LLM Evaluation Metrics Explained: How to Measure AI Model Quality in 2026
Choosing a Large Language Model (LLM) is no longer just about popularity. Businesses, developers, and AI teams need to know which model performs best for their actual tasks.
That requires evaluation.
Without the right metrics, teams may choose models that look impressive in demos but fail in production.
This guide explains the most important LLM evaluation metrics, how they work, and how to build a practical benchmarking process.
In simple terms
LLM evaluation metrics are:
Measurements used to judge how well a language model performs.
They help answer questions like:
- Is the model accurate?
- Is it fast enough?
- Does it hallucinate often?
- Is it affordable at scale?
- Is output safe and useful?
- Do users actually like it?
Good evaluation prevents expensive mistakes.
Why LLM evaluation matters
Many teams compare models such as:
But no model is best at everything.
A coding assistant needs different metrics than a customer support chatbot.
That is why evaluation should match the use case.
Core LLM Evaluation Metric
1. Accuracy
Measures whether answers are correct.
Best for:
- factual Q&A
- classification
- extraction tasks
- domain workflows
Example:
Correct answers out of 100 prompts.
2. Hallucination Rate
Measures how often the model invents false information.
Critical for:
- research
- healthcare
- legal
- finance
- enterprise search
Lower is better.
3. Relevance
How well the response answers the actual prompt.
Some outputs are fluent but irrelevant.
4. Consistency
Does the model give similar quality outputs repeatedly?
Important for production systems.
5. Latency
How fast responses arrive.
Measured in:
- first token speed
- full response time
- average request time
Critical for live apps.
6. Cost Per Request
Measures economic efficiency.
Includes:
- input token cost
- output token cost
- infrastructure cost
- retry cost
7. Safety / Policy Compliance
How well the model avoids harmful or restricted outputs.
Important for public-facing products.
8. User Satisfaction
Sometimes the best metric is whether users prefer it.
Measured via:
- thumbs up/down
- ratings
- retention
- repeat usage
Advanced LLM Metrics
Robustness
Handles typos, noisy prompts, edge cases.
Context Handling
Performs well with long documents.
Tool Use Accuracy
Correctly uses APIs or tools.
Instruction Following
Follows formatting and constraints.
Multilingual Quality
Strong across multiple languages.
Easy analogy
Think of hiring an employee.
You would evaluate:
- correctness
- speed
- communication
- reliability
- cost
- safety
- customer feedback
Same idea for LLMs.
Common Benchmark styles
