LLM Safety Basics Explained: Risks, Guardrails & Best Practices
Large Language Models (LLMs) are transforming search, writing, coding, customer support, and enterprise automation. But powerful AI systems also introduce new risks.
A model may generate harmful advice, leak sensitive information, hallucinate facts, or be manipulated through malicious prompts.
That is why understanding LLM safety basics is essential for businesses, developers, and everyday users.
This guide explains what LLM safety means, common risks, and practical ways to build safer AI systems.
In simple terms
LLM safety means:
Reducing harmful, incorrect, insecure, or irresponsible behavior from language models.
It focuses on making AI systems:
- reliable
- secure
- privacy-aware
- policy-compliant
- trustworthy
- useful without causing harm
Safety is not one feature. It is an ongoing process.
Why LLM Safety Matters
Without safety controls, AI systems may create:
- misinformation
- unsafe instructions
- data leaks
- biased outputs
- legal issues
- brand damage
- customer trust loss
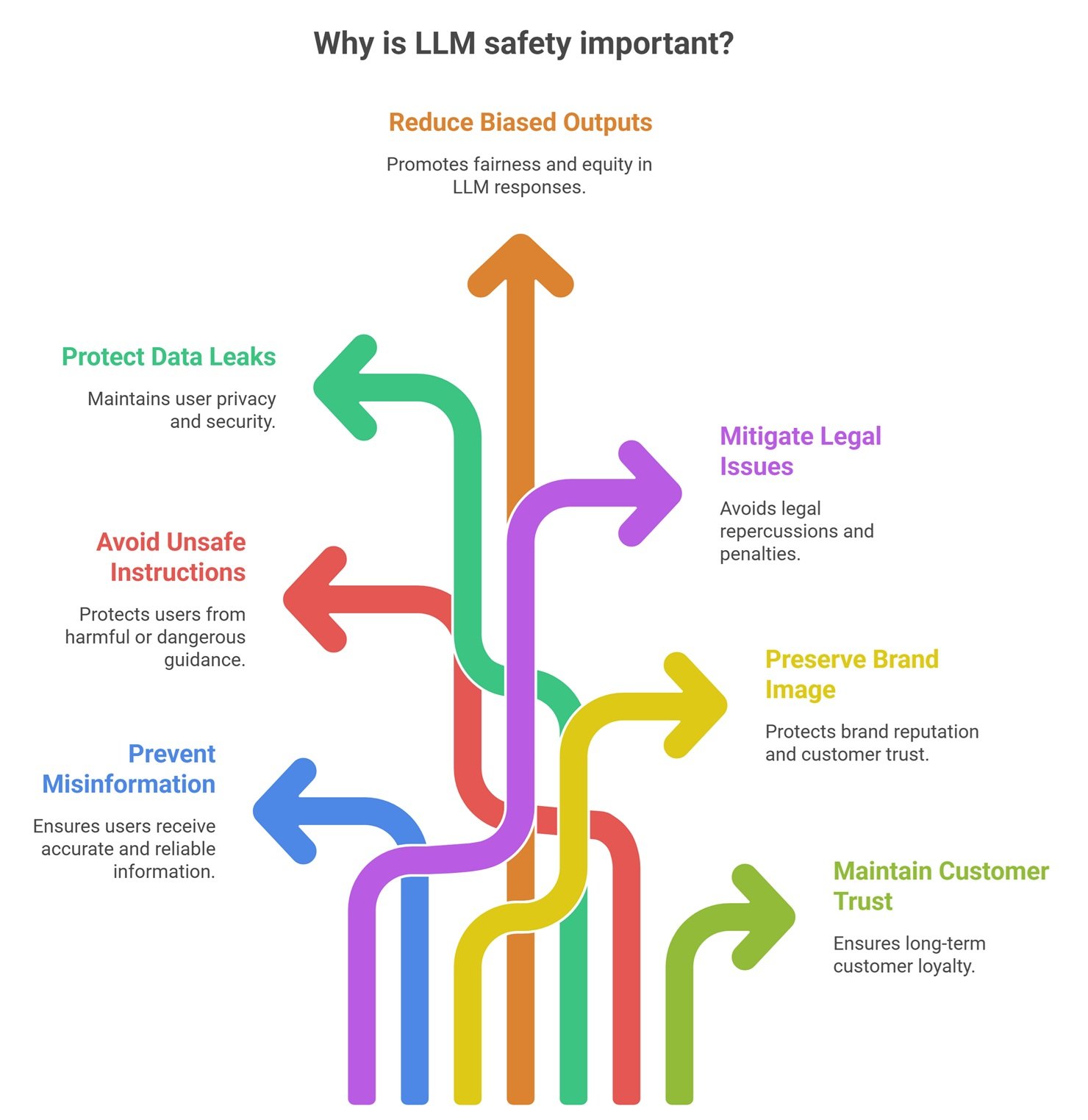
As adoption grows, safety becomes a business priority.
