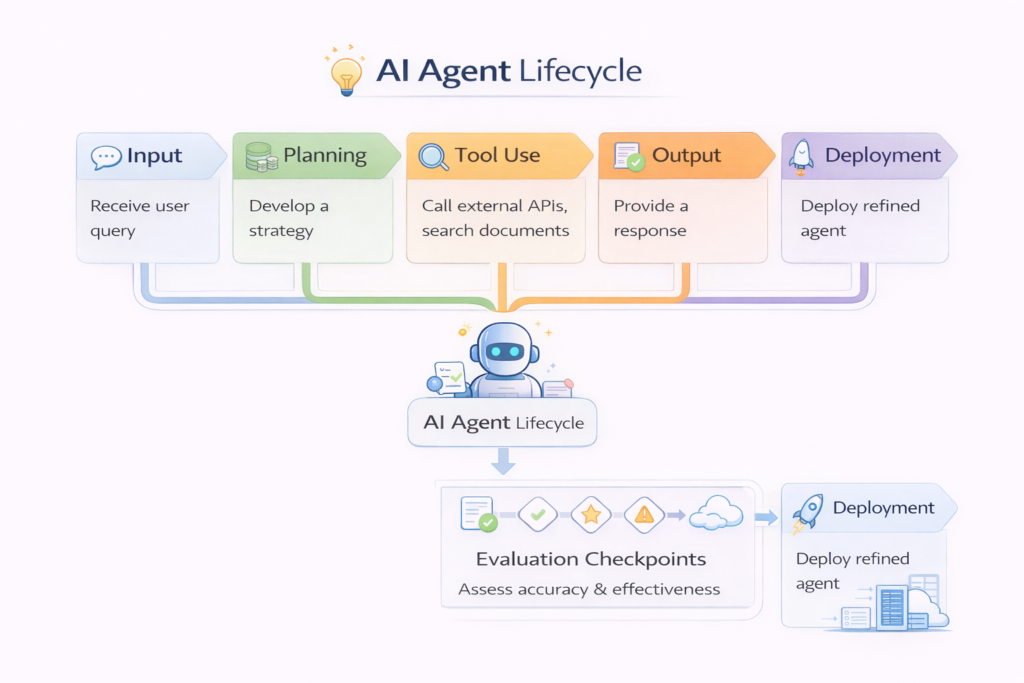
How to Evaluate AI Agent Before Production
Deploying an AI agent without proper evaluation is risky. Unlike traditional software, AI agents are dynamic systems—they plan, reason, use tools, and adapt to inputs. This makes them powerful, but also unpredictable.
To safely deploy an AI agent, you need to evaluate not just its outputs, but its decision-making, tool usage, and reliability under real-world conditions.
In simple terms
Before deploying an AI agent, you need to answer:
- Does it complete tasks correctly?
- Does it use tools properly?
- Does it fail safely?
- Can it handle real-world scenarios?
If not, it is not production-ready.
Why AI agent evaluation is different
AI agents are harder to evaluate than LLMs because they:
- perform multi-step reasoning
- interact with external tools
- operate in dynamic environments
- make decisions, not just outputs
This means evaluation must go beyond simple accuracy.
The 5 Layers of AI Agent Evaluation
1. Task success evaluation
Measure whether the agent completes tasks correctly.
Example
Task: “Book a meeting and send confirmation email”
Evaluation:
- Did it schedule correctly?
- Did it send the email?
Metric
- success rate (%)
2. Tool usage evaluation
AI agents often rely on tools (APIs, databases).
What to check
- correct tool selection
- correct parameters
- successful execution
Failure example
- calling wrong API
- sending incorrect data
3. Reasoning evaluation
Check how the agent thinks.
Evaluate
- logical steps
- planning quality
- decision consistency
Even if output is correct, poor reasoning can break at scale.
4. Reliability and robustness
Test how the agent behaves under different conditions.
Test cases
- incomplete input
- ambiguous queries
- unexpected data
- tool failures
Goal
Ensure the agent handles errors gracefully.
5. Safety and guardrails
Ensure the agent does not:
- generate harmful content
- leak sensitive data
- perform unsafe actions
This is critical for production systems.
Key Metrics for AI Agent Evaluation
1. Task success rate: Percentage of tasks completed correctly.
2. Tool accuracy: Correct tool usage rate.
3. Error rate: Frequency of failures.
4. Latency: Time taken to complete tasks.
5. Cost per task:Important for scaling.
6. User satisfaction: Real-world feedback.
AI Agent Evaluation Checklist Before Deployment
Functional testing
- Does the agent complete core tasks?
