Best Chunk Size for RAG: How to Optimize AI Retrieval Quality
Retrieval-Augmented Generation (RAG) systems have become one of the most important architectures in modern Artificial Intelligence. Enterprises increasingly use RAG-powered AI assistants, enterprise search systems, customer support copilots, document intelligence platforms, and semantic retrieval systems to improve AI accuracy and reduce hallucinations.
However, one major factor still determines whether a RAG system performs well or poorly:
Chunk size
Many beginners focus heavily on:
- embeddings
- vector databases
- reranking
- semantic search
- Large Language Models
while overlooking how document chunking directly affects retrieval quality.
Even the most advanced Large Language Models can generate poor answers if retrieval chunks are badly structured.
Choosing the best chunk size for RAG is critical because chunk size affects:
- semantic retrieval precision
- contextual continuity
- grounding quality
- prompt efficiency
- hallucination reduction
- enterprise AI search performance
Today, chunk optimization has become a foundational part of modern RAG engineering across:
- enterprise AI systems
- legal AI assistants
- healthcare retrieval systems
- customer support copilots
- AI research assistants
- ecommerce AI platforms
- semantic search engines
In this guide, you will learn how chunk size affects RAG systems, the advantages and limitations of different chunk sizes, and the best chunking strategies used in modern enterprise AI architectures.
In Simple Terms
What Is Chunk Size in RAG?
Chunk size refers to how much text is stored inside each retrieval chunk.
When documents are processed inside a RAG pipeline, they are split into smaller sections called chunks before embeddings are generated.
Each chunk becomes a searchable semantic unit.
Chunk size determines how large or small those units are.
Examples include:
- 200-token chunks
- 500-token chunks
- 1000-token chunks
Different chunk sizes create very different retrieval behavior.
Why Chunk Size Matters
Chunk size directly affects:
- retrieval precision
- contextual relevance
- semantic continuity
- prompt quality
- vector search performance
If chunks are too small, important context may be lost.
If chunks are too large, retrieval becomes noisy and inefficient.
Finding the right balance is critical.
Easy Analogy
Imagine searching for one paragraph inside a massive textbook.
Very Large Chunks
The AI retrieves entire chapters.
This includes too much irrelevant information.
Very Small Chunks
The AI retrieves fragmented sentences without context.
Neither approach is ideal.
The best chunk size balances:
- precision
- context
- retrieval quality
That is exactly why chunk optimization became essential for modern RAG systems.
Why Chunk Size Became Critical in RAG
Modern enterprise AI systems operate across enormous knowledge bases.
These systems contain:
- PDFs
- research papers
- internal documentation
- support manuals
- legal contracts
- healthcare guidelines
- cloud knowledge repositories
Without proper chunking, semantic retrieval quality drops significantly.
Large Documents Are Difficult to Retrieve Efficiently
Embedding entire documents creates several problems:
- weak retrieval precision
- high retrieval noise
- inefficient prompts
- wasted context windows
Chunking solves these issues by breaking documents into smaller semantic units.
Chunk Size Affects Semantic Search Quality
Semantic retrieval systems compare embeddings for contextual similarity.
The structure of chunks directly affects embedding quality.
Poor chunk boundaries weaken semantic retrieval accuracy.
Chunk Size Affects Hallucinations
Hallucinations often happen because the AI receives incomplete or noisy retrieval context.
Weak chunking strategies may cause:
- fragmented retrieval
- incomplete workflows
- missing semantic continuity
- irrelevant supporting context
Better chunk sizing improves grounding quality significantly.
