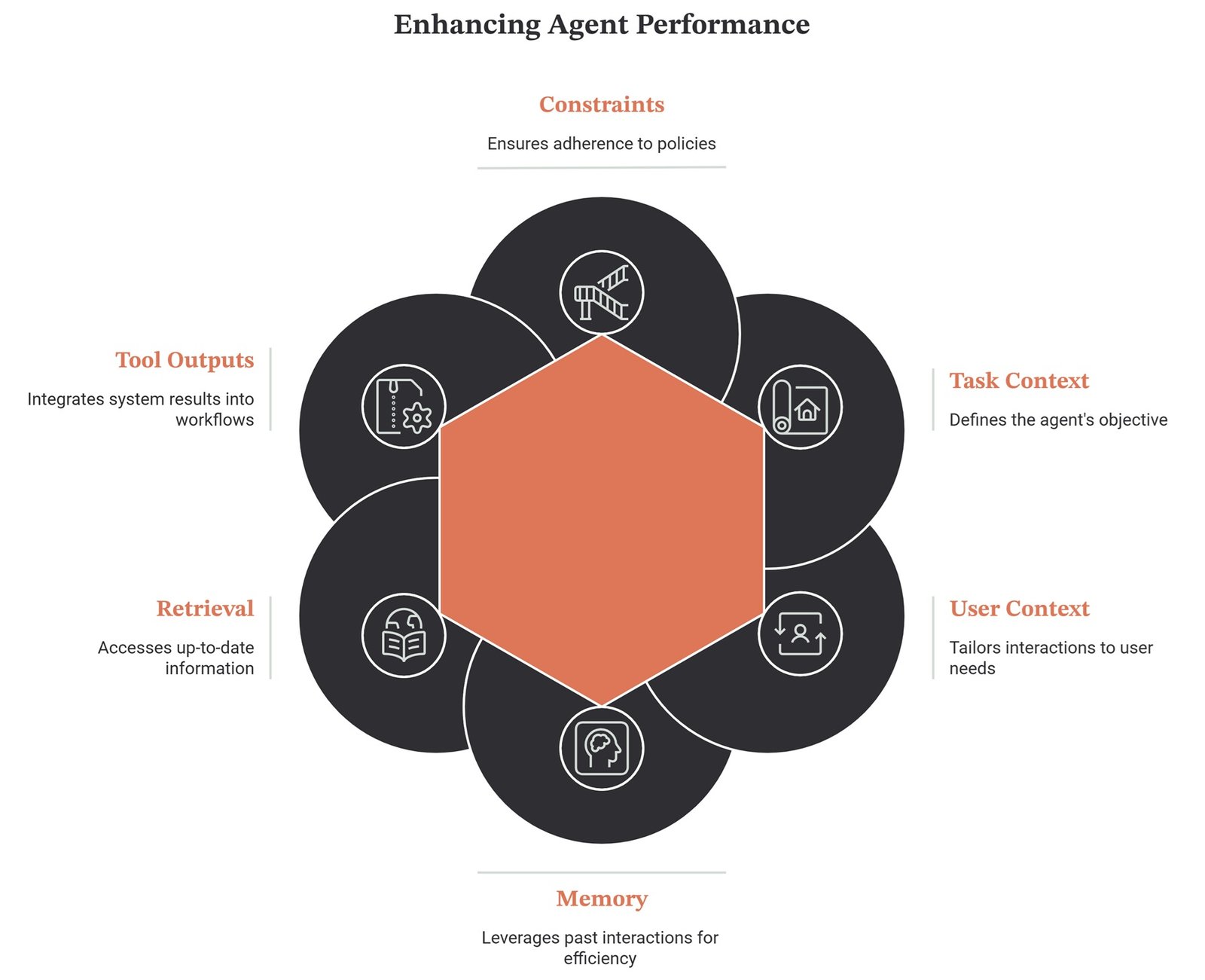
Core Components of Context Engineering
A strong context engineering system usually includes six parts.
| Component | What It Adds | Example |
| Task context | What the agent is trying to do | “Resolve duplicate charge” |
| User context | Who the task is for | Account tier, preferences |
| Memory | Relevant past interactions | Previous support tickets |
| Retrieval | Fresh external information | Policy docs, product docs |
| Tool outputs | Results from APIs or systems | Payment lookup result |
| Constraints | Rules and limits | “Do not issue refund without approval” |
The best context is not the largest context. It is the most relevant context.
How Context Engineering Works
Context engineering usually follows a pipeline.
First, the system identifies the task. It decides whether the agent is answering a question, updating a workflow, retrieving a file, writing code, or escalating a case.
Second, it gathers possible context. This may include memory, documents, logs, tool outputs, database records, policies, examples, and user preferences.
Third, it filters context. Irrelevant, outdated, duplicated, or unsafe information should be removed.
