
OpenAI’s AI Security Stack Can Find Bugs and Help Patch Them
OpenAI expanded Daybreak, its AI cybersecurity initiative, on June 22, 2026, introducing a more capable version of GPT-5.5-Cyber and a broader workflow for finding, validating, prioritizing, and fixing software vulnerabilities.
The announcement matters because security teams already face more alerts than they can investigate. Daybreak is designed to address the harder bottleneck: turning a possible vulnerability into a reproducible finding, a tested patch, and evidence a human reviewer can trust.
Developers, application-security teams, open-source maintainers, security vendors, and authorized penetration testers should pay close attention. OpenAI reports that the updated GPT-5.5-Cyber achieved 85.6% on CyberGym, compared with 81.8% for GPT-5.5, although that comparison remains company-reported rather than independently verified.
What Is the OpenAI AI Security Stack?
The OpenAI AI security stack is not one product or model.
Daybreak is the wider initiative. It brings together:
- GPT-5.5 for common secure-development work
- GPT-5.5 with Trusted Access for Cyber for verified defensive teams
- GPT-5.5-Cyber for specialized, authorized higher-risk testing
- Codex Security as the agentic scanning and remediation workflow
- Human review, activity logging, monitoring, and scoped permissions
- Security vendors and service partners that can bring these capabilities into existing products
OpenAI describes Daybreak as a system for helping defenders find, validate, and fix vulnerabilities before attackers exploit them. The company says the stack is designed around authorization and human judgment rather than unrestricted autonomous access.
How Codex Security Works
Codex Security begins by connecting to an authorized GitHub repository.
It builds an editable threat model that describes the application, its sensitive components, trust boundaries, and realistic attack paths. Instead of searching only for suspicious code patterns, it uses language-model reasoning, large context, tool use, and test-time computation to investigate whether an issue is genuinely exploitable.
The workflow has five main stages:
- Understand the repository: Codex Security reviews the project and its history.
- Build a threat model: It identifies important assets and probable attack paths.
- Find candidate vulnerabilities: The system focuses analysis on high-impact code.
- Validate findings: It attempts to reproduce suspected vulnerabilities inside an isolated environment.
- Propose remediation: For validated issues, it prepares a minimal patch and evidence for human review.
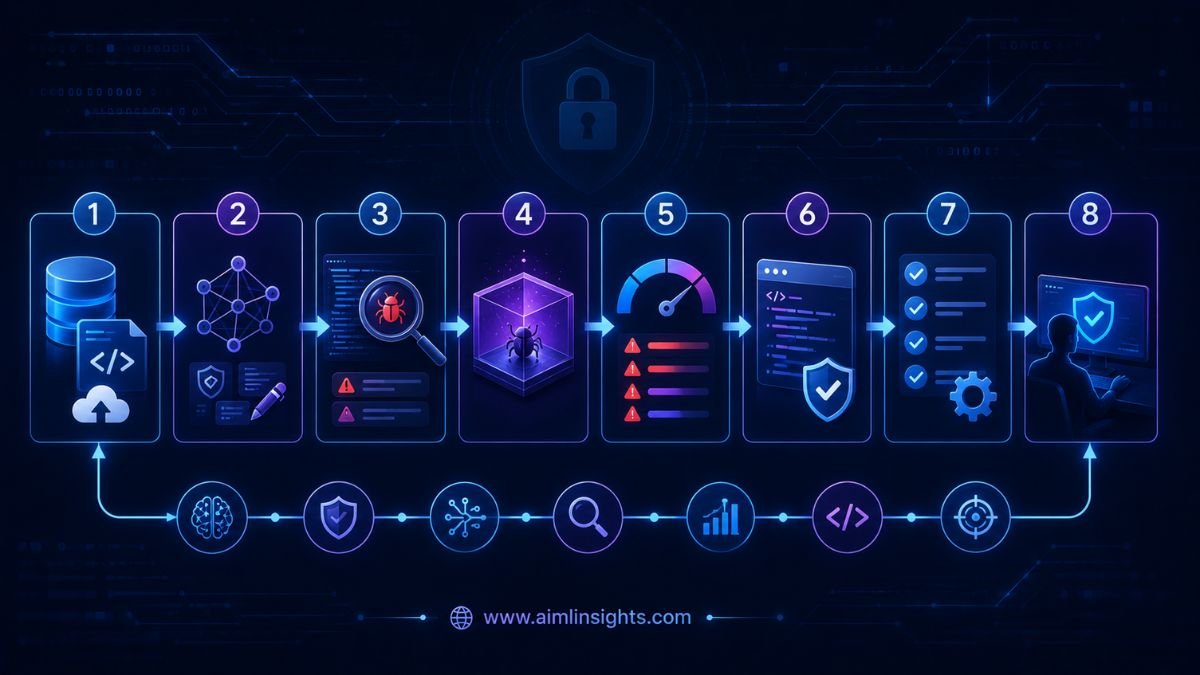
Codex Security does not silently change production code. The proposed fix can be converted into a pull request, but the organization remains responsible for review, testing, and approval.