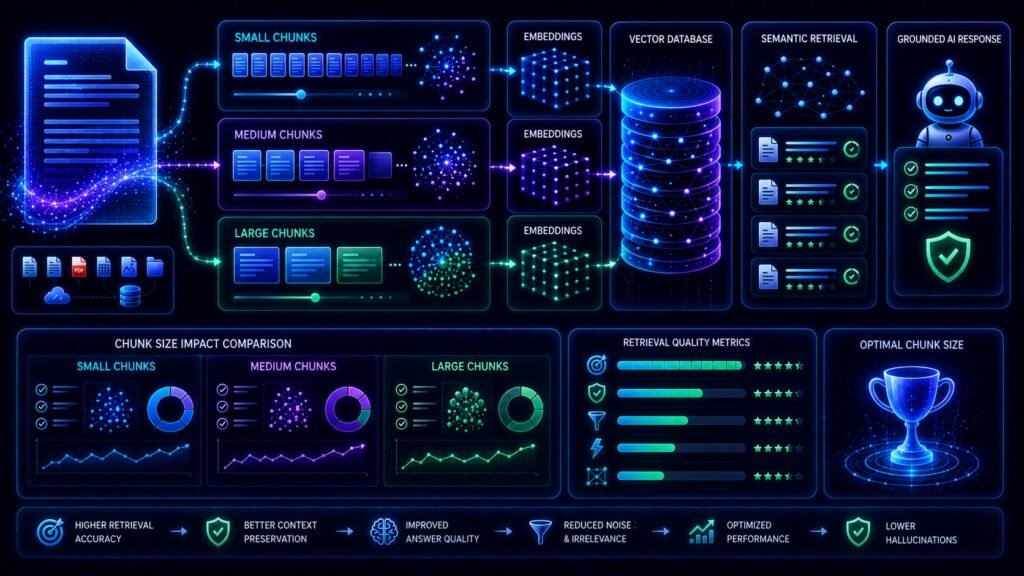
How Chunk Size Works in RAG Systems
Understanding chunk size becomes easier when broken into stages.
Step 1: Documents Are Collected
The RAG system gathers external knowledge sources such as:
- PDFs
- enterprise files
- support manuals
- websites
- cloud documents
- research papers
These become searchable knowledge repositories.
Step 2: Documents Are Split Into Chunks
The system divides documents into smaller sections.
This process is called chunking.
The chunk size determines how large those sections become.
Step 3: Chunks Become Embeddings
Each chunk is converted into embeddings.
What Are Embeddings?
Embeddings are numerical vector representations of semantic meaning.
They enable semantic retrieval.
Step 4: Embeddings Are Stored in Vector Databases
The embeddings are stored inside vector databases such as:
This enables semantic similarity search.
Step 5: User Queries Enter the Retrieval System
The user submits a question.
The query is converted into embeddings.
Step 6: Relevant Chunks Are Retrieved
The vector database retrieves semantically similar chunks.
The retrieved chunks become contextual grounding for the Large Language Model.
Step 7: The LLM Generates a Response
The retrieved chunks are inserted into the prompt.
The language model generates grounded responses using that contextual information.
This completes the RAG workflow.
Small Chunk Sizes vs Large Chunk Sizes
One of the biggest questions in RAG engineering is whether chunk sizes should be small or large.
The answer depends heavily on the use case.
Small Chunks Improve Precision
Smaller chunks often improve retrieval granularity.
Examples:
- 100-token chunks
- 200-token chunks
- 300-token chunks
These chunks allow highly precise retrieval.
Benefits of Small Chunks
Better Retrieval Precision
Smaller chunks isolate specific information more effectively.
Lower Retrieval Noise
The system retrieves less irrelevant content.
Better Embedding Focus
Embeddings represent narrower semantic concepts more clearly.
Improved Search Relevance
Highly targeted retrieval improves semantic matching.
Problems With Small Chunks
Small chunks also create challenges.
Loss of Context
Very small chunks may remove important surrounding information.
Fragmented Workflows
Complex explanations may become disconnected.
Weak Semantic Continuity
Contextual relationships between ideas may disappear.
More Retrieval Calls
Small chunks increase vector database indexing complexity.
Large Chunks Preserve Context
Larger chunks maintain stronger semantic continuity.
Examples include:
- 800-token chunks
- 1200-token chunks
- multi-paragraph retrieval units
Benefits of Large Chunks
Better Context Preservation
Large chunks preserve broader semantic meaning.
Stronger Workflow Continuity
Procedural explanations remain connected.
Improved Narrative Structure
Complex topics remain semantically complete.
Better Long-Form Context
Longer explanations retain important supporting details.
Problems With Large Chunks
Large chunks also create major retrieval issues.
Increased Retrieval Noise
The system retrieves too much irrelevant information.
Reduced Precision
Large chunks may dilute semantic focus.
Higher Prompt Costs
Larger chunks consume more tokens.
Context Window Waste
Too much irrelevant information enters the prompt.
What Is the Best Chunk Size for RAG?
There is no universal chunk size for every RAG system.
