
Multimodal reasoning is the AI ability to connect information from different data types, such as text, images, audio, video, documents, and charts, to reach a more useful conclusion. It goes beyond recognizing inputs separately and focuses on reasoning across them together.
In Simple Terms
Multimodal reasoning means an AI system can combine clues from different formats before answering. A basic image model might identify objects in a photo. A text model might answer written questions. A multimodal reasoning system can connect the image and the question, compare details, infer relationships, and produce a context-aware answer.
For example, if you upload a chart and ask, “Which product line is losing momentum?” the system must read your question, inspect the chart, understand the trend, compare categories, and explain the conclusion. That is multimodal reasoning. The AI is not only seeing or reading. It is connecting evidence across modalities.
What Makes Multimodal Reasoning Different From Multimodal AI?
Multimodal AI is the broader category. It means an AI system can process multiple data types, such as text, images, audio, video, documents, or sensor data. Multimodal reasoning is a deeper capability inside that category. It means the system can use those inputs to solve a problem, explain a relationship, or make a decision.
A multimodal AI model might describe an image. A multimodal reasoning model might answer why something in the image matters based on the user’s question. This distinction is important because not every multimodal system reasons well. Some systems can recognize visual or audio inputs but still struggle with multi-step logic, spatial relationships, chart interpretation, or complex scientific reasoning.
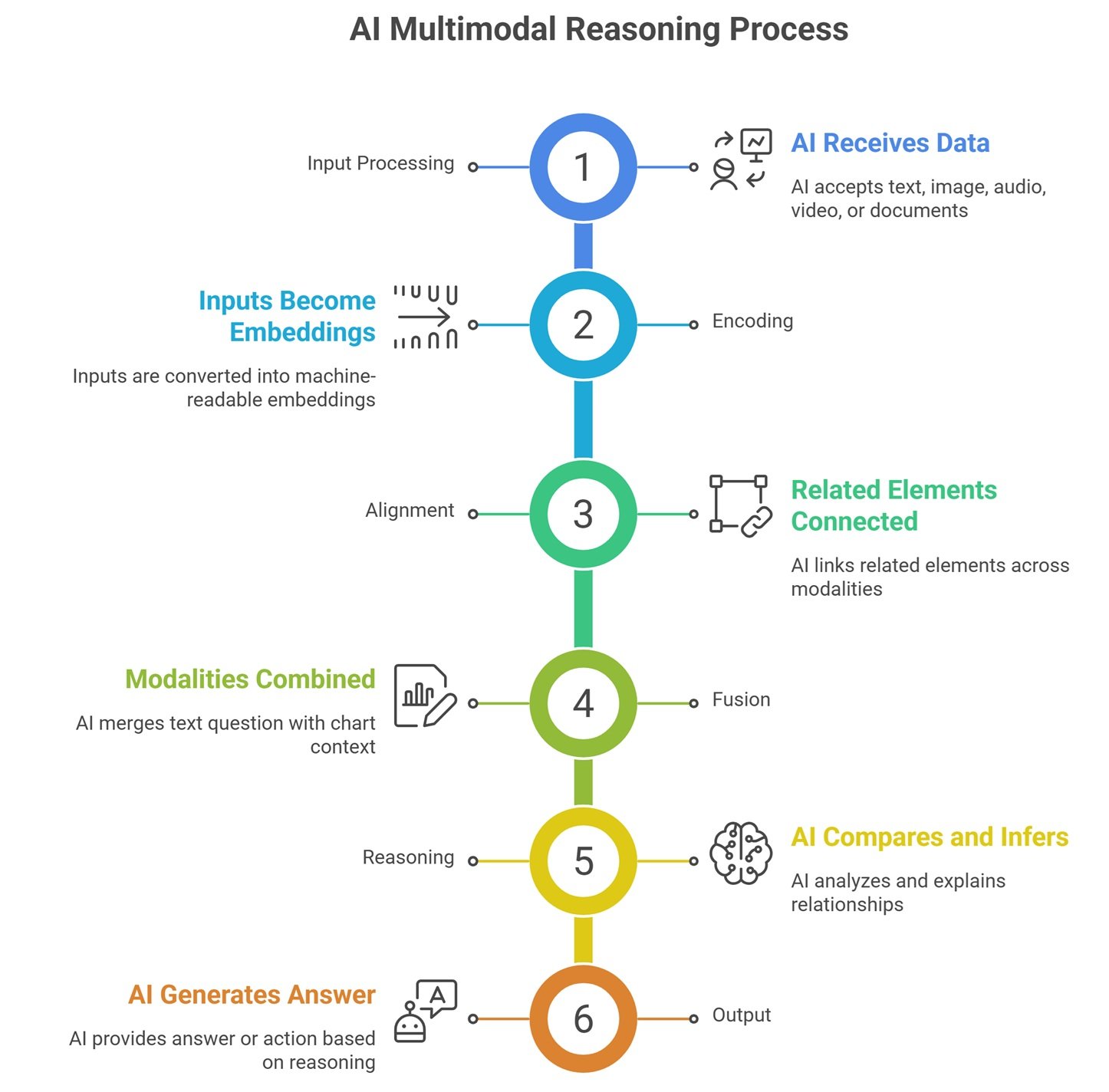
How Multimodal Reasoning Works
Multimodal reasoning usually starts with input processing. The system receives one or more modalities, such as text, an image, a video, an audio file, or a document. Each input is converted into embeddings, which are numerical representations of meaning.
