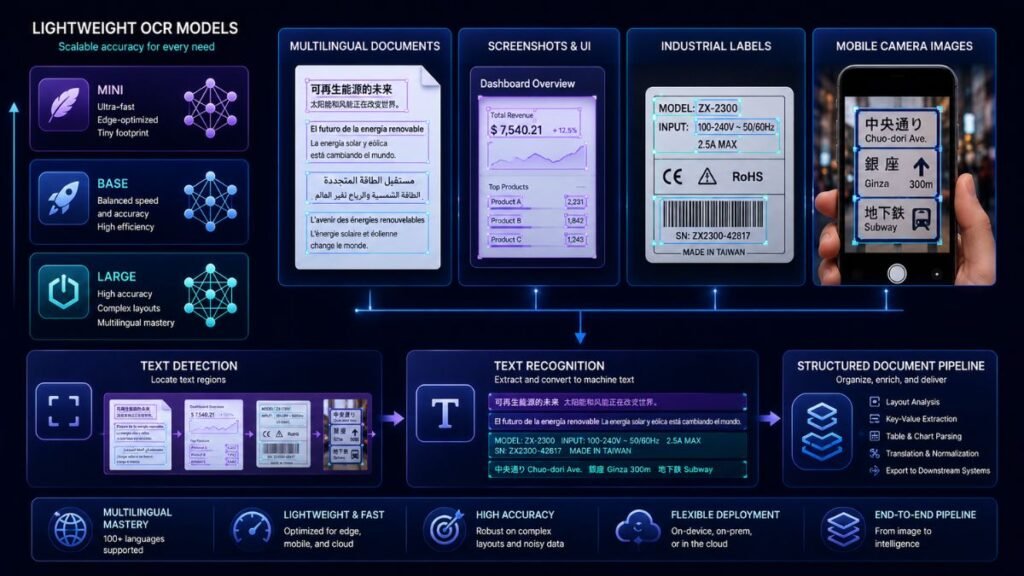
PP-OCRv6 Brings 50-Language OCR to Models Small Enough for Phones
PaddleOCR released PP-OCRv6 as part of version 3.7.0 on June 11, 2026, introducing three lightweight model tiers for multilingual text detection and recognition. The family ranges from a 1.5-million-parameter tiny model to a 34.5-million-parameter medium model, with deployment paths spanning PaddlePaddle, Hugging Face Transformers, ONNX Runtime, CPUs, mobile devices, and servers.
The release matters because OCR remains a basic requirement for invoices, identity documents, industrial labels, screenshots, scanned forms, product packaging, and RAG ingestion. Large vision-language models can read images, but they may be too expensive or slow for high-volume extraction.
PaddleOCR reports that PP-OCRv6_medium reaches 86.2% detection Hmean and 83.2% recognition accuracy on its internal multi-scenario OCR evaluation. Those are promising results, but they were generated by the model provider and are not directly comparable with every older model table because the evaluation sets differ.
What Is PP-OCRv6?
PP-OCRv6 is the newest generation of PaddleOCR’s lightweight OCR family.
It is not one model. It is a complete two-stage OCR system with separate components for:
- Text detection, which finds the location and shape of text inside an image.
- Text recognition, which converts each detected crop into characters.
This separation is important. A recognizer may be highly accurate on a clean crop but still fail in a complete pipeline if the detector misses small text, cuts characters, or includes too much background.
PP-OCRv6 uses a common PPLCNetV4 backbone across detection and recognition, with specialized components for each task. The detection path adds RepLKFPN, while the recognition path uses an EncoderWithLightSVTR design and CTC/NRTR training heads.
The Three PP-OCRv6 Model Sizes
| Model tier | Parameters | Detection Hmean | Recognition accuracy | Language support | Best use |
| PP-OCRv6_tiny | 1.5M | 80.6% | 73.5% | 49 languages | Edge devices and latency-sensitive OCR |
| PP-OCRv6_small | 7.7M | 84.1% | 81.3% | 50 languages | Phones, desktops, and balanced local services |
| PP-OCRv6_medium | 34.5M | 86.2% | 83.2% | 50 languages | Servers, industrial OCR, and accuracy-focused ingestion |
The tiny tier is designed for highly constrained environments. It omits the LightSVTR recognition neck and is trained with distillation from the larger model. Small offers a stronger balance between accuracy and compute. Medium is the most capable tier and targets production pipelines where retrieval quality matters more than minimal memory use.