Easy analogy
Think of a car.
Even a powerful car needs:
- brakes
- seat belts
- mirrors
- speed controls
- maintenance
Likewise, a powerful LLM needs guardrails.
Common LLM Safety Risks
1. Hallucinations
The model generates false information confidently.
Examples:
- fake citations
- wrong medical facts
- incorrect code suggestions
2. Prompt Injection
Malicious prompts try to override system instructions or manipulate behavior.
3. Privacy Leaks
Sensitive prompts, customer data, or internal documents may be exposed if systems are poorly designed.
4. Harmful Content
Models may generate abusive, dangerous, or restricted content.
5. Bias and Fairness Issues
Outputs may reflect skewed training patterns.
6. Security Misuse
Attackers may use AI for phishing, scams, or automation abuse.
7. Over-Reliance by Users
People may trust outputs too much.
AI ecosystems focused on safety
Major providers continue investing in safer systems, including:
But safe deployment still depends heavily on how users implement models.
Core LLM Safety Guardrails
1. Prompt Controls
Use strong system instructions and clear boundaries.
2. Output Moderation
Screen harmful or risky responses.
3. Human Review
Critical workflows need oversight.
4. Access Controls
Limit who can use sensitive systems.
5. Logging & Monitoring
Track failures and misuse attempts.
6. Data Minimization
Do not send unnecessary private data.
7. Fallback Rules
Escalate uncertain cases to humans.
Safety by use case
Customer Support Bot
Need:
- safe tone
- no fake policy claims
- privacy protection
Coding Assistant
Need:
- secure code suggestions
- no risky commands without warnings
Healthcare AI
Need:
- strong disclaimers
- human review
- factual controls
Enterprise Search
Need:
- permission-aware access
- accurate citations
LLM Safety vs LLM Security
| Term | Meaning |
| Safety | Harmful or risky outputs |
| Security | Protecting systems from attacks |
Both matter and often overlap.
LLM safety vs censorship
Some people confuse these ideas.
Safety usually means:
- reducing harm
- respecting laws
- preventing abuse
- protecting users
It is broader than simple content blocking.
Practical safety checklist for teams
Before Launch
- define risky scenarios
- create policies
- test prompts
- simulate abuse attempts
During Launch
- monitor outputs
- review incidents
- gather feedback
After Launch
- update controls
- retrain workflows
- improve prompts
Safety is continuous.
Common Mistakes Companies Make
Launching Without Red Teaming
No adversarial testing.
Blind Trust in Vendor Defaults
Shared responsibility still applies.
No Human Escalation Path
Some cases need people.
Logging Sensitive Data Poorly
Creates privacy risk.
Ignoring Hallucinations
Wrong outputs can become expensive.
How users can stay safer
Verify Important Claims
Do not trust critical outputs blindly.
Avoid Sharing Sensitive Data
Especially personal or confidential information.
Use Trusted Platforms
Choose reputable providers.
Ask for Sources
Improves transparency.
Future of LLM safety
Expect growth in:
- automatic hallucination detection
- stronger prompt injection defenses
- privacy-preserving AI systems
- domain-specific safe assistants
- AI governance standards
- real-time risk scoring
Safety will become a competitive advantage.
Suggested Read:
- Why LLMs Hallucinate
- How to Reduce LLM Hallucinations
- Prompt Injection Explained
- LLM Evaluation Metrics
- LLM Deployment Basics
- LLM for Beginners
FAQ: LLM Safety Basics
What is LLM safety?
Reducing harmful, false, or insecure AI behavior.
Why is LLM safety important?
Because powerful AI can create real business and user risks.
Can LLMs be made fully safe?
No system is perfect, but risk can be greatly reduced.
Is hallucination a safety issue?
Yes, especially in high-stakes domains.
Who is responsible for safety?
Both providers and deployers share responsibility.
Final takeaway
LLM safety basics are not optional anymore. As language models become part of products and workflows, guardrails matter as much as capability.
The smartest AI strategy is not just powerful AI—it is safe, monitored, and trustworthy AI.