
Multimodal agents are AI systems that can understand multiple data types, reason over them, and take actions. Unlike simple chatbots, they can process text, images, audio, video, documents, and sometimes sensor data before planning what to do next. This makes them important for customer support, robotics, document workflows, healthcare, and enterprise automation.
In Simple Terms
A multimodal agent is an AI agent that can “see,” “hear,” “read,” reason, and act across different kinds of information. A normal AI chatbot mainly responds to text. A multimodal AI agent can inspect a screenshot, listen to a voice message, read a PDF, understand a chart, check a system, and decide what action should happen next.
The word “agent” matters here. A multimodal model can understand different inputs, but a multimodal agent uses that understanding to complete tasks. It may call tools, search files, update a record, generate a response, route a ticket, or ask for confirmation before taking action. Google Cloud describes AI agents as systems that can process multimodal information and facilitate transactions or business processes, which captures the shift from passive answering to active task completion.
What Are Multimodal Agents?
Multimodal agents are AI agents designed to process and act on different data formats. These formats may include text, images, audio, video, documents, charts, screenshots, code, and sensor data. The agent combines these inputs to understand the user’s goal and then decides the next step.
For example, a customer may upload a screenshot of an app error and record a short voice message explaining the issue. A multimodal agent can read the screenshot, transcribe or interpret the audio, compare the issue with support documentation, and generate a response or escalate the case. That is different from a basic chatbot that only answers typed questions.
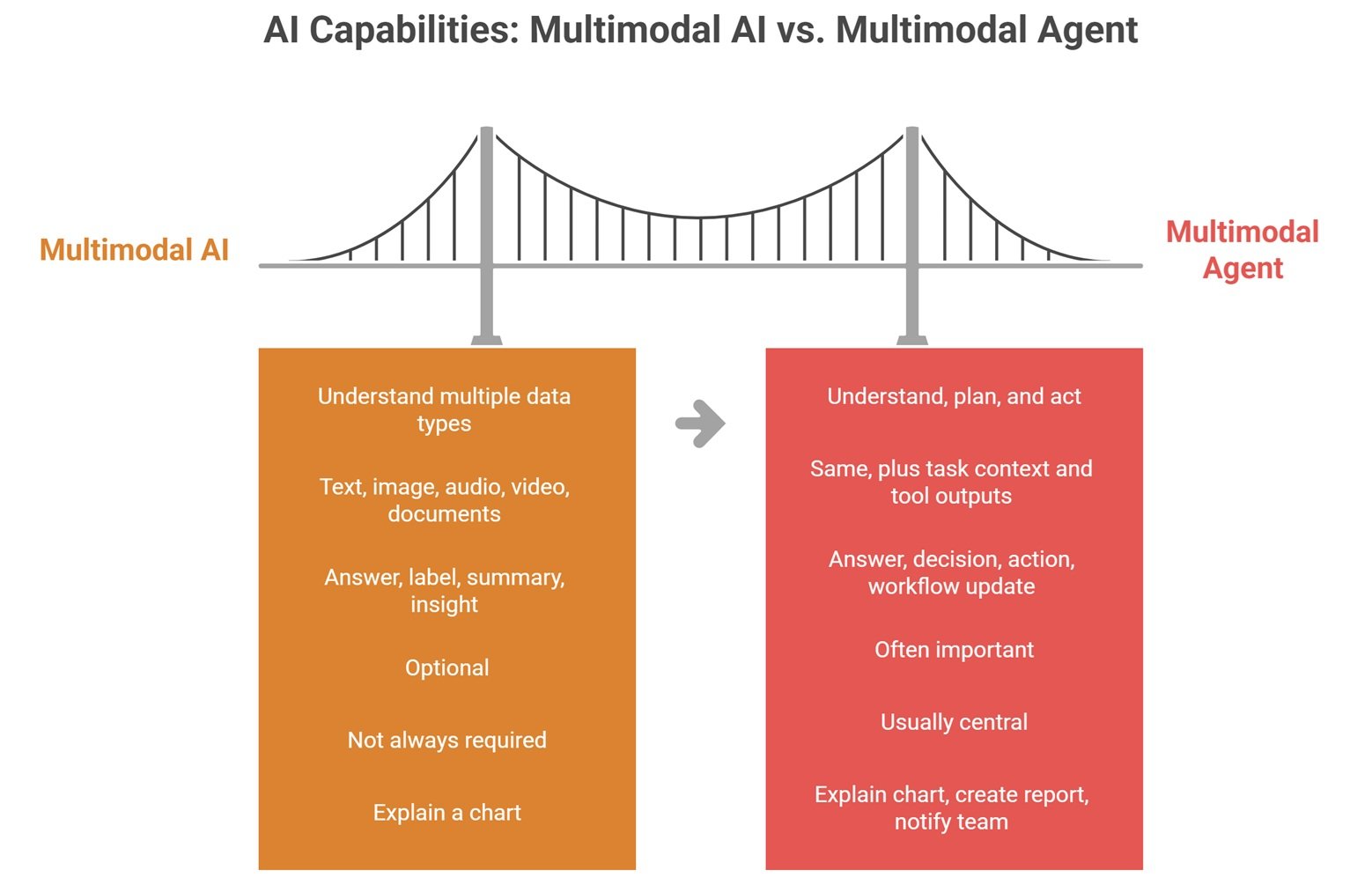
Multimodal Agents vs Multimodal AI
Multimodal AI and multimodal agents are related, but they are not identical. Multimodal AI focuses on understanding multiple data types. Multimodal agents add goal-directed behavior and action.