The ideal chunk size depends on:
- document structure
- retrieval goals
- use case
- model context windows
- enterprise requirements
However, modern enterprise systems often use:
| Use Case | Common Chunk Size |
| FAQ systems | 100–300 tokens |
| Customer support AI | 300–600 tokens |
| Enterprise search | 400–800 tokens |
| Legal AI systems | 500–1200 tokens |
| Research retrieval | 800–1500 tokens |
These ranges are common starting points rather than universal rules.
Why Semantic Chunking Is Often Better
Many modern RAG systems now prefer:
Semantic Chunking
instead of purely fixed token chunking.
Semantic chunking splits documents based on:
- topic boundaries
- paragraph structure
- contextual meaning
- semantic transitions
This creates more meaningful retrieval units.
Why Semantic Chunking Improves Retrieval
Semantic chunking improves:
- contextual continuity
- retrieval precision
- semantic coherence
- grounded generation
This makes it highly effective for enterprise AI systems.
What Is Chunk Overlap?
Chunk overlap preserves contextual continuity between neighboring chunks.
Example:
Chunk 1:
Tokens 1–500
Chunk 2:
Tokens 400–900
This overlapping structure prevents context loss.
Why Chunk Overlap Matters
Without overlap:
- semantic transitions may break
- workflows may fragment
- retrieval continuity weakens
Overlap helps preserve contextual relationships.
Best Chunk Overlap Practices
Most enterprise systems use:
- 10% to 20% overlap
- 50 to 150 overlapping tokens
depending on chunk size.
Excessive overlap increases redundancy and storage costs.
Fixed Chunking vs Semantic Chunking
| Feature | Fixed Chunking | Semantic Chunking |
| Simplicity | Strong | Moderate |
| Semantic quality | Moderate | Strong |
| Retrieval precision | Moderate | Strong |
| Context preservation | Moderate | Strong |
| Scalability | Strong | Moderate |
| Enterprise AI suitability | Moderate | Strong |
Best Chunking Practices for RAG
Modern enterprise AI systems increasingly follow several chunk optimization principles.
Preserve Semantic Meaning
Chunks should preserve coherent contextual information.
Avoid splitting important concepts unnaturally.
Optimize for Retrieval Precision
Chunking should improve semantic retrieval quality rather than simply reduce document size.
Match Chunk Sizes to Use Cases
Different industries require different chunking strategies.
Examples include:
- legal AI
- customer support
- healthcare retrieval
- financial AI
- enterprise copilots
Use Overlap Carefully
Chunk overlap improves continuity but excessive overlap increases redundancy.
Combine Chunking With Metadata
Metadata-aware chunking improves enterprise retrieval precision significantly.
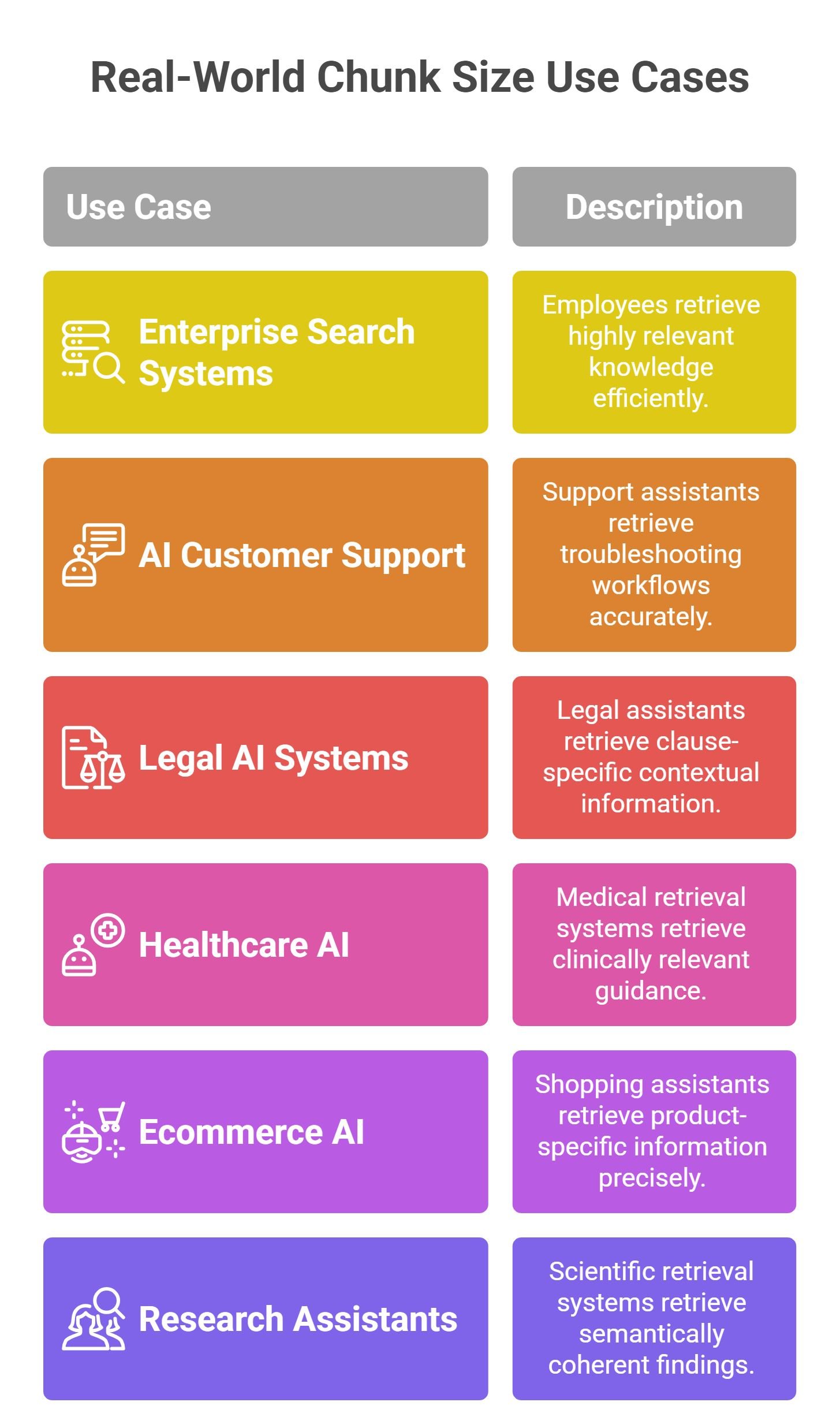
