LLM Benchmarking Explained: How AI Models Are Tested in 2026
Large Language Models (LLMs) are improving rapidly. New models appear regularly, each claiming to be faster, smarter, cheaper, or more accurate.
But how do we know whether one model is actually better than another?
That is where LLM benchmarking becomes important.
Benchmarking helps researchers, developers, and businesses compare AI models using structured tests instead of marketing claims.
This guide explains LLM benchmarking in simple terms, why it matters, common methods, and how to use benchmark results wisely.
In simple terms
LLM benchmarking means:
Testing language models using standardized tasks and scoring systems to compare performance.
It helps answer questions like:
- Which model solves reasoning tasks better?
- Which model writes code more accurately?
- Which model is faster?
- Which model hallucinates less?
- Which model gives best value for cost?
Benchmarking turns opinions into measurable data.
Why LLM Benchmarking Matters
Without benchmarks, choosing a model becomes guesswork.
Teams evaluating systems from providers such as:
need objective ways to compare performance.
Benchmarking helps with:
- vendor selection
- cost control
- model upgrades
- product quality
- internal AI strategy
Easy analogy
Think of buying a car.
You compare:
- mileage
- speed
- safety
- price
- reliability
You would not choose only based on ads.
Benchmarking does the same for LLMs.
Common Types of LLM Benchmarks
1. Knowledge Benchmarks
Measure factual and academic question answering.
Often include:
- science
- history
- math
- language tasks
2. Reasoning Benchmarks
Test logic and multi-step problem solving.
Useful for advanced assistants.
3. Coding Benchmarks
Measure code generation, debugging, and programming tasks.
Important for developer tools.
4. Instruction Following Benchmarks
Tests whether models obey prompts correctly.
Example:
- formatting requests
- constraints
- role behavior
5. Safety Benchmarks
Measure refusal quality, harmful output prevention, and policy alignment.
6. Multilingual Benchmarks
Evaluate performance across languages.
7. Efficiency Benchmarks
Measure:
- latency
- throughput
- token speed
- memory use
- inference cost
Popular Benchmarking Metrics
| Metric | What It Measures |
| Accuracy | Correct answers |
| Pass Rate | Completed tasks |
| Latency | Speed |
| Cost | Economic efficiency |
| Hallucination Rate | False outputs |
| Consistency | Repeatability |
| User Preference | Human-rated quality |
Public benchmarks vs private benchmarks
Public Benchmarks
Shared tests used across the industry.
Benefits:
- easy comparison
- transparency
- common reference points
Private Benchmarks
Custom internal tests using real business prompts.
Benefits:
- more realistic