The small and medium models support Simplified Chinese, Traditional Chinese, English, Japanese, and 46 Latin-script languages. Tiny supports 49 languages because Japanese is excluded.
How Text Detection Works
Text detection answers the question: Where is the text?
PP-OCRv6 uses PPLCNetV4 to build visual features at multiple scales. The RepLKFPN detection neck then combines those features so the model can locate large headings, small labels, dense document text, rotated lines, and scene text.
The architecture uses a larger effective receptive field than the earlier feature-pyramid component while reducing neck parameters. PaddleOCR says RepLKFPN uses reparameterized large-kernel depthwise convolutions and reduces neck parameters by 31% compared with the previous RSEFPN design.
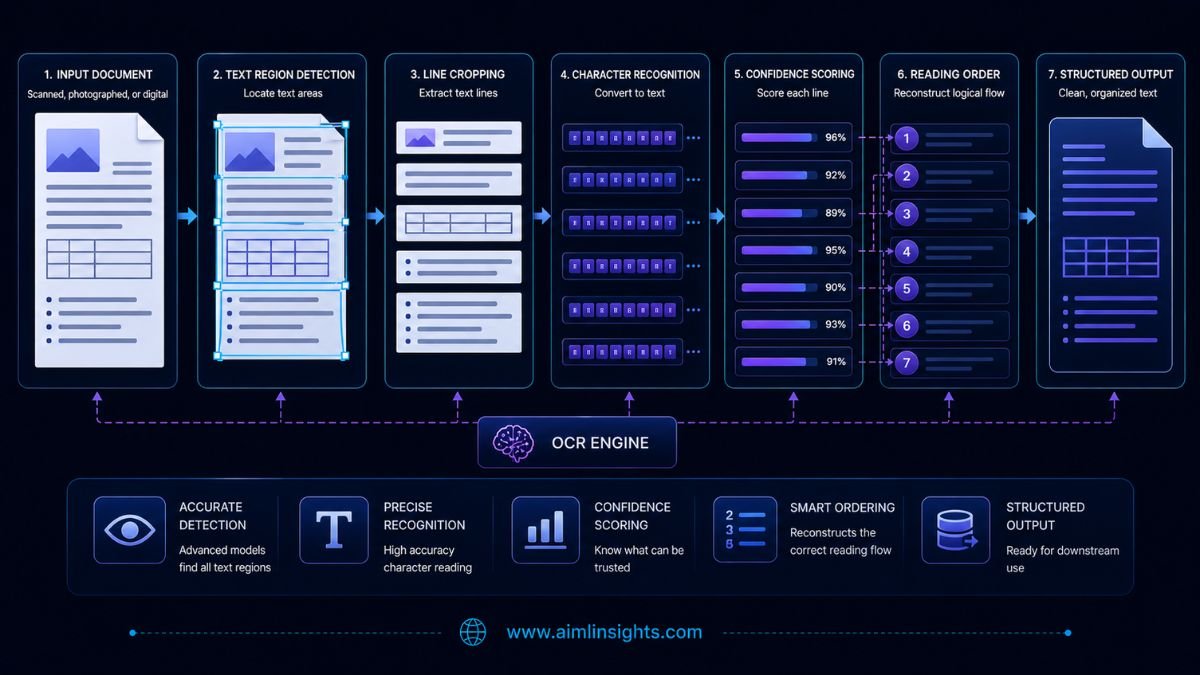
Detection produces polygons or boxes. Those regions are then cropped, optionally corrected for rotation, and passed to the recognizer.
A weak detector affects everything downstream. That is why developers should test both detection recall and recognition accuracy rather than evaluating only final text strings.
How Text Recognition Works
Recognition answers the second question: What does the detected text say?
PP-OCRv6’s recognition architecture combines local and global context. Local convolutions help capture character shapes and nearby patterns, while a lightweight Transformer layer models longer relationships across the text line.
During training, it uses a multi-head decoder:
- CTC supports efficient parallel decoding.
- NRTR provides additional training supervision.
- The NRTR branch is removed during inference.
This gives the model richer training signals without requiring the full decoder at runtime.
