
Prime Intellect Can Now Train Trillion-Parameter AI Agents on Real Coding Work
Prime Intellect released prime-rl 0.6.0 on June 21, 2026, expanding its open-source reinforcement-learning framework to support trillion-parameter mixture-of-experts models on demanding agentic workloads.
The release matters because training an AI coding agent is much harder than training a model to answer one short question. An agent may inspect repositories, call tools, run tests, read long command outputs, recover from errors, and continue for hundreds of turns.
Prime Intellect reports that prime-rl 0.6.0 trained GLM-5.1 on software-engineering tasks with contexts reaching 131,000 tokens, a batch size of 256 rollouts, and step times below five minutes across 28 H200 nodes. That result demonstrates systems throughput, not an independently verified improvement in coding accuracy.
What Is prime-rl 0.6.0?
prime-rl is an open-source framework for reinforcement-learning post-training.
Its purpose is to let researchers place a pretrained model inside an environment, generate task attempts called rollouts, score those attempts, and update the model so it becomes more likely to repeat successful behavior.
The repository supports supervised fine-tuning, reinforcement learning, evaluations, multimodal models, software-engineering environments, Slurm clusters, and Kubernetes deployments. Prime Intellect says it is designed to scale beyond 1,000 GPUs and supports large MoE families including GLM, Qwen, Nemotron, MiniMax, GPT-OSS, and its own INTELLECT models.
The 0.6.0 release focuses on making that process efficient when both the model and the agent trajectory are extremely large.
Why Agentic RL Is a Different Systems Problem
Traditional reinforcement-learning examples often generate relatively short answers.
Software-engineering agents behave differently. One rollout may finish quickly, while another can continue for hours as the model edits files, uses tools, receives sandbox output, and retries failed approaches.
In synchronous RL, the trainer may wait for every rollout in a batch to finish before updating the model. One unusually slow trajectory can therefore leave expensive training GPUs idle.
prime-rl uses asynchronous reinforcement learning. Training and inference run as separate systems, and new model weights can be distributed after an optimizer step without waiting for every old rollout to finish. Requests generated by policies that have become too old can be discarded through an off-policy limit.
This keeps the training pipeline moving, but it also creates a challenge: parts of one rollout may have been generated by different policy versions.
How the prime-rl 0.6.0 Architecture Works
The workflow can be simplified into six stages:
- A software-engineering environment gives the model a task.
- Distributed inference workers generate agent trajectories.
- Tools or sandboxes return code, logs, tests, and other observations.
- A verifier assigns rewards to the completed trajectories.
- The trainer updates the model using rewarded behavior.
- New weights are sent back to inference while other rollouts continue.
Prime Intellect’s Verifiers library packages the dataset, model harness, tools, sandboxes, context-management rules, and reward function required for each environment.
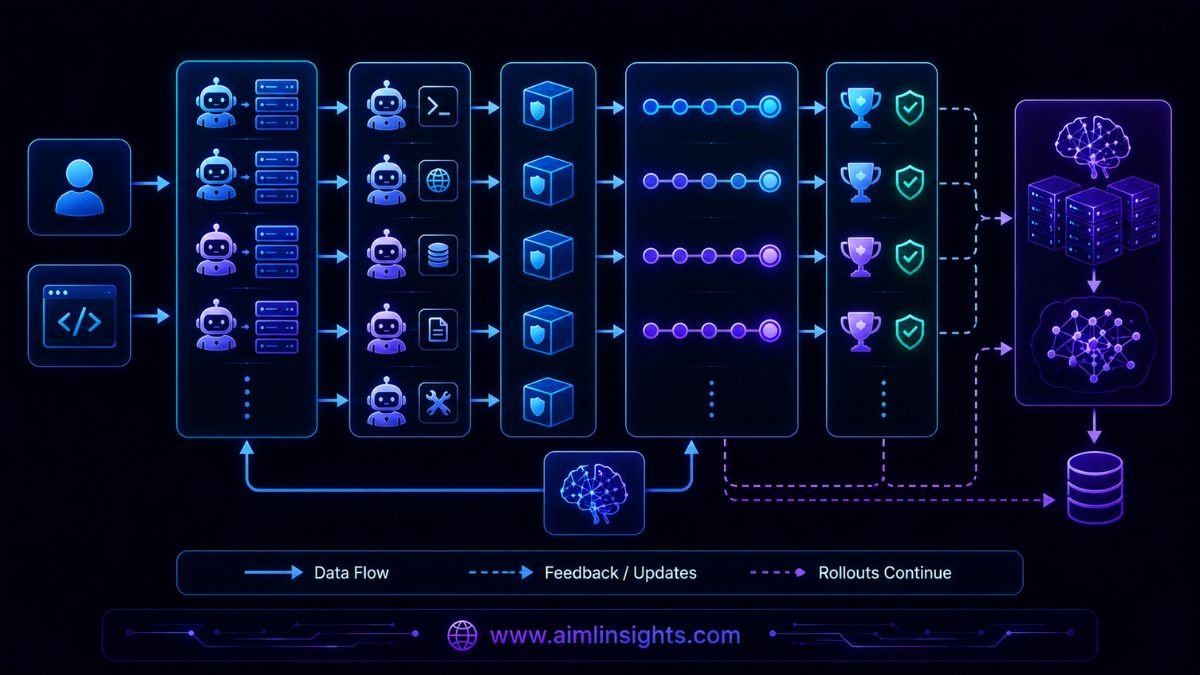
The difficult part is keeping every component fast and mathematically consistent while hundreds or thousands of long trajectories are active.