A multimodal AI model may answer, “This image shows a damaged cable.” A multimodal agent may go further: identify the damaged cable, check the asset database, create a maintenance ticket, notify the right technician, and summarize the evidence. The agentic layer turns perception into a workflow. NVIDIA describes agentic AI systems as autonomous agents that reason, plan, and act across complex multi-step workflows, which is the key difference.
| Feature | Multimodal AI | Multimodal Agent |
| Main role | Understand multiple data types | Understand, plan, and act |
| Inputs | Text, image, audio, video, documents | Same, plus task context and tool outputs |
| Output | Answer, label, summary, insight | Answer, decision, action, workflow update |
| Memory | Optional | Often important |
| Tool use | Not always required | Usually central |
| Example | Explain a chart | Explain chart, create report, notify team |
How Multimodal Agents Work
Most multimodal agents follow a loop: perceive, interpret, plan, act, and evaluate. First, the agent receives input from one or more modalities. This could be a typed prompt, uploaded image, call recording, live video feed, document, dashboard screenshot, or sensor stream.
Then the agent converts inputs into machine-readable representations, often through encoders and embeddings. It interprets the user’s goal, gathers missing context, and chooses a plan. After that, it may call tools, retrieve documents, query a database, generate a response, or take an approved action. The strongest systems also evaluate whether the result was correct, safe, and useful before finalizing the interaction.
Core Components of a Multimodal Agent
A multimodal agent usually contains several components working together. The first is a perception layer, which processes text, images, audio, video, and documents. The second is a reasoning model, often a multimodal LLM or a system connected to one. The third is memory, which stores relevant context across turns or tasks.
The fourth component is planning. The agent decides what steps are needed to complete the goal. The fifth is tool use, where the agent interacts with APIs, search systems, CRMs, databases, browsers, calendars, ticketing platforms, or robotics controllers. The final component is evaluation and guardrails, which help prevent unsafe actions, hallucinations, or privacy violations.
Why Vision-Language Models Matter
Vision-language models are important because many multimodal agents need to connect visual input with language instructions. A robot may need to understand “pick up the red mug near the laptop.” A support agent may need to interpret a screenshot and explain what went wrong. A document agent may need to understand a scanned form and answer questions about it.
Research on vision-language-action models describes systems that unify visual perception, language comprehension, and action generation into one framework, especially for robotics and embodied AI tasks. This is a key direction for multimodal agents because future agents will not only understand images and text; they will use that understanding to make decisions and act.
Real-World Examples of Multimodal Agents
A customer support multimodal agent can combine a user’s typed issue, screenshot, device photo, previous chat history, and voice tone. It can understand the issue, retrieve troubleshooting steps, ask clarifying questions, and create a support ticket if needed.
A healthcare workflow agent may help organize medical scans, clinical notes, forms, and patient messages for professional review. A manufacturing agent may analyze camera feeds, machine sounds, sensor readings, and maintenance logs to identify possible equipment problems. A document workflow agent may read invoices, forms, signatures, tables, and emails before routing approvals or flagging missing fields.
Multimodal Agents in Customer Support
Customer support is one of the clearest use cases because modern support conversations are rarely text-only. Customers send screenshots, videos, photos, voice messages, invoices, and chat messages. A multimodal agent can combine all of this context to understand the actual issue faster.
Microsoft has discussed the need to evaluate agents across voice, text, and visual channels because customer interactions include intent, sentiment, urgency, context, and visual quality. Its Multimodal Agent Score concept evaluates understanding, reasoning, and response quality across modalities. This shows why multimodal agents need more than answer accuracy; they also need reliable perception, reasoning, and response quality.