The medium recognition model reports 83.2% average accuracy on PaddleOCR’s internal multi-scenario set. Small reports 81.3%, while tiny reports 73.5%.
What Is Genuinely New?
PP-OCRv6 advances the family in four practical areas.
First, it introduces a unified PPLCNetV4 backbone for detection and recognition.
Second, it expands one-model multilingual coverage. Earlier multilingual OCR deployments often required switching recognition models by language. PP-OCRv6 small and medium can handle 50 supported languages in one model.
Third, it improves specialized text recognition for digital displays, dot-matrix characters, tire markings, and industrial text—areas where general-purpose vision-language models may struggle.
Fourth, it is integrated into multiple inference ecosystems, including PaddlePaddle, Transformers, ONNX model formats, and mobile ONNX Runtime examples.
Using PP-OCRv6 Through Transformers
PaddleOCR now supports selecting Transformers as the inference engine.
The official quick start requires a recent Transformers version and lets developers switch engines through the command line:
python -m pip install “transformers>=5.8.0”
python -m pip install “paddleocr[all]”
paddleocr ocr \
-i ./document.png \
–use_doc_orientation_classify False \
–use_doc_unwarping False \
–use_textline_orientation False \
–engine transformers
The same OCR command can use the Paddle backend by changing the engine value. This reduces integration friction for teams already using Hugging Face tooling.
Transformers compatibility does not mean every environment will have identical speed. Runtime performance depends on model format, hardware, threading, quantization, preprocessing, and backend optimization.
ONNX Runtime and Mobile Deployment
PaddleOCR also provides ONNX models and an Android PP-OCRv6 example based on ONNX Runtime.
The Android design separates the reusable OCR SDK from the demonstration application. It includes both detection and recognition models, stage-level timing, Jetpack Compose integration, and AAR packaging for third-party applications.
This makes ONNX Runtime relevant for:
- Android scanning apps
- Offline receipt recognition
- Mobile inventory tools
- Industrial handheld devices
- Embedded document capture
- Privacy-sensitive local OCR
ONNX can simplify cross-platform inference, but developers still need to reproduce the same preprocessing, box sorting, cropping, decoding, and character dictionary behavior used by the original pipeline.
CPU and Paddle Deployment
PP-OCRv6 can run through the standard PaddleOCR stack on CPU or GPU. The official quick start provides a CPU installation for PaddlePaddle 3.2.0 and states that PaddleOCR 3.x requires PaddlePaddle 3.0 or later for Paddle inference.
Paddle’s own runtime remains attractive when teams want:
- Official pipeline compatibility
- Hardware-specific acceleration
- Training and fine-tuning support
- Integrated document preprocessing
- Paddle-specific high-performance plugins
PaddleOCR also reports substantial CPU and device-specific speedups, including a 5.2× OpenVINO acceleration claim for the medium model and a 6.1× improvement for tiny on Apple M4. Those are provider-reported implementation results, and actual application speed will depend on image size, batch size, hardware, and enabled preprocessing stages.
Benchmark Audit
| Metric | PP-OCRv6_tiny | PP-OCRv6_small | PP-OCRv6_medium | Reported baseline | Evaluation owner | Independently verified? |
| Detection Hmean | 80.6% | 84.1% | 86.2% | PP-OCRv5_server | PaddleOCR | No |
| Recognition accuracy | 73.5% | 81.3% | 83.2% | PP-OCRv5_server | PaddleOCR | No |
| Reported detection gain | — | — | +4.6 points | PP-OCRv5_server | PaddleOCR | No |
| Reported recognition gain | — | — | +5.1 points | PP-OCRv5_server | PaddleOCR | No |
The benchmark requires careful interpretation.
PaddleOCR’s recognition documentation explicitly warns that PP-OCRv6 metrics were measured on an internal multi-scenario set, while some PP-OCRv5 metrics shown elsewhere came from a different general evaluation set. Those figures are therefore not always directly comparable across tables.
Important missing details include:
- Public per-language accuracy
- Independent document-benchmark results
- False detection rates by document type
- Accuracy after ONNX conversion
- CPU latency under equivalent settings
- Performance on handwriting by language
- Memory use across the three tiers
- Results on long, curved, or heavily degraded text
The claim that the medium model surpasses much larger vision-language systems is also task-specific. A specialized OCR model may outperform a VLM on detection and transcription while lacking layout reasoning, visual question answering, chart interpretation, or document-level understanding.