The model then aligns these representations so related information can be connected. For example, a phrase like “the red object on the left” must connect to the correct visual region. A chart label must connect to the right data line. A spoken question must connect to the relevant video segment. After alignment, the model reasons across the combined context and generates an answer.
Core Stages of Multimodal Reasoning
| Stage | What Happens | Example |
| Input processing | AI receives text, image, audio, video, or documents | User uploads a chart |
| Encoding | Inputs become embeddings | Chart and question become machine-readable |
| Alignment | Related elements are connected | “Revenue drop” linked to chart line |
| Fusion | Modalities are combined | Text question + chart context |
| Reasoning | AI compares, infers, and explains | Identifies declining product line |
| Output | AI generates answer or action | “Product B declined after Q2” |
Example: Visual Reasoning
Visual reasoning is one of the clearest forms of multimodal reasoning. It requires the AI to understand spatial relationships, object details, layout, diagrams, or visual patterns. For example, if a user asks, “Which object is blocking the doorway?” the AI must inspect the image, identify the doorway, locate objects nearby, and infer which one blocks access.
Recent research and benchmarks show that visual reasoning remains difficult, especially when tasks require spatial structure, relational reasoning, or minimal text cues. A 2026 Visual Reasoning Benchmark paper defines visual reasoning as deriving answers by perceiving and operating on spatial and relational structure in images.
Example: Text and Image Reasoning
Text-image reasoning is common in AI assistants, education tools, customer support, and document workflows. A user may upload a screenshot and ask what went wrong. The AI must read visible text, inspect interface elements, understand the question, and connect the evidence.
This is different from simple image captioning. Captioning might say, “This is a screenshot of an error.” Reasoning goes further: it explains why the error might be happening and what the user should check next. Research on Multimodal Chain-of-Thought proposed using both language and vision in a two-stage process that separates rationale generation from answer inference, showing how reasoning can be structured across text and image inputs.
Example: Chart and Document Reasoning
Documents often contain text, tables, charts, footnotes, diagrams, and layout information. Multimodal reasoning helps AI understand not just the words but also how the information is arranged. This matters for financial reports, scientific papers, invoices, insurance claims, legal documents, and business dashboards.
For example, a user may ask, “Does this report show improving performance?” The AI must read the written summary, inspect the chart, compare numbers, and explain whether the evidence supports the claim. This is a high-value business use case because many real decisions depend on mixed visual and textual evidence.
Why Multimodal Reasoning Matters
Multimodal reasoning matters because real-world decisions usually require more than one type of information. A doctor may compare scans with notes. A support agent may compare screenshots with logs. A robot may combine visual input with spoken instructions. A business analyst may interpret dashboards, charts, and written commentary together.
Without reasoning, multimodal AI is mostly perception. With reasoning, it becomes more useful for decision support, explanation, automation, search, and agents. This is why multimodal reasoning is closely connected to vision-language models, multimodal agents, document AI, robotics, healthcare AI, and enterprise copilots.
