
Sakana Fugu Uses a Team of AI Models to Beat One Model’s Limits
Sakana AI released Fugu and Fugu Ultra on June 22, 2026, turning its multi-agent research into a commercial AI service that developers can access through one API.
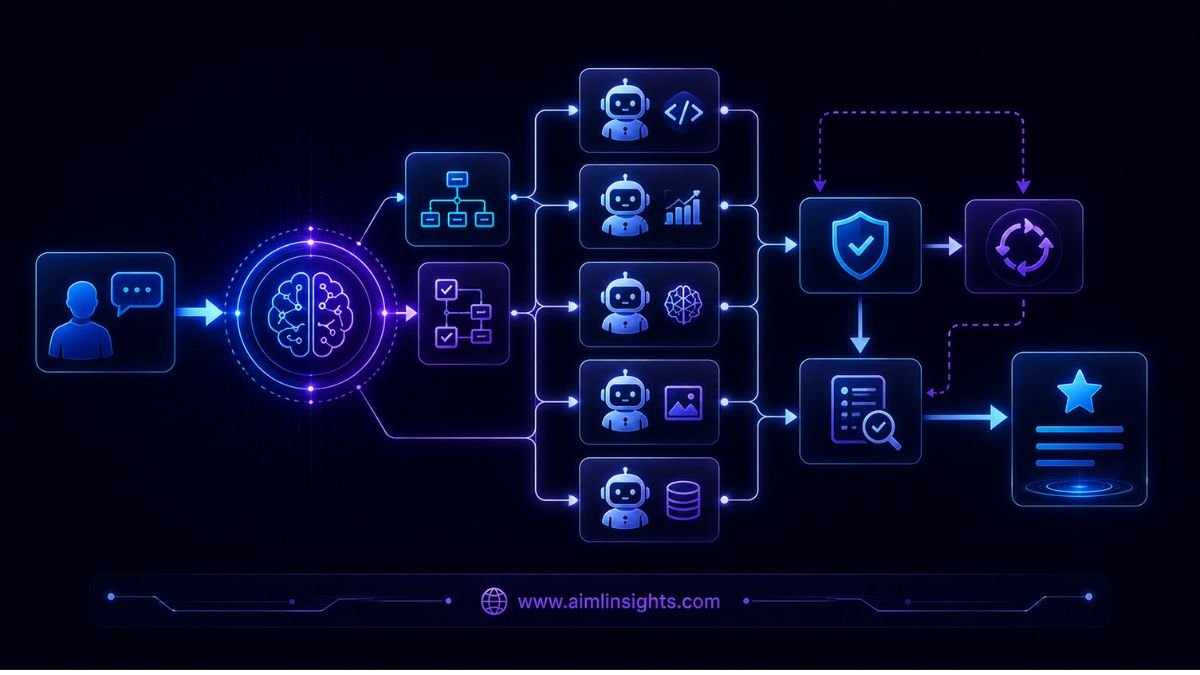
Instead of relying on one large language model for every question, Sakana AI Fugu can decide whether to answer directly or assemble several models to plan, solve, critique, verify, and combine a response.
The product matters to developers, AI startups, researchers, and enterprises that need better performance on difficult coding, scientific, and reasoning tasks. Sakana reports that Fugu Ultra reaches frontier-level results on several benchmarks, but the system also introduces additional latency, token usage, provider exposure, and orchestration complexity.
What Is Sakana AI Fugu?
Sakana Fugu is a multi-agent system presented to the user as a single foundation-model API.
A developer sends one request to an OpenAI-compatible endpoint. Behind that endpoint, Fugu decides whether one model is enough or whether the task should be split across several agents. It controls model selection, role assignment, task delegation, verification, communication between agents, and final-response synthesis.
Sakana offers two main versions:
- Fugu balances performance and response time for routine work.
- Fugu Ultra uses deeper orchestration for difficult tasks where answer quality matters more than speed.
Sakana says early users have applied Fugu Ultra to AI research, paper reproduction, cybersecurity analysis, patent investigation, coding, and long-running data-science work.
How Fugu’s Architecture Works
Fugu is itself an orchestrator language model.
It reads the user’s request and creates an adaptive workflow over a pool of available models. That workflow may determine:
- Which models should participate
- What subtask each model receives
- Which earlier messages each agent can see
- Whether another agent should verify the result
- How intermediate outputs should be combined
The final user sees one answer, even though several hidden model calls may have contributed to it.
The architecture builds on Sakana AI’s Trinity and Conductor research.