Which PP-OCRv6 Model Should You Use?
Use tiny when:
- The device has strict memory limits
- Offline processing is required
- Speed matters more than maximum accuracy
- Inputs are relatively clean
- Japanese support is not required
Use small when:
- You need all 50 supported languages
- The application runs on a phone, laptop, or small server
- You need a balanced production model
- Moderate OCR errors can be reviewed downstream
Use medium when:
- OCR quality directly affects RAG or business automation
- The application processes industrial or complex text
- Server or workstation compute is available
- A few extra accuracy points justify greater latency
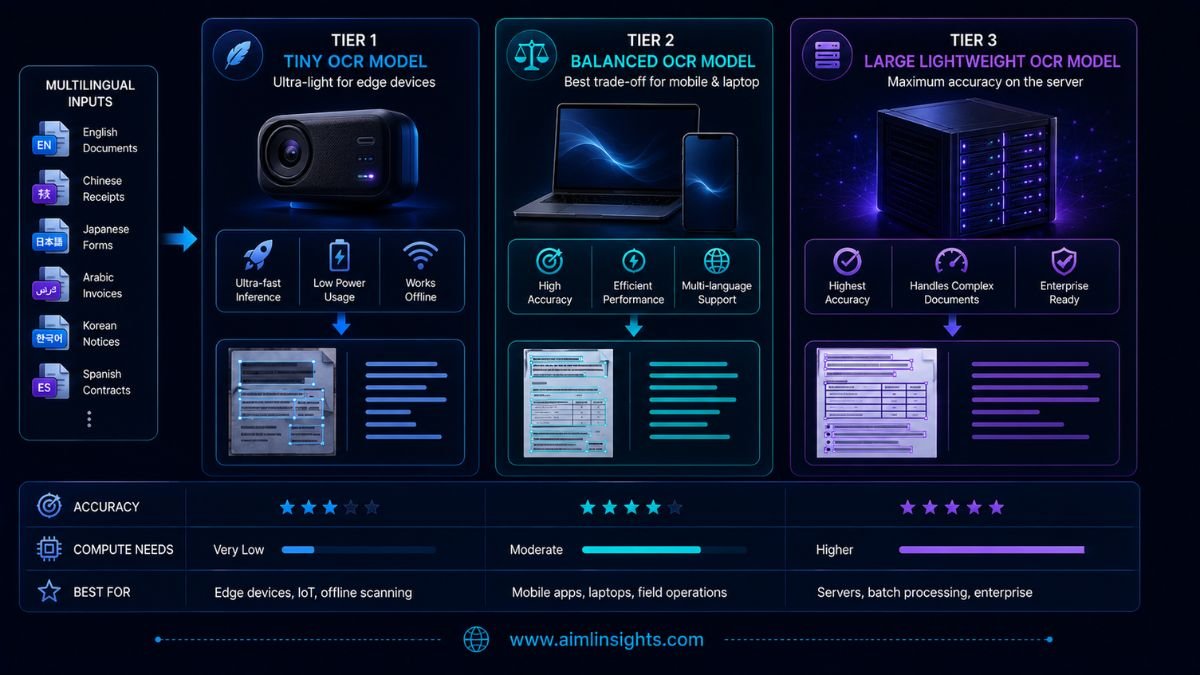
Why This Matters for Document Processing
OCR errors propagate.
A missed invoice number can break reconciliation. A wrong product code can corrupt inventory. A mistranscribed clause can affect contract search. A poor text crop can reduce the quality of every later embedding or LLM answer.
Small specialized models are valuable because they can run close to the data, reduce cloud dependency, and process high document volumes at lower cost.
Common workloads include:
- Invoice and receipt extraction
- Identity and application forms
- Multilingual document search
- Screenshot indexing
- Manufacturing labels
- Equipment displays
- Tire and component markings
- Local RAG ingestion
- Mobile scanning
PP-OCRv6 is less suitable when the task requires tables, charts, formulas, reading order, or complete document structure. PaddleOCR’s PP-StructureV3 is designed for broader layout and document parsing.
