Testing Prompts Systematically: How to Improve AI Prompts With Real Data
Most people write prompts randomly, change a few words, and hope results improve. That approach does not scale.
If prompts power content creation, support automation, coding, research, or internal workflows, they should be tested systematically.
Strong teams treat prompts like product assets: measured, improved, and monitored over time.
This guide explains how to test prompts systematically so you can improve AI output quality, reduce costs, and build reliable workflows.
In simple terms
Testing prompts systematically means:
Using repeatable experiments, clear metrics, and structured comparisons to find the best prompt version.
Instead of guessing, you use evidence.
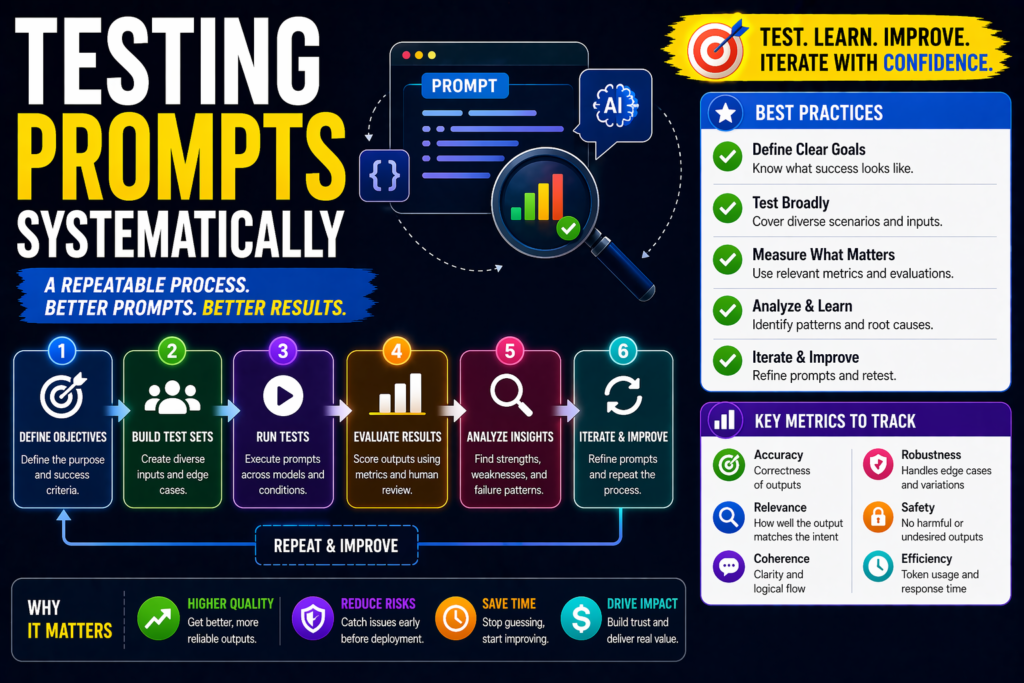
Why Systematic Prompt Testing Matters
Without testing, prompt performance often depends on luck.
Systematic testing helps you:
- improve output quality
- reduce hallucinations
- increase consistency
- lower token usage
- improve user satisfaction
- scale AI operations faster
This becomes critical once prompts are used in production.
What should you test?
Before changing prompts, define what success means.
Common prompt metrics include:
- accuracy
- relevance
- completeness
- formatting compliance
- consistency
- safety
- speed
- token cost
- user ratings
Example:
A support prompt values correctness and tone.
A coding prompt values logic and reliability.
Best Framework For Testing Prompts Systematically
1.Define the task clearly
Examples:
- summarize calls
- classify tickets
- write SEO briefs
- generate code
- answer FAQs
If the task is unclear, testing becomes meaningless.
2.Build a test dataset
Use 20 to 100 real examples.
Include:
- easy cases
- average cases
- difficult cases
- edge cases
Good datasets create better decisions.
3.Create multiple prompt versions
Do not compare only one prompt.
Examples:
Prompt A
Short direct instruction.
Prompt B
Structured prompt with format requirements.
Prompt C
Prompt with examples included.
4.Run identical inputs
Use the same dataset for each prompt version.
This keeps comparisons fair.
5.Score outputs
Use one or more methods:
- human review
- pass/fail checks
- LLM judge scoring
- user feedback
- automated validators
6.Compare results
Track which prompt wins on:
- quality
- speed
- cost
- consistency
The best prompt is often a balance.
7.Iterate and retest
Improve wording, examples, constraints, and structure.
Then rerun tests.
Practical Prompt Testing Methods
A/B Testing
Compare Prompt A vs Prompt B directly.
Best for fast decisions.
Benchmark Testing
Use a permanent dataset repeatedly.
Best for long-term workflows.
Regression Testing
Retest older cases after updates.
Prevents accidental quality drops.
Multi-Metric Scorecards
Score outputs across several dimensions.
Best for nuanced tasks.
Live User Feedback
Use thumbs up/down, edits, completion rates.
Best for production environments.
Example scorecard
| Metric | Prompt A | Prompt B |
| Accuracy | 8/10 | 9/10 |
| Speed | Fast | Medium |
| Cost | Low | Medium |
| Format Compliance | 82% | 97% |
| User Preference | 58% | 76% |
Prompt B may be the better production choice.
Common mistakes when testing prompts
Testing one example only
Small samples mislead decisions.
No success metrics
You cannot optimize vague goals.
Ignoring cost
Better outputs may be too expensive.
No edge cases
Prompts may fail in real use.
No retesting
Models and workflows change over time.
Pure opinion scoring
Use structured rubrics whenever possible.
Copy-paste systematic testing template
Task: Blog intro generation
Dataset: 50 blog topics
Prompts:
- Prompt A = simple request
- Prompt B = structured SEO request
- Prompt C = structured + examples
Metrics:
- CTR potential
- clarity
- originality
- speed
- token cost
Choose highest total performer.
Best tools for teams
Useful tools and methods:
- spreadsheets for scoring
- evaluation dashboards
- human reviewers
- analytics tools
- automated scripts
- internal feedback loops
Even simple systems outperform no system.
Suggested Read:
- What Is Prompt Engineering? Complete Beginner Guide
- Prompt Evaluation Methods
- Prompt Engineering Best Practices
- Reusable Prompt Templates
- Structured Prompting Guide
- How to Evaluate an AI Agent Before Production
FAQ: Testing Prompts Systematically
What does testing prompts systematically mean?
It means using repeatable experiments and metrics to improve prompts.
How many prompts should I compare?
Usually 2 to 5 versions per round is enough.
Should small teams do this?
Yes. Even lightweight testing creates better results.
How often should prompts be retested?
Whenever models, workflows, or business goals change.
Final takeaway
Prompt quality should not depend on guesswork. Testing prompts systematically helps you improve outputs using real evidence.
If prompts matter to your business, build datasets, compare versions, track metrics, and keep iterating. That is how strong AI workflows are built.