What Is Genuinely New?
Traditional security scanners are often strongest at signatures, known patterns, dependency alerts, or predefined rules. These remain useful, but they can produce large backlogs that humans must manually triage.
Codex Security takes a more reasoning-driven approach. It tries to understand how an application works, whether vulnerable code is reachable, and whether a suspected flaw can be reproduced.
The newer GPT-5.5-Cyber update goes further by sustaining deeper analysis across large codebases. OpenAI says it can identify security-relevant components, trace reachability, validate issues, develop patches, test fixes, and prepare evidence across a longer remediation process.
The genuinely new part is therefore not simply “AI finds bugs.” It is the attempt to connect discovery, reproduction, patching, and verification in one controlled agent workflow.
GPT-5.5, Trusted Access and GPT-5.5-Cyber
OpenAI has created three access levels rather than releasing its most permissive cyber capabilities to everyone.
| Access level | Intended work | Availability |
| GPT-5.5 | Secure coding, code review, threat modeling, vulnerability triage and patching | Default access |
| GPT-5.5 with Trusted Access for Cyber | Malware analysis, advanced triage, detection engineering and authorized defensive validation | Verified defensive teams |
| GPT-5.5-Cyber | Authorized red teaming, exploit validation and controlled penetration testing | Limited preview with stronger controls |
Trusted Access for Cyber is an identity- and trust-based framework. Approved defenders receive fewer unnecessary refusals for legitimate security tasks, while harmful requests involving credential theft, unauthorized persistence, malware deployment, or attacks on third-party systems remain restricted.
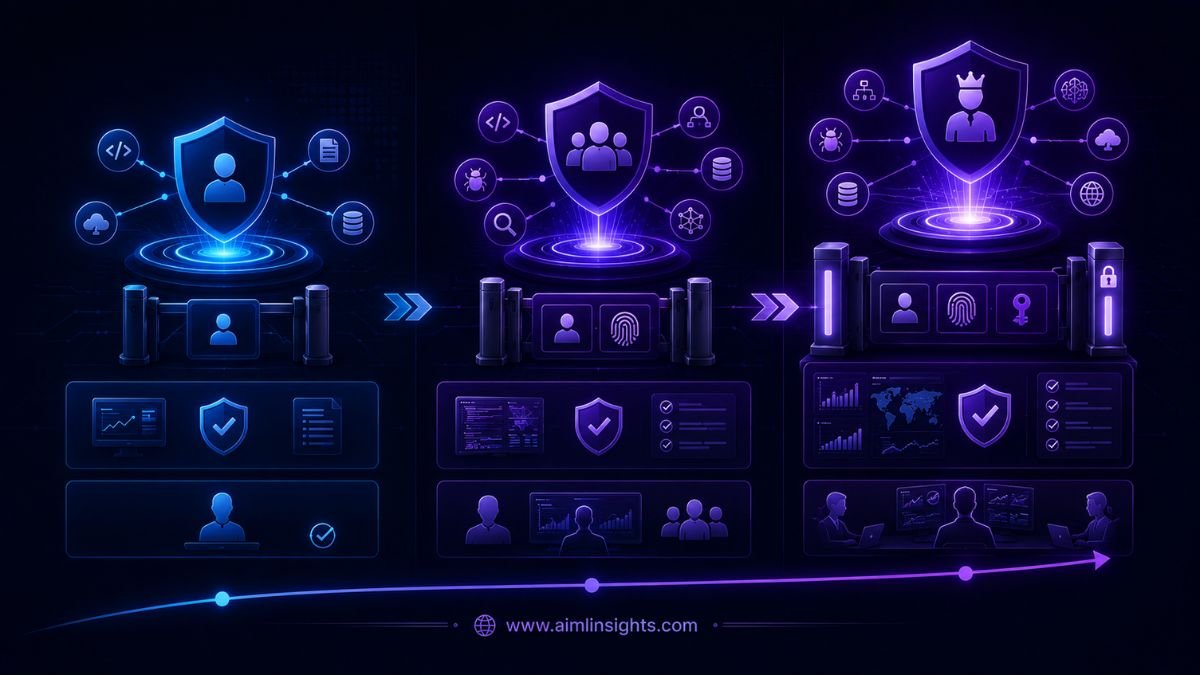
Access does not authorize testing systems a user does not own or have explicit permission to assess. It also does not remove every safeguard or automatically provide zero-data-retention terms.