Limitations and Deployment Risks
PP-OCRv6 is lightweight, but production OCR still requires substantial engineering.
Developers must handle:
- Image rotation
- Perspective correction
- Document unwarping
- Very small text
- Mixed scripts
- Confidence thresholds
- Duplicate boxes
- Reading order
- Unsupported languages
- Sensitive document storage
- Human review for critical fields
Language support also does not guarantee equal accuracy across all 50 languages. Public per-language benchmark detail is limited in the release material.
OCR confidence scores should not be treated as proof that a field is correct. Critical values such as account numbers, medical information, or legal clauses should pass validation rules or human review.
Simple Explanation for Beginners
OCR has two jobs.
First, it draws boxes around words.
Second, it reads the words inside those boxes.
PP-OCRv6 provides small, medium, and larger lightweight versions of both jobs. The smallest model is easier to run on a phone. The largest is more accurate but needs more computing power.
What Comes Next
The most useful next step would be broader independent testing across public multilingual document sets.
Developers also need benchmark results comparing Paddle, Transformers, ONNX Runtime, OpenVINO, and mobile backends under equivalent hardware and image settings.
Future releases could improve script coverage, expose clearer per-language metrics, and integrate more tightly with document-layout pipelines.
Conclusion: PP-OCRv6 Explained
PP-OCRv6 gives developers a flexible multilingual OCR family spanning edge, mobile, desktop, and server deployment.
The 1.5M model prioritizes efficiency. The 7.7M tier offers a practical balance. The 34.5M model delivers the strongest provider-reported detection and recognition results.
Its Transformers and ONNX support make deployment easier, but benchmark caution remains essential. The reported accuracy gains come from PaddleOCR’s own internal evaluation, and production quality will depend on language, image conditions, preprocessing, and the complete detection-recognition pipeline.
Final Takeaways
- PP-OCRv6 was released with PaddleOCR 3.7.0 on June 11, 2026.
- It includes 1.5M, 7.7M, and 34.5M parameter tiers.
- Small and medium support 50 languages.
- Tiny supports 49 languages and excludes Japanese.
- Detection locates text; recognition converts crops into characters.
- The family uses PPLCNetV4 across both stages.
- PaddleOCR reports 86.2% detection Hmean and 83.2% recognition accuracy for medium.
- The benchmark results are provider-reported and use an internal evaluation set.
- PP-OCRv6 supports PaddlePaddle, Transformers, ONNX formats, CPUs, and mobile deployment.
- Medium is best for accuracy-focused pipelines; tiny is best for constrained devices.
Suggested Read:
- How OCR Works
- China’s Cheap AI Model Is Making Claude Look Expensive
- AI Agents Can Now Work for Hours
- Claude Cowork Explained
- Best AI Models for Document Processing
- Local AI Models Guide
- RAG Document Ingestion Explained
- Latest AI Model Releases
FAQ: PP-OCRv6 Explained
What is PP-OCRv6?
PP-OCRv6 is PaddleOCR’s lightweight multilingual OCR family for text detection and recognition. It includes tiny, small, and medium model tiers.
How many languages does PP-OCRv6 support?
The small and medium tiers support 50 languages. The tiny tier supports 49 and does not include Japanese.
What is the difference between OCR detection and recognition?
Detection finds where text appears in an image. Recognition reads the characters inside each detected region.
Which PP-OCRv6 model should I use?
Use tiny for highly constrained edge devices, small for balanced phone or desktop deployments, and medium when recognition quality matters most.
Can PP-OCRv6 run on a CPU?
Yes. PaddleOCR provides CPU installation and deployment options, while ONNX Runtime and optimized backends can support local and mobile inference.
Does PP-OCRv6 work with Transformers?
Yes. PaddleOCR supports Transformers as an inference engine and documents command-line usage with –engine transformers.
References:
- PaddleOCR’s official PP-OCRv6 release notes.
- PaddleOCR’s official PP-OCRv6 technical documentation.
- The official Hugging Face PP-OCRv6 release article.
- PaddleOCR’s text-recognition model documentation and benchmark caveat.
- PaddleOCR’s Transformers and Paddle quick-start guide.
- The official PP-OCRv6 Android ONNX Runtime deployment guide.
- PaddleOCR’s main GitHub repository.