Expert Parallelism Makes Trillion-Parameter MoE Training Fit
GLM-5.1 is a mixture-of-experts model. Instead of activating every parameter for every token, a routing system selects a subset of expert networks.
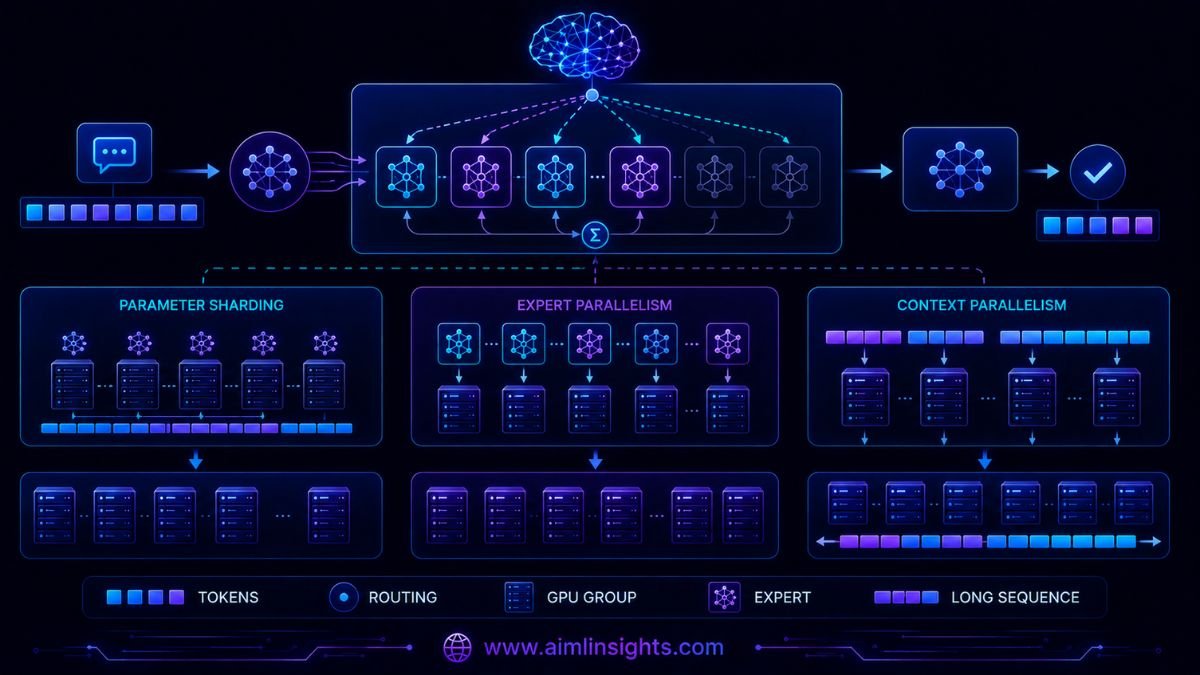
That improves computational efficiency, but the total model remains too large for one GPU.
prime-rl combines three distribution methods:
- FSDP2 shards parameters, gradients, and optimizer states.
- Expert parallelism distributes different experts across GPUs.
- Context parallelism splits long token sequences across devices.
Prime Intellect explains that gathering one full expert-heavy layer could require roughly 40GB, with overlapping operations potentially doubling that requirement. Expert parallelism avoids gathering every expert onto each GPU; tokens are sent to the machines holding the selected experts instead.