Trinity uses a lightweight coordinator to select models over multiple turns and assign one of three roles:
- Thinker: develops a strategy or breaks down the problem
- Worker: performs the main calculation or implementation
- Verifier: checks whether the developing answer is correct and complete
The coordinator can continue through several turns until a verifier accepts the answer or a preset turn budget is reached.
The Conductor approach is more flexible. A small model writes the collaboration workflow in natural language, specifying the participating agents, their subtasks, and their communication structure. It can also invoke itself recursively, inspect an earlier failure, and create a corrective workflow at inference time.
Why Fugu Is More Than Simple Model Routing
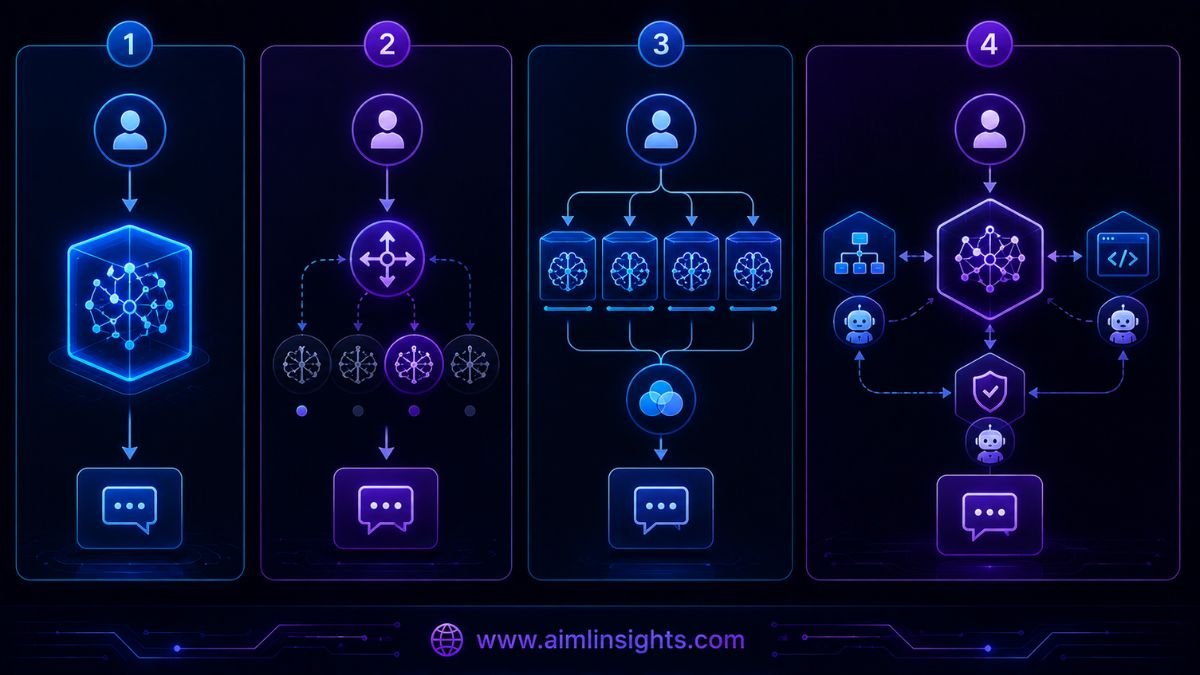
A normal model router selects one model and forwards the entire request to it.
For example, a router might send coding questions to one model and writing questions to another. Once the choice is made, the selected model completes the task alone.
Fugu can instead coordinate several models over multiple turns. One agent may create a plan, another may solve a technical subproblem, and a third may review the output. The orchestrator can then request corrections and synthesize the final response.
This makes Fugu closer to a learned mixture of agents than a conventional router.
It is also different from a model ensemble. A basic ensemble may ask several models the same question and choose the majority answer. Fugu can assign different roles and different information to each participant, producing a structured collaboration rather than parallel duplicate responses.
What Is Genuinely New?
Multi-agent prompting and mixture-of-agents systems already exist. Teams can manually build similar workflows using orchestration frameworks, several API keys, routing rules, and custom verification logic.
Fugu’s main product innovation is packaging this complexity as one API.
The user does not manually choose a provider, write a planner-verifier workflow, manage collaboration messages, or combine five outputs. The orchestration model decides the workflow dynamically for each request.
Sakana also lets customers exclude specific providers or models from the agent pool for privacy, compliance, or organizational reasons. That control is important because a multi-provider system may otherwise send information through several external infrastructures.
