Liquid AI’s 350M Models Bring Multilingual Search to Laptops
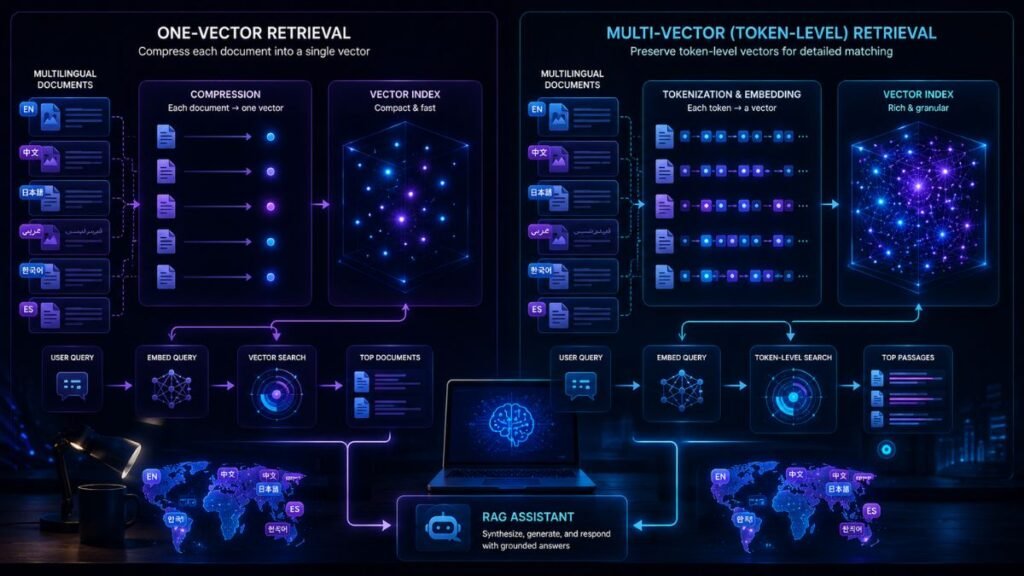
Liquid AI released two compact retrieval models on June 18, 2026, giving developers a choice between fast dense embeddings and more precise token-level retrieval.
LFM2.5 Embedding 350M converts each document into one vector, making it suitable for low-cost semantic search and large indexes. Its companion, LFM2.5-ColBERT-350M, preserves a separate representation for each token and uses late interaction to compare queries with documents more precisely.
The models matter to developers building multilingual RAG systems, product search, support assistants, local document search, and edge applications. Liquid reports NanoBEIR multilingual NDCG@10 scores of 0.577 for the embedding model and 0.605 for ColBERT, but those benchmark results were produced by the model provider and have not yet been independently replicated.
What Is LFM2.5 Embedding 350M?
LFM2.5-Embedding-350M is a dense bi-encoder built on Liquid AI’s LFM2.5-350M backbone.
A bi-encoder processes queries and documents independently. Each document becomes one fixed-size vector, and each query becomes another vector. Retrieval then uses cosine similarity or normalized dot product to find documents whose vectors are closest to the query.
Liquid’s model produces a 1,024-dimensional CLS vector for each query or document. It supports documents up to 512 tokens and uses separate query and document prompts.
This approach is attractive because document vectors can be calculated once and stored in a standard vector database. At search time, only the query needs to be embedded.
The result is a small, fast, and operationally simple index.
How LFM2.5-ColBERT-350M Works
LFM2.5-ColBERT-350M uses the same general 350M-parameter backbone but represents text differently.
Instead of collapsing an entire passage into one vector, it creates a 128-dimensional vector for each token. A query is also represented at token level.
The model then uses MaxSim late interaction. For every query token, the system finds the most similar token in the document and combines those scores.
This helps preserve fine-grained matches that may disappear inside one dense document vector.
For example, a user searching for “battery overheating after firmware update” may benefit when the retriever separately recognizes the significance of “battery,” “overheating,” and “firmware update,” rather than compressing the entire sentence into one representation. Liquid recommends ColBERT when ranking quality and generalization matter more than index size.