Fourth, it compresses or summarizes context when needed. Agents often work within context-window limits, so long histories and documents may need shorter task-specific summaries.
Fifth, it orders the context. Critical instructions, constraints, and evidence should be placed where the model can use them effectively.
Finally, it updates context after each action. If a tool returns new information, the agent should use it in the next step.
Context Engineering for a Support Agent
Imagine a customer says, “I was charged twice.”
Poor context would pass only the customer message into the model. The agent might guess.
Good context would include:
- The customer’s account status.
- Recent payment records.
- Refund policy.
- Duplicate-charge procedure.
- Previous support history.
- Tool output from the billing system.
- A rule requiring human approval before refunds.
Now the agent can classify the issue, compare transactions, draft a response, and escalate the refund decision safely.
This is context engineering in practice.
Context Engineering for a Coding Agent
A coding agent working on a bug fix needs more than the issue description. It needs the relevant files, project architecture, dependency rules, coding conventions, test results, and pull-request requirements.
A 2025 paper on context engineering for AI agents in open-source software argues that agent-based coding assistants need project-specific context such as architecture, interfaces, coding guidelines, standard workflows, and policies. This is exactly why context engineering matters for agentic AI: the agent’s output depends heavily on the information it is given.
Context Window Limits and Context Overload
Context engineering also protects the agent from overload. More context is not always better.
Large context windows can hold more information, but irrelevant context can still confuse the model. Long histories may contain outdated facts. Retrieved documents may include conflicting passages. Tool outputs may be too verbose.
Good systems use retrieval, ranking, summarization, deduplication, metadata, and recency checks to keep context useful.
Role of RAG, Memory, and Tools
RAG helps agents retrieve fresh or domain-specific knowledge. Memory helps agents remember useful task or user context. Tools help agents interact with real systems.
Context engineering decides how these pieces enter the agent workflow. It answers questions such as:
- Which memory should be recalled?
- Which documents should be retrieved?
- Which tool result should override old context?
- Which context needs citation?
- Which action requires human review?
This is why context engineering is central to reliable agentic AI architecture.
Common Mistakes in Context Engineering
The first mistake is treating context as a document dump. Passing too many files into the model can reduce accuracy and increase cost.
The second mistake is using stale memory. If an agent remembers outdated preferences, policies, or customer states, it may act incorrectly.
The third mistake is ignoring permissions. Agents should not receive sensitive context unless the task requires it and the user has access.
The fourth mistake is skipping evaluation. Context engineering should be tested for retrieval quality, faithfulness, task completion, latency, cost, and safety.
Risks and Limitations
Context engineering can reduce hallucinations, but it does not eliminate them. Agents can still misread context, retrieve weak evidence, over-trust old memory, or misuse tool outputs.
It also creates privacy and governance challenges. Context may include customer records, business secrets, medical files, financial data, or internal policies. Teams need access control, logging, retention rules, and redaction.
Prompt injection is another risk. Malicious instructions can appear inside retrieved documents or webpages. A strong context pipeline should separate trusted system rules from untrusted content.
Suggested Read:
- What Is Agentic AI? A Practical Guide for Beginners
- How Agentic AI Works: Planning, Memory, Tools, and Action
- Agentic AI Architecture Explained Simply
- What Is an AI Agent? A Simple Explanation With Examples
- MCP Explained: Why It Matters for AI Agents
- AI Agent Memory Explained
- How to Evaluate an AI Agent Before Production
- What Is RAG in AI? A Beginner-Friendly Guide
FAQ: What Is Context Engineering in Agentic AI?
What is context engineering in agentic AI?
Context engineering in agentic AI is the practice of designing, selecting, filtering, organizing, and updating the information an AI agent uses to complete a task.
How does context engineering work?
It gathers task context, memory, retrieved documents, tool results, examples, constraints, and policies, then filters and orders them for the agent.
Why do AI agents need context engineering?
Agents need context engineering because they plan, use tools, remember information, and act across multi-step workflows where missing or noisy context can cause failure.
What is the difference between context engineering and prompt engineering?
Prompt engineering focuses on writing better instructions. Context engineering focuses on assembling the right information around those instructions.
What context do AI agents need?
They may need goals, user history, task state, retrieved documents, tool outputs, policies, examples, metadata, constraints, and human approval rules.
What are the risks of poor context engineering?
Risks include hallucinations, wrong actions, irrelevant retrieval, stale memory, privacy leaks, prompt injection, higher cost, and unreliable agent behavior.
Final Takeaway
Context engineering in agentic AI is about giving agents the right information, not just better instructions. Strong agent systems need relevant memory, retrieval, tool outputs, constraints, examples, and safety rules arranged in a way the model can use.
To continue learning, read How Agentic AI Works, Agentic AI Architecture Explained, and MCP Explained next.