At 131,000-token contexts, activations become another major memory problem. Context parallelism reduces the burden by distributing the sequence itself.
Why Prefill and Decode Are Separated
Agentic workloads repeatedly alternate between reading context and generating new tokens.
Prefill processes the prompt and accumulated context. Decode generates the next tokens.
Prime Intellect reports that some model-environment combinations produce a prefill-to-decode token ratio as high as four to one. If the same workers handle both phases, long tool outputs can delay token generation for every active agent.
prime-rl separates prefill and decode workers. Long repository contents or terminal logs can be processed without blocking agents that are ready to generate their next action.
This matters because even a small delay is multiplied across potentially hundreds of tool-use turns.
KV-Cache Offloading Keeps More Rollouts Active
Transformer inference stores reusable attention information in a KV cache.
Long contexts and high concurrency can fill GPU memory quickly. When that happens, cache entries may be repeatedly removed and recomputed, reducing throughput.
prime-rl supports cache offloading through Mooncake Store and routes requests according to factors such as cache reuse, queue depth, and current worker load. A centralized cache layer can allow separate replicas to reuse matching prefixes instead of performing the same prefill work repeatedly.
This is especially useful when many software tasks share large system prompts, tool descriptions, or repository prefixes.
Router Replay Reduces MoE Training Mismatch
A mixture-of-experts model routes each token to selected experts.
During inference, one route may be chosen. During training, numerical or implementation differences can cause the trainer to choose another route. That mismatch changes the probability distribution being optimized and can destabilize reinforcement learning.
Prime Intellect’s router replay, called R3, records the expert-routing decisions made during inference and replays them during training. The company reports that this reduces trainer-inference KL mismatch by an order of magnitude.
The trade-off is data movement. Routing records can reach tens of gigabits per second and grow to hundreds of gigabytes across layers, experts, and long sequences.
That makes router replay a significant engineering system, not a lightweight logging feature.
Why prime-rl Uses FP8 Training
FP8 represents numbers with eight bits instead of the higher-precision formats often used during training.
It is tempting to assume FP8 is included mainly to make training faster. Prime Intellect says that is not the primary benefit here. Quantization overhead can cancel some throughput gains.
Instead, prime-rl uses block-scaled FP8 with DeepGEMM kernels so training and inference operate with more closely matched numerical behavior. That reduces the divergence between the policy that generated a rollout and the policy being optimized.
In other words, FP8 is being used partly as a consistency tool.
Benchmark Audit: What Was Actually Demonstrated?
| Evaluation | Metric | Reported result | Baseline | Owner | Independently verified? |
| GLM-5.1 SWE training | Maximum rollout context | Up to 131,000 tokens | Not provided | Prime Intellect | No |
| Distributed RL step | Wall-clock step time | Below five minutes | No prior-version comparison disclosed | Prime Intellect | No |
| Rollout batch | Trajectories per step | 256 | Not provided | Prime Intellect | No |
| Hardware scale | Training cluster | 28 H200 nodes | Not provided | Prime Intellect | Hardware configuration reported by provider |
| Router replay | Trainer-inference KL mismatch | About one order-of-magnitude reduction | Replay disabled | Prime Intellect | No independent reproduction cited |
The release does not report:
- SWE-Bench improvement after training
- Reward curves for the GLM-5.1 run
- Accepted-patch rates
- Cost per optimizer step
- Power consumption
- Cluster failure frequency
- Comparison with the same workload on prime-rl 0.5.x
- Comparison with other RL frameworks under equivalent settings
The results should therefore be read as a provider-reported systems demonstration, not a model-performance benchmark.
How It Compares With Existing RL Stacks
prime-rl operates in the same broad category as frameworks such as verl, NeMo-RL, OpenRLHF, and other large-scale post-training systems.
Its stated differentiator is a stack designed specifically around long, tool-using agent trajectories: asynchronous rollouts, integrated environments, separate inference and training deployments, MoE router replay, long-context parallelism, and built-in SWE support.
A conventional synchronous framework may be easier to reason about and reproduce for small models. prime-rl becomes more relevant when rollout times are irregular, models are enormous, and wasted accelerator time becomes financially significant.
Why This Matters
The release could make experimentation with open trillion-parameter models more accessible to well-funded research teams.
It does not make this work cheap. Twenty-eight H200 nodes still represent substantial infrastructure, networking, operational expertise, and electricity.
But a reusable open framework can reduce the amount of custom engineering required before a lab can begin testing agentic post-training.
