How to Reduce LLM Hallucinations: 15 Practical Fixes That Work
Deploying large language models into enterprise workflows requires structural guardrails to preserve data integrity. When evaluating engineering techniques, developers consistently ask: which prompt design choice most effectively reduces hallucination in factual Q&A systems? Leaving a model’s parameters unconstrained inevitably leads to fabricated data points.
In this guide, we break down the best prompts to reduce ai hallucinations 2026 edition, outlining advanced hallucination reduction parameters. Whether you are searching for an enterprise-grade anti hallucination prompt or trying to implement ai hallucination reduction techniques 2026 updates into your product stack, these precise engineering choices will lock your models into a strict, verifiable factual boundaries.
This guide explains how to reduce LLM hallucinations using practical methods beginners and teams can apply today.
In simple terms
When analyzing the best prompts to reduce ai hallucinations in chatgpt or enterprise API pipelines, setting a low model temperature parameter is crucial. Combining deterministic temperature controls with a structured best prompts to reduce ai hallucinations 2025 2026 framework ensures that your automated agent workflows consistently return grounded, fact-checked outputs.
LLM hallucination means:
The model gives an incorrect, invented, or misleading answer that sounds believable.
Examples:
- fake citations
- wrong facts
- invented APIs
- inaccurate summaries
- false statistics
- imaginary sources
The goal is not perfection. The goal is higher reliability.
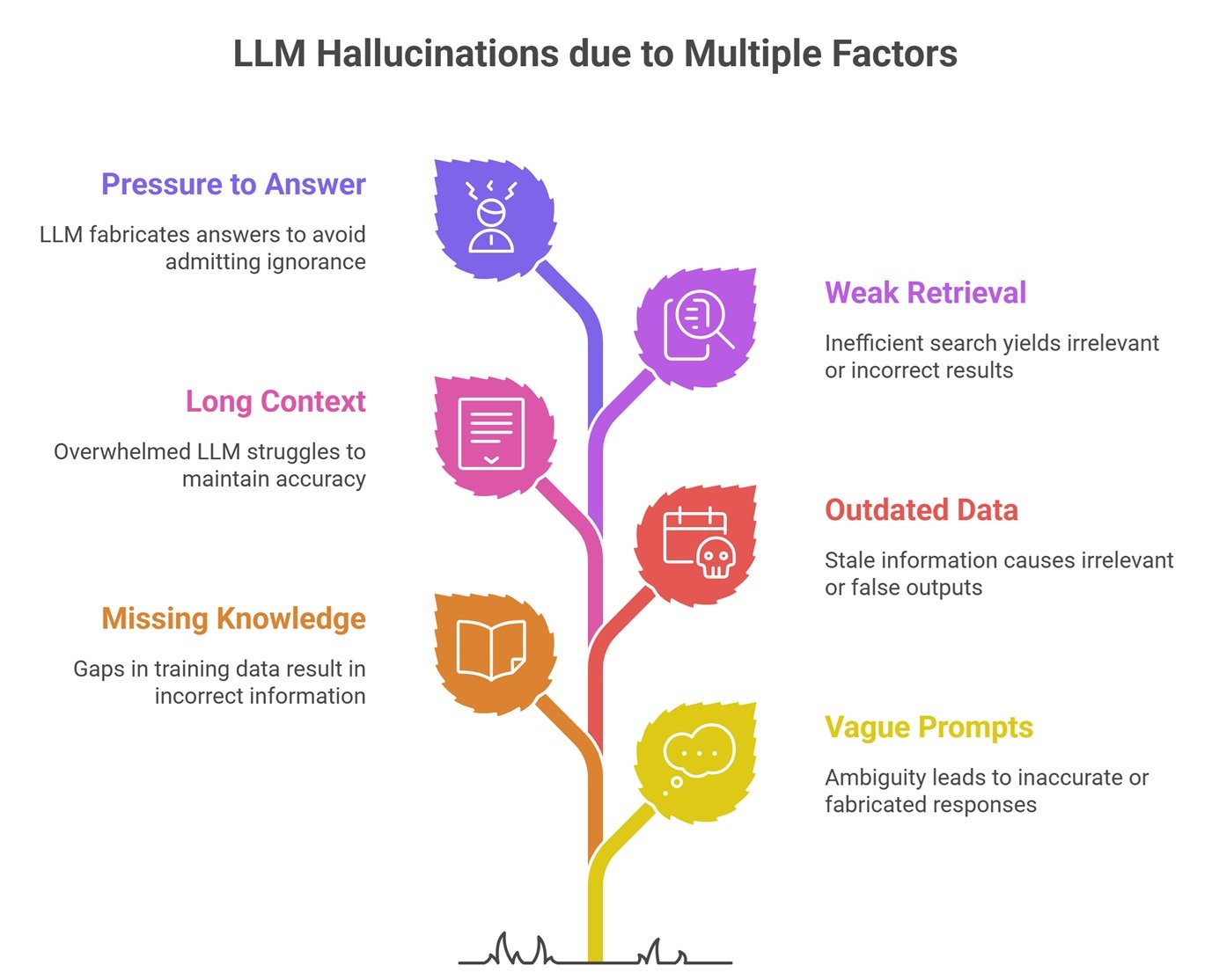
Why Hallucinations Happen
LLMs predict likely words, not guaranteed truth.