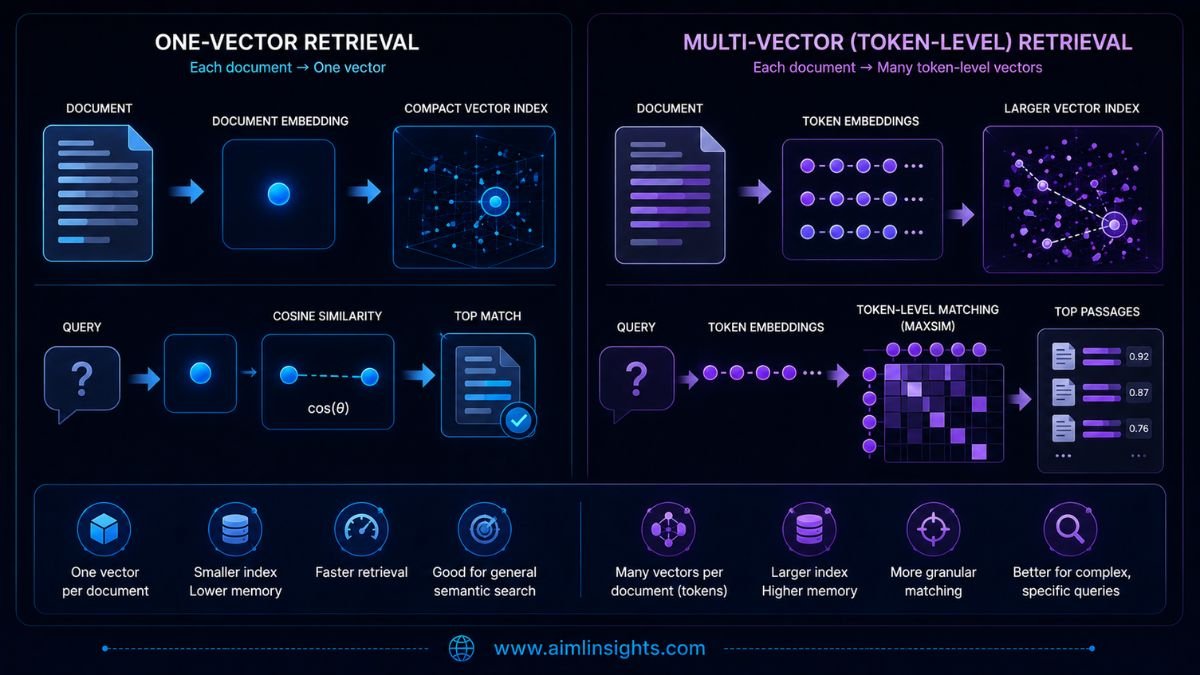
Dense Embeddings vs ColBERT Late Interaction
| Feature | LFM2.5-Embedding-350M | LFM2.5-ColBERT-350M |
| Representation | One vector per document | One vector per token |
| Vector size | 1,024 dimensions | 128 dimensions per token |
| Similarity method | Cosine similarity | MaxSim |
| Index footprint | Smaller | Larger |
| Search architecture | Standard vector retrieval | Multi-vector late interaction |
| Main advantage | Speed and storage efficiency | Higher retrieval precision |
| Best fit | Large catalogs, local search, first-stage retrieval | Reranking, high-value RAG, detailed matching |
The storage difference can be substantial.
A dense system stores one vector for every chunk. A ColBERT system may store dozens or hundreds of token vectors for the same chunk. Even though each ColBERT vector has fewer dimensions, the total index can still become much larger.
The exact storage requirement depends on average document length, quantization, compression, token filtering, and index format. Liquid does not publish one universal storage multiplier because deployment choices vary.
What Is Genuinely New?
Liquid AI previously released LFM2-ColBERT-350M. The newer LFM2.5 release changes more than the name.
The company says the new models use the newer LFM2.5 checkpoint, increase language coverage, add explicit multilingual and cross-lingual training, and introduce a dense companion model built with the same architecture and training recipe.
Both are also the first bidirectional members of the LFM family.
Generative language models normally process text causally, meaning each token sees only earlier tokens. Retrieval models benefit from bidirectional attention because every token can use context from both sides.
Liquid adapted the LFM2.5 backbone into a full-context encoder, then trained the models through:
- Large-scale English contrastive pretraining
- Multilingual and cross-lingual distillation
- Fine-tuning with hard-mined negatives
The models support Arabic, German, English, Spanish, French, Italian, Japanese, Korean, Norwegian, Portuguese, and Swedish.
Benchmark Audit
Liquid evaluated the models on NanoBEIR Multilingual Extended and MKQA-11.
| Benchmark | Metric | Embedding model | ColBERT model | Reported difference | Evaluation owner | Independent verification |
| NanoBEIR Multilingual Extended | Average NDCG@10 | 0.577 | 0.605 | ColBERT +0.028 | Liquid AI | Not yet independently reproduced |
| MKQA-11 | Average Recall@20 | 0.691 | 0.694 | ColBERT +0.003 | Liquid AI | Not yet independently reproduced |
NDCG@10 measures how effectively a system places relevant documents near the top of the first ten results. NanoBEIR is a reduced version of the broader BEIR suite, with a maximum of 50 queries per included benchmark. This makes evaluation faster, but also means results may be more sensitive to small dataset changes than a larger production test.