Benchmark Audit: Does Fugu Ultra Beat One Frontier Model?
Sakana reports strong results across coding and scientific-reasoning benchmarks.
| Benchmark | Metric | Fugu Ultra | Fugu | Selected baseline | Reported difference | Evaluation owner | Independent verification |
| GPQA Diamond | Accuracy on difficult science questions | 95.1 | Earlier beta: 92.4 | Gemini 3.1 High: 94.4 | +0.7 over listed Gemini result | Sakana AI | Not independently reproduced for this release |
| LiveCodeBench v6 | Coding pass score | 93.2 | Earlier beta: 90.4 | Claude Opus baseline: 92.4 | +0.8 over listed Claude result | Sakana AI | Not independently reproduced for this release |
| SWE-Bench Pro | Software-engineering task success | 54.2 | Earlier beta: 51.3 | Claude Opus baseline: 53.4 | +0.8 over listed Claude result | Sakana AI | Not independently reproduced for this release |
Sakana states that non-Fugu benchmark scores are generally taken from model providers. It also says its SWE-related evaluation used the mini-swe-agent scaffold. That means the comparison is useful, but not necessarily a controlled head-to-head test using the same agent harness, token budget, tool configuration, retry count, and inference-time compute for every model.
The technical report was written by the Fugu development team and had been submitted as an arXiv preprint, not published as an independent third-party replication. The authors report state-of-the-art performance across SWE-Bench Pro, Terminal-Bench, LiveCodeBench, GPQA Diamond, Humanity’s Last Exam, and CharXiv Reasoning.
Fugu vs Routing, Ensembles, and One Frontier Model
| Approach | How it works | Main advantage | Main weakness |
| Single frontier model | One model solves the entire task | Low complexity and predictable latency | Limited to one model’s strengths |
| Model router | Selects one model based on the request | Lower cost through targeted selection | No collaboration after routing |
| Model ensemble | Several models answer independently | Can reduce individual-model errors | Repeats work and can be expensive |
| Mixture of agents | Several models critique or build on outputs | Stronger collective reasoning | Often uses fixed human-designed workflows |
| Sakana Fugu | Learns which models, roles, and communication structure to use | Adaptive delegation and verification behind one API | Hidden cost, latency, and debugging complexity |
Fugu’s strongest argument is that no single provider is consistently best at coding, mathematics, science, writing, and verification.
Its counterargument is operational simplicity. A single frontier model is easier to audit, budget, monitor, and reproduce. When an orchestrated response fails, identifying which agent, prompt, or synthesis step caused the error can be difficult.
Why This Matters
AI development has largely focused on building bigger monolithic models.
Fugu represents a different form of inference-time scaling: spend additional compute by coordinating specialized systems only when the task justifies it.
That could help companies avoid total dependence on one provider. If an API becomes unavailable, too expensive, or unsuitable for compliance reasons, the agent pool can theoretically be changed without redesigning the application. Sakana specifically positions this as protection against single-vendor dependency.
For users, the bigger benefit is access to diverse strengths through one integration.
Cost and Latency Trade-Offs
Fugu Ultra is not a low-cost replacement for every model.
Its pay-as-you-go pricing is currently:
- $5 per million input tokens
- $30 per million output tokens
- $10 input and $45 output beyond 272,000 tokens
- $0.50 per million cached input tokens
Sakana also bills orchestration tokens, including hidden input and output consumed by the participating agents. The API reports these separately so users can see how much work occurred behind the final response.
Fugu has a different billing model. Sakana says a single-agent request is charged at the underlying model’s standard rate. When several agents participate, the company charges one rate based on the highest model tier involved rather than simply stacking every provider’s listed fee.
Even with this pricing structure, deeper orchestration can increase total tokens and waiting time. Fugu is therefore best reserved for problems where a better answer is worth more than an immediate one.
Privacy, Deployment, and Best-Fit Users
Fugu is delivered as a hosted API rather than a local orchestration package. Integration is relatively simple because it supports OpenAI-compatible endpoints.
It is best suited to:
- AI researchers reproducing papers
- Developers solving difficult repository-level problems
- Patent and literature analysts
- Scientific teams checking complex reasoning
- Enterprises seeking multi-provider resilience
- Applications where quality matters more than instant response time
It may be unsuitable for:
- Real-time autocomplete
- High-volume low-margin chat
- Strictly local or air-gapped workloads
- Regulated data that cannot pass through external providers
- Tasks where deterministic reproduction is essential
Fugu is not currently available in the EU or EEA while Sakana works on GDPR and regional compliance.