Benchmark Audit: What the Numbers Actually Show
OpenAI reports three major comparisons between GPT-5.5-Cyber and standard GPT-5.5.
| Benchmark | Metric and purpose | GPT-5.5-Cyber | GPT-5.5 baseline | Reported gain | Evaluation owner | Independently verified? |
| CyberGym | Success reproducing known vulnerabilities | 85.6% | 81.8% | +3.8 points | OpenAI evaluation using the CyberGym benchmark | No independent reproduction published for these scores |
| ExploitGym | Success turning known flaws into working code-execution exploits | 39.5% | 25.95% | +13.55 points | OpenAI | Not disclosed |
| SEC-bench Pro | Long-horizon vulnerability discovery and proof-of-concept generation | 69.8% | 63.1% | +6.7 points | OpenAI | Not disclosed |
OpenAI explicitly identifies these as its own evaluations. The company has not published enough detail in the announcement to determine whether every comparison used identical token budgets, agent harness settings, tool permissions, retry policies, or test-time computation.
CyberGym itself is an established research benchmark from UC Berkeley containing 1,507 historical vulnerabilities across 188 software projects. It primarily measures whether an agent can produce proof-of-concept tests that reproduce known flaws.
That makes the score meaningful, but it does not prove the model will find unknown vulnerabilities at the same rate in unfamiliar production systems.
Why This Matters for Security Teams
Most organizations do not need an AI model that merely produces more findings. They need fewer false positives and faster remediation.
Daybreak’s strongest potential value is reducing the distance between a security alert and a merged fix.
An application-security team could use Codex Security to investigate a large repository, reproduce the most credible issues, and prepare patches. An open-source maintainer could use it to review a reported vulnerability and generate evidence for coordinated disclosure. A security operations team could use GPT-5.5 with Trusted Access to support malware analysis or detection engineering.
The platform may be less suitable for organizations without mature code-review practices. AI-generated patches still require testing, secure deployment, and accountability. Connecting sensitive repositories also creates privacy, access-control, and supply-chain considerations.
OpenAI recommends beginning with a small set of repositories and a dedicated review group before expanding deployment.
Codex Security vs Conventional Scanning Tools
Codex Security should not be viewed as an automatic replacement for static analysis, software-composition analysis, fuzzing, penetration testing, or human code review.
Conventional tools remain efficient for known patterns, unsafe dependencies, policy enforcement, and repeatable checks. Codex Security adds a reasoning layer that may help understand complex attack paths and validate whether findings are exploitable.
The most effective workflow will likely combine both approaches:
- Existing scanners identify broad risk signals.
- Codex Security investigates complex or high-priority findings.
- Isolated validation determines whether the issue can be reproduced.
- Human reviewers assess the evidence and patch.
- Existing CI/CD controls test and deploy the approved fix.
Limitations and Unanswered Questions
Daybreak arrives with meaningful limitations.
The benchmark results are reported by OpenAI and have not been independently reproduced. The announcement does not provide full details about token budgets, latency, scan costs, benchmark harnesses, false-positive rates, or performance across different programming languages.