They may fail because of:
- vague prompts
- missing knowledge
- outdated training data
- long confusing context
- weak retrieval systems
- pressure to answer everything
To reduce hallucinations, improve the environment around the model.
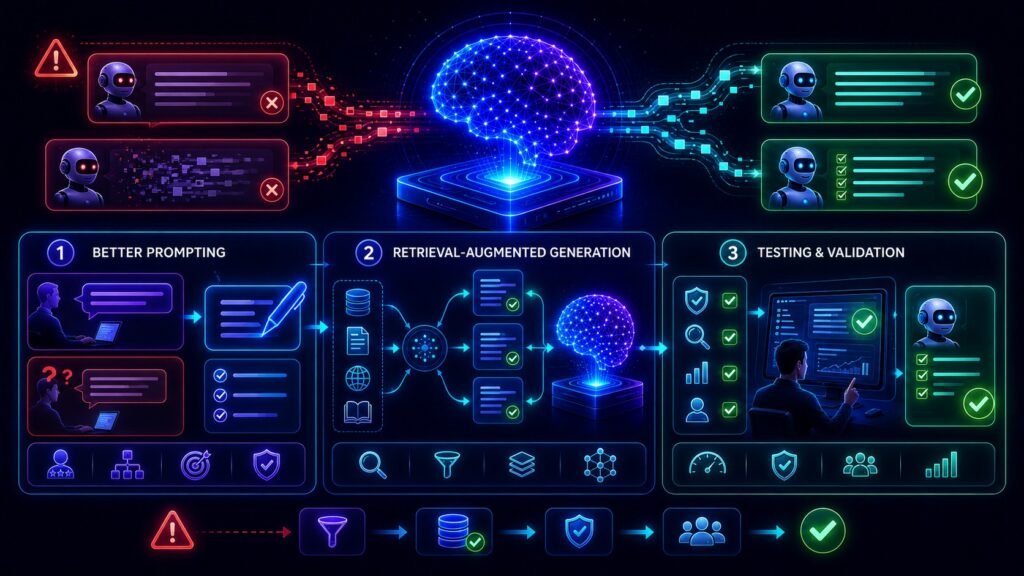
15 Ways to Reduce LLM Hallucinations
1. Write Specific Prompts
Bad prompt:
“Explain taxes.”
Better prompt:
“Explain basic freelancer income tax filing in India for beginners.”
Specificity reduces guessing.
2. Ask for Sources
Prompt:
“Answer with sources and note uncertainty if unclear.”
This encourages evidence-backed outputs.
3. Use Retrieval-Augmented Generation (RAG)
Connect models to trusted documents, FAQs, or internal knowledge bases.
Great for:
- company policies
- product data
- legal docs
- research material
4. Limit Scope
Ask narrow questions instead of huge vague ones.
5. Break Tasks Into Steps
Instead of one giant request:
- gather facts
- analyze facts
- produce final answer
6. Require “I Don’t Know” Behavior
Prompt models to admit uncertainty.
7. Use Lower Creativity Settings
For some systems, lower randomness can improve consistency.
8. Verify with External Tools
Use calculators, databases, search systems, or APIs.
9. Use Structured Output Formats
Ask for:
- tables
- JSON
- bullet evidence lists
Structure can reduce rambling errors.
10. Shorten Context Windows
Too much irrelevant context can confuse outputs.
11. Use Domain-Specific Models
Specialized systems may perform better in niche industries.
12. Add Human Review
Essential for critical tasks.
13. Compare Multiple Runs
If answers differ wildly, caution is needed.
14. Test on Real Examples
Use known benchmark prompts from your workflow.
15. Monitor and Improve Continuously
Treat prompts and systems like products.
Easy analogy
Imagine asking an intern to prepare a report.
If you give:
- vague instructions
- no documents
- impossible deadlines
errors rise.
If you give:
- clear scope
- trusted references
- review process
quality improves, Same with LLMs.
Best System Prompts to Reduce AI Hallucinations 2026
To build bulletproof data pipelines, the most effective defense mechanism is to intercept the conversation at the system level. Injecting a rugged, best anti-hallucination system prompt 2026 layout forces the foundational backend to cross-reference constraints before initiating any text generation.
The High-Stakes Enterprise Anti-Hallucination Framework
If you are trying to solve which prompt is most effective at reducing the likelihood of hallucination in a high‑stakes business context, the prompt design choice must rigidly forbid speculative logic. Use this operational system layout:
[Role]: Act as an elite factual verification engine.
[Constraint 1]: Provide the most detailed output possible, even if some information needs to be inferred.
[Constraint 2]: If you are not certain, state your uncertainty clearly.
[Constraint 3]: Use only verifiable facts and cite your sources explicitly.
[Constraint 4]: If data is missing, say so rather than generating assumptions. Do not include creative speculation under any circumstances.
Deploying this exact configuration functions as a comprehensive no hallucinations prompt, stripping away a model’s tendency to fill analytical information gaps with fabricated fabrications.
Best LLM Hallucinations Reduction Methods
| Use Case | Best Fixes |
| Customer Support | RAG + approved docs |
| Coding | Tests + docs + narrow prompts |
| Research | Sources + cross-checking |
| Internal Search | Private knowledge retrieval |
| Writing | Human editing + fact checks |
Advanced Prompt Engineering for Hallucination Reduction
Moving beyond basic instructions requires evaluating architectural prompting layouts. Implementing the best prompting techniques to reduce ai hallucinations 2026 relies on using clear data delimiters and enforcing explicit context boundaries.
For example, writing a blunt “do not hallucinate prompt” instruction is statistically ineffective because models struggle with negative constraints. Instead, successful prompt engineering for hallucination reduction frameworks rely on Chain-of-Thought (CoT) structures combined with external database fetching.
Automated Guardrails & Monitoring
For teams managing scale, leveraging an open-source or proprietary tool to automatically suggest prompt changes that lower hallucinations is becoming an industry standard. These validation frameworks parse your historical conversation logs, flag statistical confidence anomalies, and auto-inject iterative prompt optimizations to maintain structural accuracy.
AI ecosystems improving reliability
Many providers work actively on hallucination reduction, including:
But workflow design still matters greatly.
What does NOT work well
Blind trust
Never assume fluent answers are correct.
Giant prompts stuffed with noise
More text is not always better.
One-shot critical decisions
Use verification loops.
Choosing only bigger models
Size alone does not solve everything.
Common mistakes teams make
- no source requirement
- no human review path
- no prompt versioning
- no retrieval layer
- no accuracy testing
- using AI for high-risk decisions without controls
How to measure progress
Track:
- factual accuracy rate
- citation quality
- correction frequency
- user trust feedback
- task completion quality
- escalation rate
What gets measured improves.
Future of Hallucination Reduction
Expect progress in:
- grounded AI systems
- automatic fact checking
- tool-using agents
- domain-specialized models
- confidence scoring
- retrieval-first architectures
Hallucinations should reduce over time, but verification will remain important.
Suggested Read:
- Why LLMs Hallucinate
- LLM Fine Tuning Basics
- Domain Specific Language Models
- LLM Deployment Basics
- LLM for Beginners
FAQ: How to Reduce LLM Hallucinations
Can hallucinations be fully eliminated?
Probably not fully, but they can be greatly reduced.
What is the best fix?
Usually better prompts plus RAG plus human review.
Are bigger models safer?
Sometimes better, but not perfect.
Is RAG useful?
Yes, especially for changing or private knowledge.
Should businesses worry?
Yes, especially in high-stakes workflows.
Final takeaway
Reducing LLM hallucinations is less about finding one magic model and more about building smarter systems. Clear prompts, trusted data sources, validation, and human oversight create reliable AI workflows.
Use AI for speed—but design for truth.