Critical Analysis: What Remains Unclear
Several questions remain unanswered.
Sakana has not published detailed production latency distributions for Fugu Ultra. It is also unclear how often the system selects one model versus many, how frequently verification changes an answer, and how much each orchestration pattern contributes to the final benchmark score.
The provider-reported baseline issue is important. Competing models may have been evaluated with different scaffolds, budgets, dates, and settings.
Multi-agent systems can also amplify errors. If the planner creates a poor decomposition, every later agent may optimize the wrong task. Verifiers can agree with convincing but false answers. Synthesis can remove uncertainty expressed by individual agents.
Privacy is another concern. Excluding selected providers helps, but organizations still need clear information about retention, regional processing, logging, and whether prompts are exposed to every participating model.
The final challenge is observability. One API simplifies integration, but it can make the internal reasoning path harder to audit unless detailed traces are available.
Simple Explanation for Beginners
Imagine asking one expert to solve a difficult problem.
A normal AI model works that way.
Fugu can instead build a temporary team. One AI creates the plan, another completes the technical work, and another checks the result. Fugu then combines their work into one answer.
That can improve quality, but more experts also mean more time, more communication, and potentially more cost.
Conclusion: Sakana AI Fugu
Sakana AI Fugu makes multi-agent orchestration easier by hiding model selection, delegation, verification, and synthesis behind one compatible API.
Sakana’s reported results suggest that Fugu Ultra can outperform individual frontier models on selected coding and scientific benchmarks. However, the gains are relatively narrow in some comparisons, the baselines are partly provider-reported, and the evaluations have not yet been independently reproduced under fully equivalent settings.
Fugu is most compelling for complex, high-value tasks where one model is likely to miss something and additional verification is worth the cost.
It is less convincing for simple requests that one capable model can answer quickly.
Final Takeaways
- Sakana AI released Fugu and Fugu Ultra on June 22, 2026.
- Fugu exposes multi-agent orchestration through one OpenAI-compatible API.
- It manages model selection, subtask delegation, verification, and response synthesis.
- Fugu is more advanced than simple model routing because it can coordinate several agents over multiple turns.
- Sakana reports 95.1 on GPQA Diamond, 93.2 on LiveCodeBench v6, and 54.2 on SWE-Bench Pro for Fugu Ultra.
- Competing benchmark scores were partly taken from model providers rather than reproduced under one uniform setup.
- Fugu Ultra costs $5 per million input tokens and $30 per million output tokens.
- Hidden orchestration tokens are billed and can increase total cost and latency.
- Customers can exclude specific providers from the agent pool.
- Independent benchmark replication and production latency data are still needed.
Suggestions Read:
- AI Agents Can Now Work for Hours
- Best AI Models for Coding
- AI Agent Frameworks Compared
- Claude Code vs OpenAI Codex
- China’s Cheap AI Model Is Making Claude Look Expensive
FAQ: Sakana AI Fugu
What is Sakana AI Fugu?
Sakana Fugu is a multi-agent orchestration system delivered through one model API. It can select and coordinate several AI models to plan, execute, verify, and combine complex work.
How does Fugu Ultra work?
Fugu Ultra uses a deeper pool of agents for difficult tasks. Its orchestrator determines which models participate, what roles they receive, what information they see, and how their results are verified and synthesized.
Is Fugu just an AI model router?
No. A router normally selects one model. Fugu can coordinate multiple agents across several turns and assign planning, execution, or verification roles.
Can multiple AI agents beat one frontier model?
Sakana reports that Fugu Ultra exceeds listed single-model baselines on selected benchmarks. However, the release results are provider-run and have not yet been independently reproduced under fully equivalent settings.
How much does Fugu Ultra cost?
Fugu Ultra currently costs $5 per million input tokens and $30 per million output tokens, with higher rates for contexts above 272,000 tokens. Orchestration tokens are also included in the bill.
Is Sakana Fugu suitable for private business data?
It may be suitable for some businesses because users can exclude specific providers from the model pool. Organizations should still review retention, data-processing, compliance, and regional-availability terms before sending sensitive material.
References:
- Sakana AI’s June 22 Fugu and Fugu Ultra release announcement.
- Official Sakana Fugu product and architecture page.
- Sakana Fugu Technical Report.
- Sakana AI’s Fugu beta announcement and early benchmark table.
- Trinity research paper on lightweight LLM coordination.
- Conductor research explanation and orchestration workflow.
- Official Fugu pricing documentation.