- Are outputs correct?
Edge case testing
- How does it handle unclear inputs?
- Does it fail safely?
Tool testing
- Are APIs called correctly?
- Are errors handled?
Load testing
- Can it handle multiple users?
Monitoring setup
- Are logs and metrics tracked?
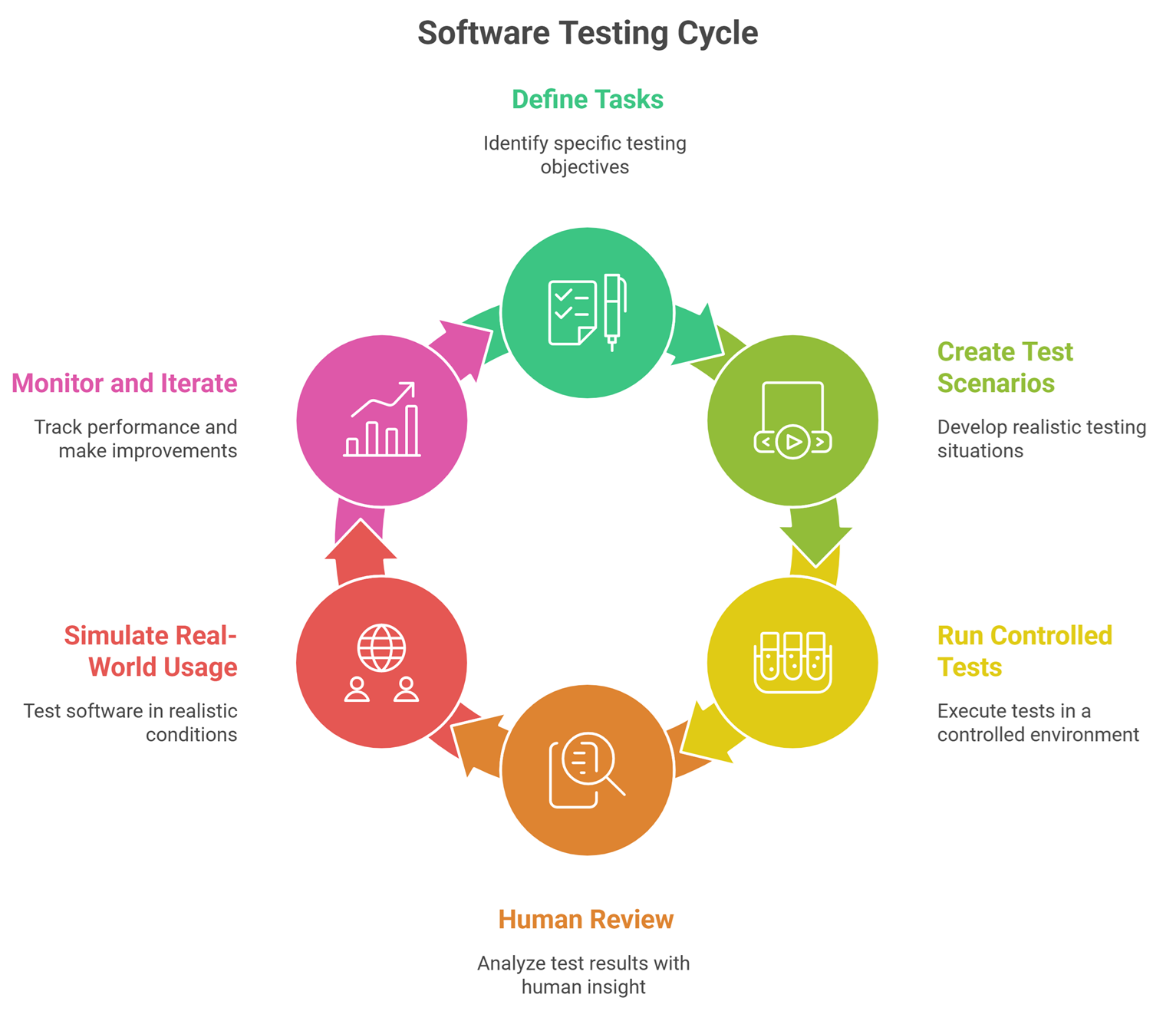
Step-by-step evaluation process
Step 1: Define tasks
List all tasks the agent should perform.