Multimodal Reasoning vs Multimodal Agents
Multimodal reasoning helps AI understand and infer across data types. Multimodal agents use that reasoning to plan and act. The difference is action.
A multimodal reasoning system might explain what is happening in a screenshot. A multimodal agent might inspect the screenshot, search documentation, create a support ticket, and send the user a response. Reasoning is the thinking layer. Agentic behavior is the action layer. Many future AI systems will combine both.
Benefits of Multimodal Reasoning
The biggest benefit is better context. Text alone often misses important visual, audio, or document signals. Multimodal reasoning helps the model connect evidence from multiple sources before responding.
It also improves user experience. People can ask questions naturally using images, voice, charts, videos, or files. Businesses can use it for document review, customer support, visual inspection, training, robotics, and analytics. In education, it can help explain diagrams and visual problems. In accessibility, it can convert visual context into clear language.
Limitations and Risks
Multimodal reasoning is still imperfect. Models can misread images, misunderstand charts, ignore small details, or connect the wrong visual element to the wrong text. Milvus highlights common limitations in multimodal systems, including difficulty aligning cross-modal data, high computational costs, and generalization challenges in real-world scenarios.
Reasoning failures can be especially risky because the output may sound confident. Apple’s machine learning research notes that chain-of-thought reasoning in vision-language models is important for interpretability and trustworthiness, but also points out that short-answer training can generalize poorly on tasks requiring detailed explanations. In sensitive domains such as healthcare, finance, law, and safety systems, multimodal reasoning should support expert review rather than replace it.
Common Mistakes About Multimodal Reasoning
A common mistake is assuming that if an AI model can process images, it can reason correctly about them. Image understanding and reasoning are not the same. A model may identify objects but still fail to infer relationships, quantities, causes, or contradictions.
Another mistake is trusting the model’s explanation without checking the evidence. Multimodal reasoning can produce plausible but wrong answers when inputs are noisy, incomplete, ambiguous, or poorly aligned. Teams building multimodal systems should evaluate not only final answers but also whether the model used the right evidence.
Future of Multimodal Reasoning
The future of multimodal reasoning will likely involve better vision-language models, stronger chart understanding, improved document reasoning, multimodal chain-of-thought methods, and agentic systems that can reason before taking action. Researchers are also focusing more on benchmarks that test spatial, visual, scientific, and real-world reasoning rather than simple recognition.
As multimodal AI becomes common in assistants, enterprise tools, robotics, education, and healthcare workflows, reasoning quality will become one of the most important differentiators. The best systems will not just process multiple modalities. They will connect them accurately, explain the logic, and know when uncertainty is high.
Suggested Read:
- What Is Multimodal AI? Complete Beginner’s Guide to AI Beyond Text
- How Multimodal AI Works
- Multimodal Agents
- Multimodal AI Examples
- Multimodal AI Use Cases
FAQ: Multimodal Reasoning Explained
What is multimodal reasoning?
Multimodal reasoning is the ability of AI to connect information from multiple data types, such as text, images, audio, video, documents, and charts, to answer questions or solve problems.
How does multimodal reasoning work?
It processes different modalities, converts them into embeddings, aligns related information, combines the context, and reasons across that combined evidence.
What is an example of multimodal reasoning?
An AI system that looks at a chart and answers a written question about the trend is using multimodal reasoning.
How is multimodal reasoning different from multimodal AI?
Multimodal AI processes multiple data types. Multimodal reasoning uses those data types to infer relationships, explain meaning, or solve problems.
Why is multimodal reasoning important?
It helps AI work with real-world information, where useful context often appears across text, images, audio, video, charts, and documents.
What are the limitations of multimodal reasoning?
Limitations include visual misunderstanding, poor cross-modal alignment, hallucinations, difficulty with spatial reasoning, high compute costs, and weak reliability in complex tasks.
Final Takeaway
Multimodal reasoning is what helps AI move from simply processing multiple inputs to actually connecting evidence across them. It allows models to reason over text, images, audio, video, documents, charts, and visual context.
This capability is becoming essential for AI assistants, document intelligence, visual search, robotics, healthcare workflows, education, and enterprise AI. To continue learning, read What Is Multimodal AI, How Multimodal AI Works, and Multimodal Agents next.