Automatic Benchmarks
Predefined tests scored automatically.
Good for scale.
Human Evaluation
Humans rate usefulness and quality.
Best for nuance.
A/B Testing
Two models compete in live traffic.
Great for real-world decisions.
Task-Specific Benchmarks
Custom prompts from your business workflow.
Often most valuable.
Example evaluation scorecard
| Metric | Weight | Model A | Model B |
| Accuracy | 30% | High | Medium |
| Latency | 20% | Medium | High |
| Cost | 20% | Medium | High |
| Hallucination | 20% | High | Medium |
| User Satisfaction | 10% | High | Medium |
This helps make smarter tradeoffs.
Best LLM Evaluation Metrics by Use Case
Customer Support Bot
- accuracy
- latency
- safety
- satisfaction
Coding Assistant
- code correctness
- debugging quality
- latency
Internal Search Tool
- factual grounding
- hallucination rate
- retrieval quality
Content Generator
- relevance
- tone quality
- productivity gain
Enterprise Copilot
- security
- compliance
- reliability
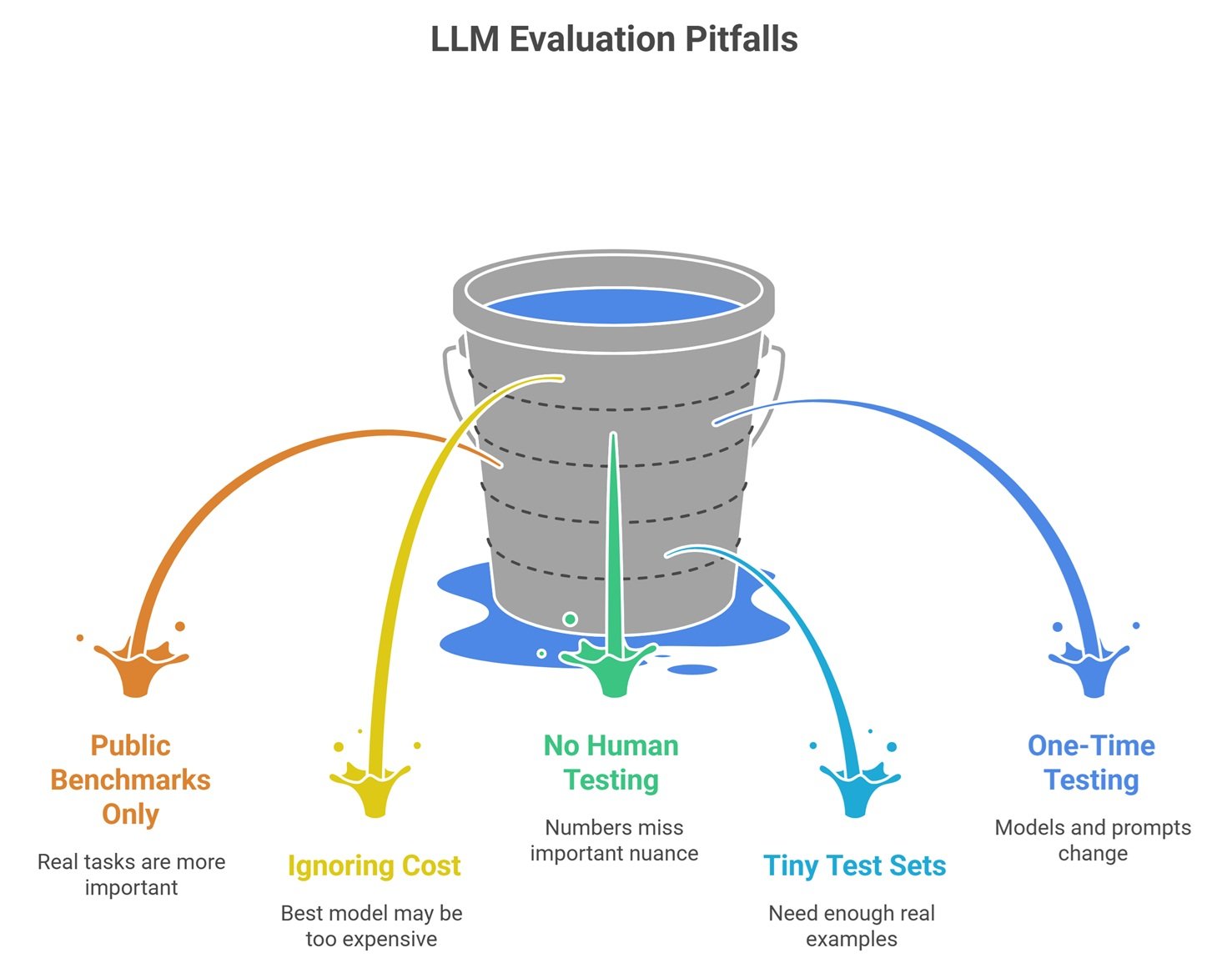
Common Mistakes in LLM Evaluation Metrics
Using Only Public Benchmarks
Real tasks matter more.
Ignoring Cost
Best model may be too expensive.
No Human Testing
Numbers miss nuance.
Tiny Test Sets
Need enough real examples.
One-Time Testing Only
Models and prompts change.
How to build a practical evaluation system
Step 1: Define Business Goal
Support, coding, search, writing, etc.
Step 2: Build Real Prompt Set
Use actual user tasks.
Step 3: Choose Metrics
Only relevant ones.
Step 4: Compare Multiple Models
Avoid assumptions.
Step 5: Monitor in Production
Evaluation never ends.
Future of LLM evaluation
Expect growth in:
- automated judges
- synthetic benchmark generation
- continuous production scoring
- hallucination detection systems
- agent evaluation frameworks
- ROI-based AI metrics
Evaluation is becoming a competitive advantage.
Suggested Read:
- How to Reduce LLM Hallucinations
- Why LLMs Hallucinate
- LLM API Pricing Comparison
- Best LLMs for Coding
- LLM Deployment Basics
- LLM for Beginners
FAQ: LLM Evaluation Metrics Explained
What is the most important LLM metric?
Depends on the use case.
Is accuracy enough?
No. Cost, speed, and hallucination also matter.
Should startups benchmark models?
Yes, even lightweight comparisons help.
Are public leader boards enough?
Useful, but not sufficient.
How often should models be re-evaluated?
Regularly, especially after updates.
Final takeaway
LLM evaluation metrics help teams move beyond hype and choose models based on evidence. The best model is not the most famous one—it is the one that performs best for your workflow, budget, and users.
Measure what matters, then optimize continuously.