GPT-5.5-Cyber is also deliberately dual-use. The same capability that helps a defender validate a vulnerability could help an attacker exploit it. OpenAI is addressing this through identity verification, advanced account security, logging, limited access, misuse monitoring, and authorized-use restrictions. Those controls reduce risk but cannot eliminate it.
There are also practical failure modes:
- Incorrect threat-model assumptions
- Missed vulnerabilities
- Patches that introduce regressions
- Excessive confidence in reproduced findings
- Exposure of sensitive repository data
- Misuse of advanced exploit-development capabilities
The central unanswered question is not whether AI can find vulnerabilities. It is whether organizations can deploy these systems at scale without weakening human oversight or expanding the attack surface.
Simple Explanation for Beginners
Think of Daybreak as an AI-assisted security team.
Codex Security first studies the software and maps where an attacker might enter. It then investigates suspicious code, tries to reproduce the problem safely, and suggests a repair.
GPT-5.5 provides the general reasoning. Trusted Access allows verified defenders to complete more advanced defensive tasks. GPT-5.5-Cyber is reserved for specialist work that may involve controlled exploit testing.
A human still decides whether the finding is real and whether the patch should be accepted.
What Comes Next
OpenAI says Daybreak is intended to make software more resilient by bringing security analysis into everyday development workflows.
The next test will be evidence from real deployments: independent benchmark replications, disclosed vulnerabilities, patch acceptance rates, false-positive data, scan pricing, and proof that fixes do not introduce new problems.
The OpenAI AI security stack could reduce vulnerability backlogs and shorten remediation cycles. Its long-term value, however, will depend less on benchmark leadership than on whether security teams can trust its findings, understand its evidence, and safely integrate its patches.
Final Takeaways
- OpenAI expanded Daybreak on June 22, 2026.
- Daybreak combines GPT-5.5, GPT-5.5-Cyber, Codex Security, controlled access, and partner integrations.
- Codex Security builds an editable threat model before scanning code.
- Suspected vulnerabilities are reproduced in an isolated environment before being surfaced.
- Patches require human review and are not applied automatically.
- OpenAI reports an 85.6% CyberGym score for GPT-5.5-Cyber versus 81.8% for GPT-5.5.
- Those model-specific benchmark results are not yet independently verified.
- GPT-5.5-Cyber is restricted to verified, authorized security workflows.
Suggested Read:
- AI Agents Explained Simply
- OpenAI News: Latest ChatGPT Updates
- AI Agents Can Now Work for Hours
- Best AI Coding Tools
- AI Cybersecurity Risks Explained
FAQ: OpenAI Daybreak
What is OpenAI Daybreak?
OpenAI Daybreak is a cybersecurity initiative combining frontier models, Codex Security, trusted-access controls, and industry partnerships to help organizations find, validate, and fix software vulnerabilities.
What is GPT-5.5-Cyber?
GPT-5.5-Cyber is a more permissive and cyber-specialized version of GPT-5.5 intended for authorized red teaming, penetration testing, exploit validation, and controlled security research.
How does Codex Security work?
It builds an editable threat model, searches for realistic vulnerabilities, tries to reproduce them in an isolated environment, and proposes minimal patches for human review.
Can OpenAI automatically patch vulnerabilities?
Codex Security can generate a proposed patch, but it does not automatically modify the repository. A person must review and approve the change through the normal development workflow.
Who can access GPT-5.5-Cyber?
GPT-5.5-Cyber is available in limited preview for verified organizations conducting authorized higher-risk security work. Most defenders are directed toward GPT-5.5 with Trusted Access for Cyber.
Is GPT-5.5-Cyber safe?
It remains a dual-use system. OpenAI uses identity verification, account security, logging, scoped access, monitoring, and authorization rules to reduce misuse, but these measures do not remove every risk.
References:
- OpenAI’s Daybreak announcement and GPT-5.5-Cyber benchmark disclosure.
- OpenAI’s Daybreak product and access overview.
- OpenAI’s Trusted Access for Cyber technical explanation.
- OpenAI’s Codex Security documentation.
- OpenAI’s Trusted Access limitations and approved-use policy.
- The original UC Berkeley CyberGym benchmark and research paper.