That may help open-model developers compete in an area where proprietary labs have historically benefited from private distributed-training systems.
Limitations and Unanswered Questions
prime-rl 0.6.0 remains infrastructure for specialists.
Researchers need NVIDIA GPUs, distributed storage, high-bandwidth networking, Slurm or Kubernetes knowledge, environment design, reward functions, and secure sandboxes. The repository says at least one NVIDIA GPU is required even for basic usage.
Asynchronous RL can also introduce off-policy instability. Incorrect rewards may teach agents to exploit the evaluator rather than solve the intended task. Long software rollouts can execute unsafe code or expose private repositories if sandboxes and access controls are weak.
Fault tolerance and elastic scaling are still listed as future work. Prime Intellect is also exploring faster weight transfer, speculative decoding, and lower-precision NVFP4 support, suggesting that the current stack remains under active development.
The largest unanswered question is whether this infrastructure efficiency produces reliably better agents per dollar—not simply faster training steps.
Simple Explanation for Beginners
Imagine training hundreds of AI developers at once.
Some finish quickly. Others spend hours debugging. A normal training system may wait for the slowest developer before teaching the whole group.
prime-rl lets the completed work update the model while slower agents continue. It also spreads the giant model, long code histories, and cached information across many GPUs.
The result is not a new AI agent by itself. It is a faster and more practical training factory for building one.
Conclusion: Prime-rl 0.6.0 Scales Agentic RL
prime-rl 0.6.0 is an ambitious infrastructure release for agentic reinforcement learning at trillion-parameter scale.
Its combination of asynchronous RL, expert and context parallelism, FP8 consistency, prefill/decode separation, KV-cache offloading, and router replay addresses real bottlenecks in long-context coding-agent training.
Prime Intellect’s GLM-5.1 demonstration is technically significant, but it remains company-reported. Independent reproduction, cost analysis, model-quality results, and direct framework comparisons are still needed.
The release shows that the next competition in AI agents is not only about model architecture. It is also about who can train those agents efficiently on long, messy, real-world work.
Final Takeaways
- Prime Intellect released prime-rl 0.6.0 on June 21, 2026.
- It targets trillion-parameter MoE models and long-running agent workloads.
- Prime Intellect reports 131,000-token SWE rollouts and sub-five-minute steps on 28 H200 nodes.
- Asynchronous RL avoids waiting for the slowest trajectory in every batch.
- Expert parallelism distributes MoE experts across GPUs.
- Prefill/decode separation prevents long tool outputs from blocking generation.
- KV-cache offloading improves reuse and concurrency.
- Router replay aligns inference routing with training.
- FP8 is used partly to reduce trainer-inference mismatch.
- No independent model-quality improvement has yet been demonstrated.
Suggested Read:
- China’s Cheap AI Model Is Making Claude Look Expensive
- AI Agents Can Now Work for Hours
- GLM-5.1 AI Model Explained
- Claude Cowork Explained
- Latest AI News Today
FAQ: Prime-rl 0.6.0 Scales Agentic RL
What is prime-rl 0.6.0?
prime-rl 0.6.0 is an open-source reinforcement-learning framework from Prime Intellect designed for large-scale agentic post-training, including trillion-parameter mixture-of-experts models.
How does asynchronous agentic RL work?
Inference workers continuously generate trajectories while a separate trainer updates the model. The system does not need to wait for every long-running rollout before beginning the next optimization step.
What is router replay in prime-rl?
Router replay records which experts an MoE model selected during inference and uses the same routing choices during training, reducing mismatch between the two systems.
Why does prime-rl use FP8 training?
Prime Intellect says FP8 makes training numerically closer to FP8 inference, reducing policy mismatch and improving stability. It does not always produce a major throughput increase.
What hardware does prime-rl 0.6.0 require?
Basic experiments require at least one NVIDIA GPU. The reported GLM-5.1 demonstration used 28 H200 nodes, while the framework is designed to support clusters exceeding 1,000 GPUs.
Can prime-rl train trillion-parameter models?
Prime Intellect says the framework supports 1T-plus MoE models and demonstrated GLM-5.1 agentic RL at large scale. The reported performance has not yet been independently reproduced.
References:
- Prime Intellect’s official prime-rl 0.6.0 performance deep dive.
- Official prime-rl GitHub repository and technical overview.
- Official Verifiers repository for environments, harnesses, and reward functions.
- Prime Intellect’s Environments Hub overview.
- vLLM reinforcement-learning and asynchronous-inference documentation.