- directly relevant
- better purchasing decisions
Most serious teams use both.
Why public benchmarks can mislead
Overfitting
Models may optimize for known tests.
Unrealistic Tasks
Some benchmarks do not reflect real work.
Narrow Focus
Strong math score does not guarantee great customer support.
Rapid Obsolescence
AI moves quickly.
Real-world LLM Benchmarking Example
A company comparing chatbot models may test:
- answer accuracy
- tone quality
- response speed
- hallucination frequency
- support resolution rate
- cost per conversation
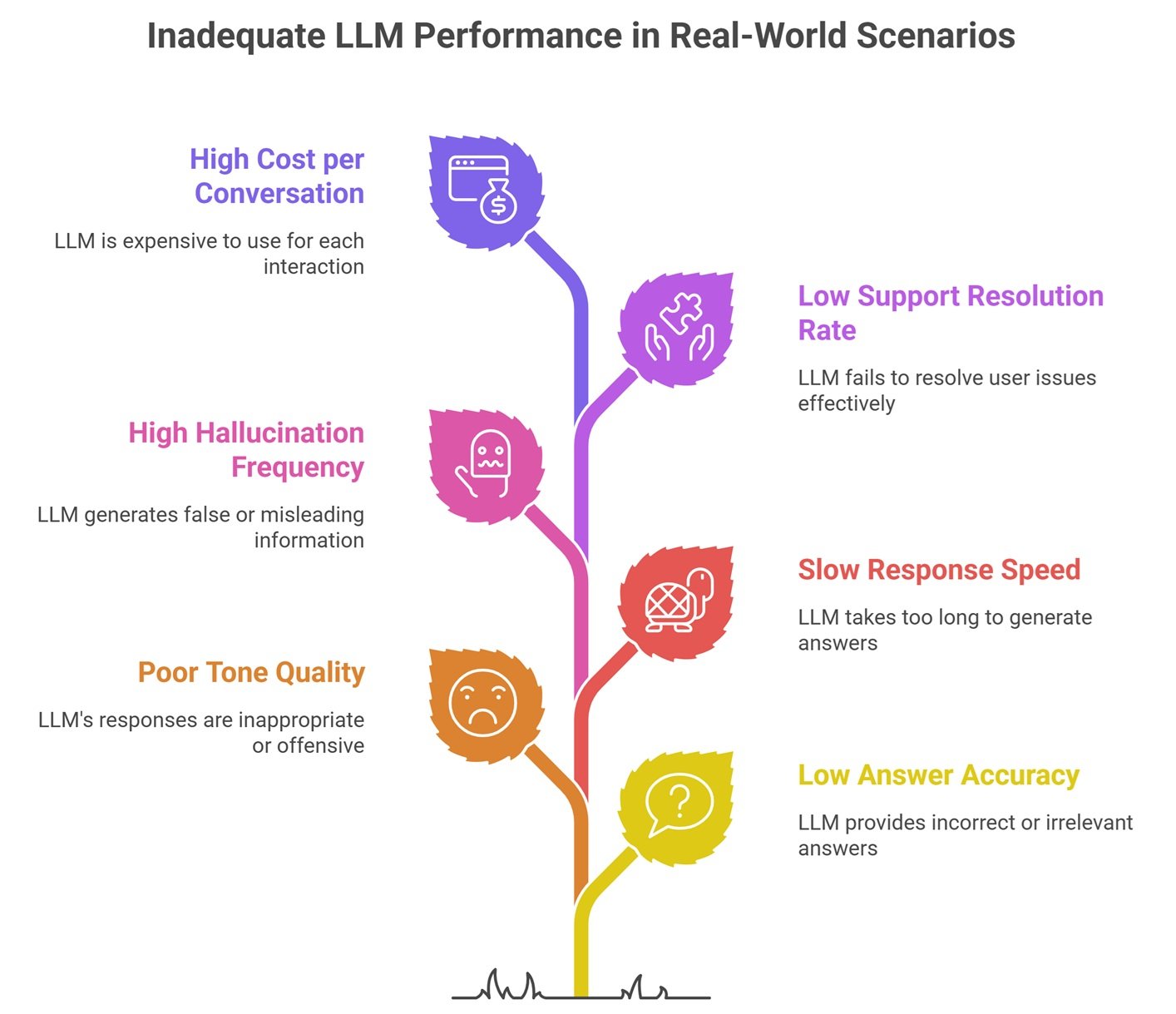
That is more useful than a generic leader board.
Best LLM Benchmarks Explained by Use Case
Customer Support
- helpfulness
- safety
- speed
- resolution rate
Coding Assistant
- code correctness
- bug fixing success
- syntax quality
Internal Search
- grounded answers
- citation quality
- hallucination rate
Content Writing
- relevance
- readability
- factual quality
Enterprise Copilot
- security
- reliability
- workflow completion
How to Benchmark LLMs Yourself
Step 1: Define Goal
Support, coding, writing, search, analytics.
Step 2: Build Test Prompt Set
Use real examples.
Step 3: Score Outputs
Human + automated methods.
Step 4: Compare Cost and Speed
Not just quality.
Step 5: Re-test Often
Models evolve quickly.
Common Mistakes in LLM Benchmarking
Trusting One Leader board
Use multiple signals.
Ignoring Cost
Top score may be too expensive.
Ignoring Latency
Users care about speed.
Tiny Sample Size
Need enough prompts.
No Human Review
Numbers miss nuance.
Benchmarking vs Evaluation
| Term | Meaning |
| Benchmarking | Comparing models using tests |
| Evaluation | Broader process of judging usefulness |
Benchmarking is one part of evaluation.
Future of LLM benchmarking
Expect growth in:
- live production benchmarking
- automated AI judges
- agent workflow benchmarks
- hallucination tracking
- ROI-focused benchmarks
- multimodal benchmark suites
Benchmarking is becoming more practical and business-driven.
Suggested Read:
- LLM Evaluation Metrics
- LLM API Pricing Comparison
- How to Reduce LLM Hallucinations
- Best LLMs for Coding
- Multimodal LLMs
- LLM for Beginners
FAQ: LLM Benchmarking Explained
What is LLM benchmarking?
Testing AI models using structured tasks and metrics.
Are public benchmarks enough?
No. Real workflow testing is essential.
Which metric matters most?
Depends on the use case.
Should startups benchmark models?
Yes, even simple tests help.
How often should benchmarks be updated?
Regularly, especially after model changes.
Final takeaway
LLM benchmarking helps teams choose models based on evidence rather than hype. Public leaderboards are useful, but the best benchmark is how a model performs on your real tasks.
Measure what matters most to your users and business.