The reported NanoBEIR gain is meaningful but not enormous: 0.605 versus 0.577 is an absolute increase of 0.028, or roughly 4.9% relative to the dense model’s score.
The comparison does not include a full accounting of index size, retrieval throughput, memory usage, or cost at equivalent recall.
Important missing details include:
- Production index sizes for the same corpus
- Query throughput at high concurrency
- Performance after vector quantization
- Recall and latency at equivalent candidate counts
- Results on long documents beyond 512 tokens
- Independent multilingual benchmark submissions
- Accuracy on domain-specific enterprise data
Deployment Through GGUF and llama.cpp
Liquid released GGUF versions of both retrieval models for local execution through llama.cpp. The official model cards include multiple quantization choices.
For ColBERT, the GGUF model can be launched as an embedding server:
llama-server \
-hf LiquidAI/LFM2.5-ColBERT-350M-GGUF \
–embeddings
The application must still compute MaxSim scores over the returned token vectors. ColBERT is not a normal chat model, and serving it through an OpenAI-compatible endpoint does not automatically provide a complete vector index or retrieval engine.
Liquid reports BF16 query-embedding latency of 7.3 milliseconds for the dense model and 8.1 milliseconds for ColBERT on an M4 Max through llama.cpp. Query embedding plus cached-document MaxSim reportedly reached a median of 8.2 milliseconds for ColBERT. These are company-run measurements on a specified short query and document setup, not independent hardware benchmarks.
Which Model Is Better for RAG?
The answer depends on the retrieval stage.
Use LFM2.5-Embedding-350M when:
- The corpus contains millions of chunks
- Index cost matters
- Latency must remain predictable
- A standard vector database is already in place
- Retrieval is the first stage of a larger pipeline
- The application runs on a laptop or edge device
Use LFM2.5-ColBERT-350M when:
- Fine-grained lexical and semantic matches matter
- Wrong retrieval results are expensive
- Multilingual queries must match documents in another language
- The system can afford a multi-vector index
- ColBERT is used to rerank a smaller candidate set
- Tool or API selection requires precise matching
A practical hybrid architecture may use the dense model to retrieve the top 50 or 100 candidates, then use ColBERT to rerank them.
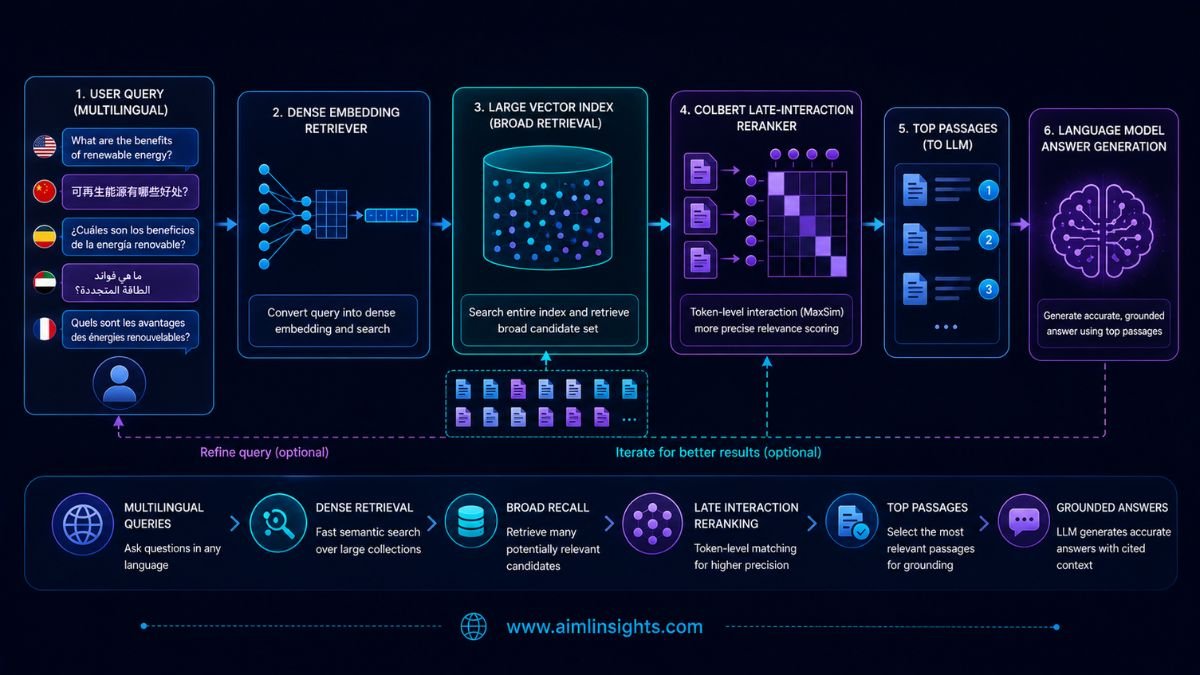
That approach limits the storage and scoring burden while preserving some of the late-interaction quality advantage.