Real-World Chunk Size Use Cases
Enterprise Search Systems
Employees retrieve highly relevant knowledge efficiently.
AI Customer Support
Support assistants retrieve troubleshooting workflows accurately.
Legal AI Systems
Legal assistants retrieve clause-specific contextual information.
Healthcare AI
Medical retrieval systems retrieve clinically relevant guidance.
Ecommerce AI
Shopping assistants retrieve product-specific information precisely.
Research Assistants
Scientific retrieval systems retrieve semantically coherent findings.
Common Chunking Challenges
Chunk optimization also introduces engineering complexity.
Over-Chunking
Chunks that are too small lose contextual meaning.
Under-Chunking
Chunks that are too large reduce retrieval precision.
Retrieval Redundancy
Excessive overlap creates duplicate retrieval results.
Infrastructure Complexity
Advanced semantic chunking requires additional processing resources.
Domain-Specific Optimization
Different enterprise environments require different chunking strategies.
Future of Chunk Optimization in RAG
Chunk optimization systems are evolving rapidly.
Major trends include:
- AI-generated chunking
- adaptive semantic chunking
- multimodal chunking
- dynamic contextual segmentation
- graph-enhanced retrieval chunking
- autonomous retrieval optimization
Future enterprise AI systems will likely rely heavily on intelligent chunk orchestration.
Suggested Read
- Chunking Strategies for RAG
- Embeddings for RAG
- Vector Database for RAG
- RAG Pipeline Explained
- Reranking in RAG
- Metadata Filtering in RAG
FAQ: Best Chunk Size for RAG
What is the best chunk size for RAG?
There is no universal answer, but many systems use 300–800 token chunks depending on the use case.
Why is chunk size important?
Chunk size affects retrieval precision, semantic continuity, grounding quality, and hallucination reduction.
What is semantic chunking?
Semantic chunking splits documents according to contextual meaning instead of arbitrary token limits.
What is chunk overlap?
Chunk overlap preserves contextual continuity between neighboring chunks.
Should RAG use small or large chunks?
The ideal approach balances precision and contextual continuity.
Final Takeaway
Understanding the best chunk size for RAG is important because chunk size directly affects retrieval quality, semantic relevance, prompt efficiency, and grounded AI generation.
Well-optimized chunking strategies help AI systems retrieve more accurate contextual information while reducing hallucinations and improving enterprise search quality.
That capability is transforming how modern Retrieval-Augmented Generation systems, enterprise AI assistants, semantic search platforms, and intelligent document retrieval systems operate today.