Step 2: Create test scenarios
Include:
- normal cases
- edge cases
- failure cases
Step 3: Run controlled tests
Evaluate:
- success rate
- tool usage
- reasoning
Step 4: Human review
Check outputs for:
- correctness
- usefulness
- safety
Step 5: Simulate real-world usage
Run:
- user queries
- workflow simulations
Step 6: Monitor and iterate
Track performance and improve continuously.
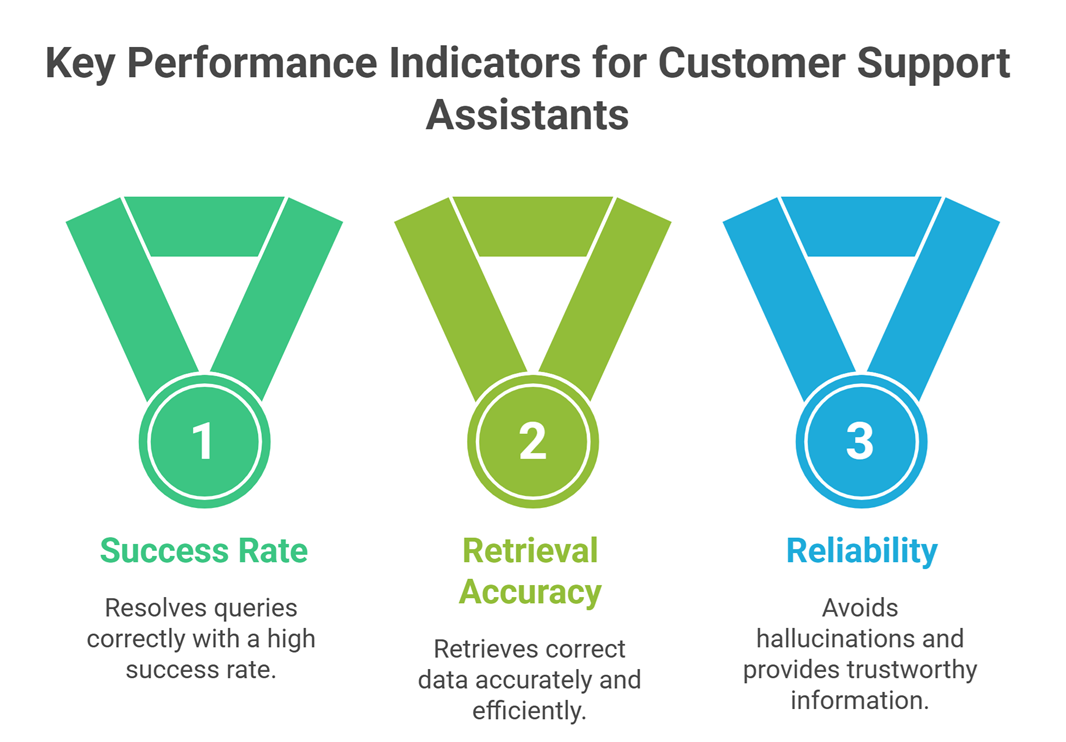
Real-world evaluation example
Agent: Customer support assistant
Evaluation:
- resolves queries correctly → success rate
- retrieves correct data → retrieval accuracy
- avoids hallucinations → reliability
- escalates complex issues → safety
This multi-layer evaluation ensures production readiness.
Common mistakes
- testing only final outputs
- ignoring tool failures
- not testing edge cases
- skipping human evaluation
- deploying too early
Most production issues come from incomplete evaluation.
When an AI agent is ready for production
An agent is ready when:
- success rate is consistently high
- failure cases are handled safely
- tool usage is reliable
- performance is stable under load
If any of these fail, the system needs improvement.
Suggested Read:
- What Is an AI Agent? A Simple Explanation With Examples
- AI Agent Architecture Explained Simply
- Best AI Agent Frameworks for Developers in 2026
- 10 Real Business Use Cases for AI Agents
- How to Evaluate a RAG System
- Why LLMs Hallucinate and How to Reduce It
FAQ: Evaluate AI Agent Before Production
What is the most important metric?
Task success rate, but it must be combined with reliability and safety.
Can evaluation be automated?
Partially, but human review is still important.
How long should evaluation take?
Until performance is consistent across real-world scenarios.
Do all agents need the same evaluation?
No, evaluation depends on the use case.
Final takeaway
Evaluating an AI agent is about testing the entire system—not just outputs. You need to measure task success, tool usage, reasoning, and reliability.
The best AI agents are not the smartest—they are the most reliable under real-world conditions.