Why This Matters
Retrieval quality often limits the performance of a RAG application more than the final language model.
If the system retrieves the wrong document, a strong generator may still produce a confident but incorrect answer.
Small retrieval models also create new deployment options. A company can keep document embeddings, search traffic, and potentially sensitive queries on local hardware rather than sending them to a hosted embedding API.
This may reduce cloud cost and improve privacy, although local deployment still requires secure storage, access control, logging, and protection of the index itself.
Limitations and Risks
The models are designed primarily for short-context retrieval. The model cards specify a 512-token document length and a 32-token query length for ColBERT. Long reports must therefore be split into chunks. Poor chunking can erase the quality advantage of the retriever.
ColBERT also adds operational complexity:
- More vectors must be stored
- Index construction takes longer
- MaxSim scoring requires specialized retrieval logic
- Database support is less universal
- Updates and deletions are more expensive
- Debugging ranking behavior is harder
The models support 11 languages, not all languages. Performance may also vary across legal, medical, scientific, or highly specialized corpora.
Teams should evaluate on their own queries rather than selecting a model only from the provider’s average benchmark score.
Simple Explanation for Beginners
A dense embedding model turns an entire paragraph into one summary point on a map.
ColBERT keeps a separate point for many individual words.
The summary point is cheaper to store and faster to search.
The word-level map takes more space, but it can notice detailed matches that the summary misses.
Conclusion: LFM2.5 Embedding 350M
LFM2.5 Embedding 350M gives developers a compact option for multilingual semantic search, while LFM2.5-ColBERT-350M offers stronger reported retrieval quality through token-level late interaction.
Liquid’s NanoBEIR results favor ColBERT, but the accuracy gain must be weighed against index size, scoring complexity, and operational cost.
For most large RAG deployments, the dense model is the simpler first-stage retriever. ColBERT is more attractive when retrieval mistakes are costly or as a second-stage reranker over a smaller candidate set.
The release is notable not because one model replaces the other, but because Liquid AI provides two deployment points on the same speed-versus-quality curve.
Final Takeaways
- Liquid AI released both models on June 18, 2026.
- Each model contains about 350 million parameters.
- The dense model stores one 1,024-dimensional vector per document.
- ColBERT stores one 128-dimensional vector per token.
- Liquid reports NanoBEIR NDCG@10 scores of 0.577 and 0.605.
- The benchmark results are provider-reported.
- ColBERT offers higher reported quality but requires a larger index.
- Both support 11 languages and cross-lingual retrieval.
- GGUF versions can run locally through llama.cpp.
- Dense retrieval is simpler for large-scale first-stage search.
- ColBERT is well suited to precision-focused retrieval and reranking.
Suggested Read:
- How RAG Systems Work
- Best Embedding Models for RAG
- ColBERT Explained
- Local AI Models Guide
- Latest AI Model Releases
FAQ: LFM2.5 Embedding 350M
What is LFM2.5 Embedding 350M?
It is a 350M-parameter multilingual dense retrieval model from Liquid AI. It converts each query or document into one 1,024-dimensional vector for cosine-similarity search.
How is ColBERT different from dense embeddings?
Dense embeddings compress a document into one vector. ColBERT creates vectors for individual tokens and scores query-document matches using MaxSim, which preserves more detailed interactions.
Which Liquid AI retrieval model should I use?
Use the embedding model when storage, speed, and standard vector-database compatibility matter most. Use ColBERT when higher retrieval precision justifies a larger, more complex index.
Can LFM2.5 Embedding run locally?
Yes. Liquid provides GGUF variants for llama.cpp, allowing local execution on supported CPUs, laptops, and edge hardware.
What languages do the models support?
They support English, Spanish, German, French, Italian, Portuguese, Arabic, Swedish, Norwegian, Japanese, and Korean.
Is LFM2.5 ColBERT better for RAG?
It may retrieve more relevant passages, especially for precise or multilingual matching, but it requires more storage and specialized MaxSim scoring. Its value should be tested on the target dataset.
References: