Vision-language models are multimodal AI models that connect computer vision with natural language processing. They help AI understand images, screenshots, charts, documents, or video frames together with text prompts, captions, or questions. This makes VLMs useful for image captioning, visual question answering, document AI, visual search, and AI assistants.
In Simple Terms
A vision-language model, often called a VLM, is an AI model that can work with both visual information and language. A normal language model mainly understands text. A computer vision model mainly understands images. A vision-language model connects the two, so it can answer questions about images, describe visual scenes, compare pictures with text, or explain what a chart shows.
For example, if you upload a product photo and ask, “What kind of item is this?” a VLM can inspect the image and generate a text answer. If you upload a chart and ask, “Which line is growing fastest?” the model can use visual and textual reasoning together. IBM defines vision-language models as AI models that blend computer vision and natural language processing capabilities.
What Are Vision-Language Models?
Vision-language models are AI systems designed to understand relationships between visual data and text data. The visual data may include images, diagrams, screenshots, scanned pages, or video frames. The text data may include prompts, captions, labels, questions, instructions, or documents.
The key idea is alignment. A VLM learns that words like “dog,” “red car,” “bar chart,” or “damaged part” correspond to visual patterns. It also learns how visual details relate to natural-language questions. This is why VLMs are important in multimodal AI: they give AI systems a practical way to connect what they “see” with what users ask in language.
How Vision-Language Models Work
Vision-language models usually combine a visual encoder, a language encoder or language model, and an alignment mechanism. The visual encoder converts images or frames into visual embeddings. The language component converts text into language embeddings or uses text as instructions. The model then aligns those representations so visual and textual meaning can be compared.
After alignment, the model can perform tasks such as image captioning, visual question answering, image-text matching, visual search, document understanding, or multimodal reasoning. Hugging Face describes VLMs as models that learn simultaneously from images and texts to support tasks such as visual question answering and image captioning.
Core Components of a VLM
| Component | What It Does | Simple Example |
| Visual encoder | Reads image or video features | Detects objects, layout, patterns |
| Text encoder or LLM | Processes prompts and language | Understands the user’s question |
| Alignment layer | Connects visual and text meaning | Links “red car” to image region |
| Reasoning layer | Interprets the combined context | Answers question about the image |
| Output layer | Produces text or action | Caption, answer, summary, label |
Common Vision-Language Model Tasks
The most common VLM task is image captioning. The model looks at an image and produces a written description. Another major task is visual question answering, where the user asks a question about an image and the model answers based on visual evidence.
VLMs are also used for image-text retrieval, where users search images using natural language. They support document understanding by reading charts, forms, tables, and scanned pages. Some VLMs also help with visual grounding, where the model connects specific words to specific regions in an image. NVIDIA describes VLMs as multimodal models that can reason against image and video inputs and perform descriptive language generation.
Vision-Language Models vs LLMs
LLMs and VLMs are related, but they are not the same. Large language models are language-first systems. They are strong at text generation, summarization, reasoning, coding, and question answering over written content. Vision-language models add visual understanding.
A text-only LLM cannot inspect a photo unless the visual content is converted into text first. A VLM can process the image directly and connect it with the user’s prompt. This makes VLMs useful when the task depends on screenshots, product photos, charts, diagrams, scanned documents, or video frames.
| Category | LLM | Vision-Language Model |
| Main input | Text | Images + text |
| Best for | Writing, summaries, Q&A | Image-text understanding |
| Visual understanding | Limited or none | Core capability |
| Example | Summarize a report | Explain a chart screenshot |
| Business use | Chatbots, writing tools | Visual search, document AI, support |
Vision-Language Models vs Multimodal AI
Vision-language models are a specific type of multimodal AI. Multimodal AI can include many combinations: text + image, text + audio, text + video, speech + vision, sensor data + language, and more. VLMs focus mainly on vision and language.
This makes VLMs a foundation for many multimodal systems, but not the whole category. A voice assistant that understands speech and text may be multimodal but not necessarily a VLM. A robot that combines cameras, lidar, speech, and sensor data may use VLMs as one component inside a larger multimodal agent.
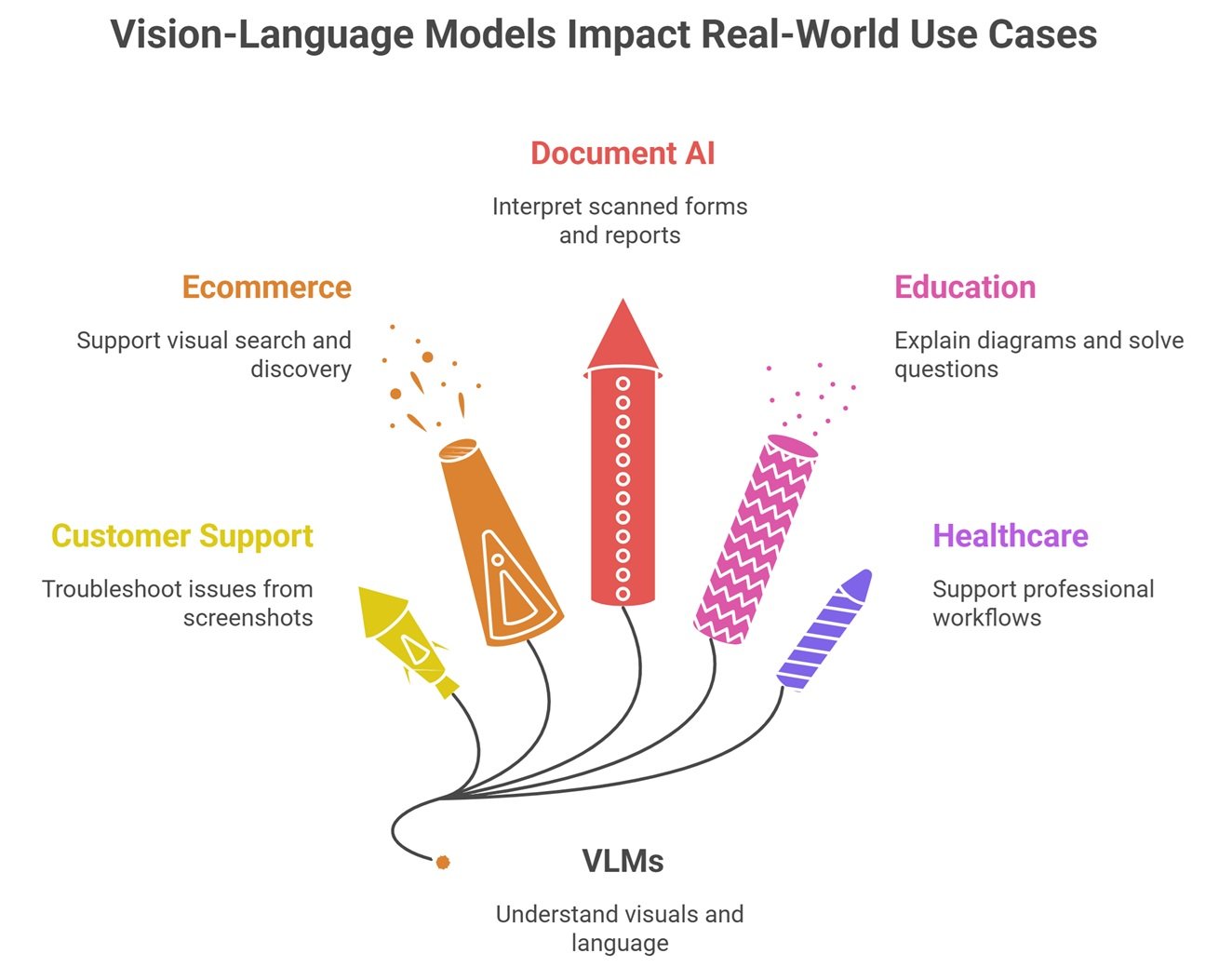
Real-World Use Cases of Vision-Language Models
Vision-language models are useful wherever users need AI to understand visuals and language together. In customer support, a user can upload a screenshot and ask what went wrong. The model can inspect the image, read visible text, and generate a troubleshooting explanation.
In ecommerce, VLMs support visual search and product discovery. A shopper can upload a product image and search for similar items. In document AI, VLMs help interpret scanned forms, invoices, tables, charts, and reports. In education, they can explain diagrams or solve visual questions. In healthcare, VLMs may support professional workflows that involve medical images and notes, though expert review remains essential.
Why Vision-Language Models Matter for Business
Businesses store important information in visual formats: screenshots, dashboards, charts, scanned documents, product photos, design files, PDFs, forms, and training videos. Text-only AI cannot fully understand these assets unless they are converted into text, and even then, layout and visual context may be lost.
VLMs make AI more useful for real workflows because users can ask questions about what they see. A support agent can analyze an error screenshot. A finance team can ask questions about a chart. A retail team can search by product photo. An operations team can review inspection images. This is why VLMs are becoming important for enterprise AI assistants and document/image workflows.
Limitations of Vision-Language Models
Vision-language models can still make mistakes. They may misread small text, misunderstand charts, overlook details, or hallucinate visual facts. A model may confidently describe something that is not actually present in the image. It may also struggle with blurry images, low-resolution screenshots, complex diagrams, or domain-specific visuals.
Evaluation is also difficult. A VLM may produce a fluent answer that sounds correct but uses weak visual evidence. Encord notes that better evaluation strategies are crucial for building reliable vision-language systems. For high-risk domains like healthcare, legal workflows, finance, and safety inspection, VLM outputs should support human review rather than replace expert judgment.
Common Mistakes About VLMs
A common mistake is thinking VLMs are only image captioning tools. Image captioning is one task, but VLMs are broader. They can support visual question answering, image-text retrieval, document understanding, grounding, multimodal search, and visual reasoning.
Another mistake is assuming a VLM understands every image like a human. VLMs can be powerful, but they do not always understand context, causality, intent, or domain-specific details. Teams building with VLMs should test real user workflows, not only demo images.
Future of Vision-Language Models
Vision-language models are becoming more capable and more integrated into AI assistants. The next wave will likely focus on better visual reasoning, stronger document understanding, video-language models, improved grounding, multimodal agents, and safer evaluation.
As multimodal AI grows, VLMs will become one of its most important building blocks. They will help AI systems understand screenshots, diagrams, photos, documents, charts, interfaces, and videos more naturally. For businesses, this means more practical AI assistants that can work with the visual information people already use every day.
Suggested Read:
- What Is Multimodal AI? Complete Beginner’s Guide to AI Beyond Text
- How Multimodal AI Works
- Multimodal Reasoning
- Multimodal AI Examples
- Multimodal AI Use Cases
FAQ: Vision Language Models Explained
What are vision-language models?
Vision-language models are AI models that connect visual data and language so the system can understand images, screenshots, diagrams, or videos together with text prompts or questions.
How do vision-language models work?
They use visual encoders to process images, language components to process text, and alignment mechanisms to connect visual and textual meaning.
What are examples of VLM tasks?
Common tasks include image captioning, visual question answering, image-text retrieval, visual grounding, document understanding, and chart interpretation.
What is the difference between VLMs and LLMs?
LLMs are language-first models, while VLMs connect language with visual data. VLMs are better for tasks involving images, screenshots, charts, documents, or video frames.
Are vision-language models part of multimodal AI?
Yes. VLMs are a major type of multimodal AI focused on vision and language.
What are the limitations of vision-language models?
Limitations include visual hallucinations, weak grounding, difficulty with small text, chart errors, poor performance on blurry images, and reliability challenges in high-risk domains.
Final Takeaway
Vision language models explained simply means understanding AI systems that connect what a model sees with what users ask in language. VLMs combine computer vision and natural language processing so AI can describe images, answer visual questions, interpret charts, search by image, and support document workflows.
For AIML Insights readers, the next useful pages are What Is Multimodal AI, How Multimodal AI Works, and Multimodal Reasoning.