Multimodal Agents in Robotics
Robotics is a natural home for multimodal agents because robots must understand the physical world. A robot may process camera input, speech, lidar, touch sensors, location data, and task instructions at the same time. It then needs to plan and execute actions safely.
For example, a warehouse robot may receive the instruction, “Move the damaged box near the loading door.” The agent must understand the language, identify the box visually, navigate the space, avoid obstacles, and complete the task. This requires perception, reasoning, planning, and action in one loop.
Multimodal Agents in Enterprise Workflows
Enterprise teams work with documents, dashboards, calls, emails, spreadsheets, screenshots, and software systems. A multimodal agent can help connect these scattered inputs and take practical actions. For example, it can analyze a dashboard screenshot, summarize key changes, retrieve related documents, draft an update, and create a task for the right team.
This is where multimodal agents become more valuable than simple AI assistants. They can support multi-step workflows across departments such as customer support, finance, operations, HR, legal, product, and IT. The agent does not only answer questions. It helps move work forward.
Benefits of Multimodal Agent
The biggest benefit of multimodal agents is better context. Text alone often misses what the user is actually showing, saying, or experiencing. Images, audio, video, documents, and tool outputs can provide missing signals.
Another benefit is workflow automation. A multimodal agent can inspect evidence, reason about what it means, choose a next step, and call tools. This can reduce manual triage in customer support, speed up document processing, improve field service workflows, and make enterprise assistants more useful. For users, the interaction feels more natural because they can show or say what they need instead of typing everything.
Limitations and Risks
Multimodal agents can still make mistakes. They may misread an image, misunderstand speech, overlook a detail in a video, or interpret a document incorrectly. When agents also take actions, these mistakes can become more serious. A wrong interpretation may lead to a wrong ticket, wrong workflow update, or wrong recommendation.
Security and privacy are also major concerns. Multimodal agents may process faces, voices, screenshots, medical documents, financial records, customer data, or internal systems. Enterprises need access controls, approval flows, logging, red teaming, and clear boundaries around what an agent can do. This is especially important when agents can call tools or operate across business systems.
Common Mistakes About Multimodal Agents
A common mistake is thinking that any multimodal model is automatically an agent. A model that analyzes images and text is multimodal, but it becomes agentic only when it can pursue goals, plan steps, use tools, or act in a workflow.
Another mistake is over-automating too early. Not every multimodal workflow should become fully autonomous. For high-risk domains such as healthcare, finance, legal, security, and industrial operations, human review should remain part of the workflow. A safer strategy is to start with assistive agents, then gradually increase autonomy after evaluation.
Future of Multimodal Agents
Multimodal agents are likely to become a major part of AI assistants, robotics, enterprise software, customer support, and automation. As models improve across vision, speech, video, documents, and tool use, agents will become better at handling real-world tasks that involve messy information.
The future direction is toward agents that combine perception, memory, reasoning, planning, tools, and feedback. These systems will not only answer typed prompts. They will inspect screenshots, listen to calls, understand documents, observe environments, retrieve context, and act with safeguards. That is why multimodal agents are an important next step in practical AI.
Suggested Read:
- What Is Multimodal AI? Complete Beginner’s Guide to AI Beyond Text
- How Multimodal AI Works
- Multimodal AI Use Cases
- Multimodal AI Examples
- What Is an AI Agent? A Simple Explanation With Examples
FAQ: Multimodal Agents Explained
What are multimodal agents?
Multimodal agents are AI agents that can process multiple data types, such as text, images, audio, video, and documents, then reason and take actions based on that information.
How do multimodal agents work?
They process inputs through modality-specific systems, combine the information into shared context, reason over the task, plan steps, use tools, and generate responses or actions.
What is the difference between AI agents and multimodal agents?
AI agents can plan and act toward goals. Multimodal agents add the ability to understand multiple data types such as images, audio, video, and documents.
What are examples of multimodal agents?
Examples include customer support agents that analyze screenshots, robotics agents that use vision and speech, document agents that process PDFs and forms, and enterprise assistants that understand dashboards and calls.
Why are multimodal agents important?
They are important because real-world tasks involve more than text. Multimodal agents can understand richer context and support more practical automation.
What are the risks of multimodal agents?
Risks include visual errors, speech misunderstanding, hallucinations, privacy exposure, unsafe tool use, and over-automation without human review.
Final Takeaway
Multimodal agents combine multimodal understanding with agentic action. They can process text, images, audio, video, documents, and tool outputs, then reason, plan, and take steps toward a goal.
This makes them important for customer support, robotics, enterprise workflows, document processing, healthcare support, manufacturing, and future AI assistants. To continue learning, read What Is Multimodal AI, How Multimodal AI Works, and Vision-Language Models Explained next.