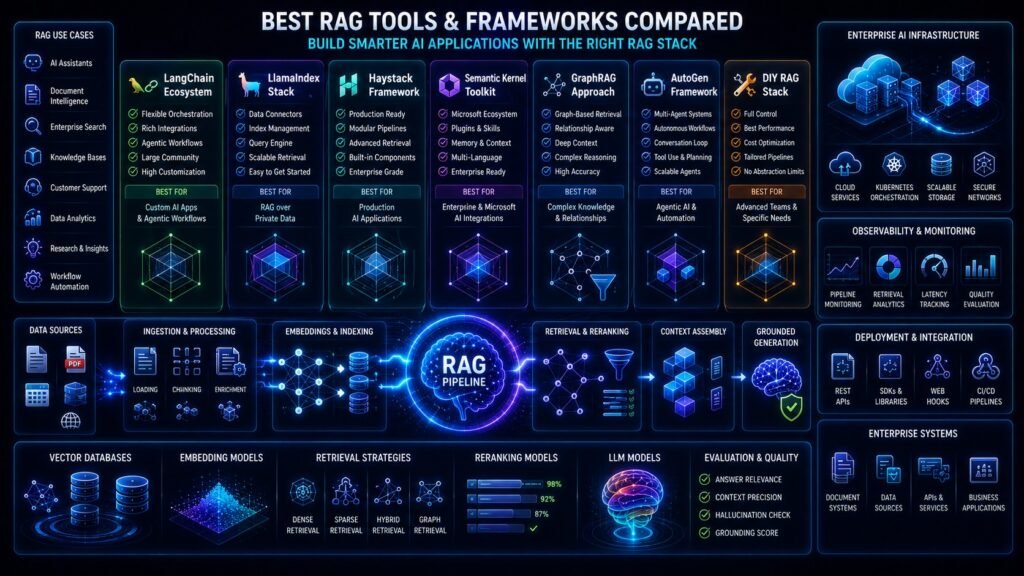
Best RAG Tools and Frameworks Compared for Building AI Applications
Retrieval-Augmented Generation (RAG) has become one of the most important architectures in modern AI systems.
Organizations increasingly use RAG to build:
- enterprise search systems
- AI copilots
- customer support assistants
- legal AI platforms
- healthcare retrieval systems
- analytics assistants
- AI research tools
- document intelligence applications
- operational AI workflows
RAG improves Large Language Models by retrieving external information before generating responses.
This dramatically improves:
- grounding
- factual reliability
- enterprise knowledge access
- hallucination reduction
- real-time information retrieval
As RAG adoption grows, the ecosystem of:
RAG tools and frameworks
has expanded rapidly.
Modern RAG systems often combine multiple infrastructure layers including:
- orchestration frameworks
- vector databases
- embedding systems
- retrieval pipelines
- rerankers
- observability platforms
- deployment infrastructure
- evaluation frameworks
Choosing the right stack is becoming increasingly difficult.
Some tools focus on:
- orchestration
- retrieval workflows
- indexing
- semantic search
- vector infrastructure
- monitoring
- enterprise deployment
- AI agents
Others specialize in:
- low-latency retrieval
- enterprise scalability
- developer simplicity
- observability
- workflow automation
This is why understanding the strengths and limitations of different RAG frameworks has become essential for AI engineers, enterprise architects, ML teams, startup founders, and AI product developers.
In this guide, you will learn the best RAG tools and frameworks, how they compare, when to use them, enterprise deployment considerations, orchestration systems, vector databases, retrieval infrastructure, observability tools, evaluation platforms, and how modern production RAG architectures are evolving.
In Simple Terms
What Is a RAG Framework?
A RAG framework helps developers build systems that:
- retrieve external information
- process retrieved context
- send context into an LLM
- generate grounded responses
Instead of building every component manually, frameworks simplify orchestration and infrastructure management.
Why Are RAG Tools Important?
Modern RAG systems involve many moving parts:
- document ingestion
- embeddings
- vector databases
- retrieval logic
- reranking
- prompt orchestration
- inference
- monitoring
RAG tools simplify these workflows.
Understanding the RAG Technology Stack
A production RAG architecture usually includes:
| Layer | Purpose |
| Orchestration Framework | Coordinate workflows |
| Embedding Models | Semantic representation |
| Vector Database | Store embeddings |
| Retrieval Engine | Retrieve context |
| Reranking Layer | Improve relevance |
| LLM Inference | Generate responses |
| Monitoring Tools | Observe performance |
| Deployment Infrastructure | Scale production systems |
Different frameworks specialize in different layers.
Best RAG Orchestration Frameworks
LangChain
LangChain is one of the most widely used RAG orchestration frameworks.
It helps developers build:
- retrieval pipelines
- AI agents
- tool-calling systems
- prompt workflows
- conversational memory systems
LangChain became popular because it provides modular building blocks for complex AI workflows.
Strengths of LangChain
LangChain offers:
- extensive integrations
- large ecosystem support
- flexible chaining
- agentic AI workflows
- production orchestration features
It is especially useful for teams building complex multi-step AI systems.
Weaknesses of LangChain
LangChain can become:
- overly complex
- difficult to debug
- orchestration-heavy
- slower in large pipelines
Many teams eventually simplify workflows after rapid prototyping.
Best Use Cases for LangChain
LangChain works well for:
- AI agents
- multi-tool workflows
- enterprise orchestration
- complex retrieval systems
- workflow automation
LlamaIndex
LlamaIndex focuses heavily on data retrieval and indexing for LLM applications.
It is designed specifically for:
- RAG pipelines
- document indexing
- retrieval workflows
- enterprise data integration
Many developers find LlamaIndex simpler than LangChain for retrieval-focused applications.
Strengths of LlamaIndex
LlamaIndex excels at:
- document indexing
- retrieval pipelines
- data connectors
- retrieval abstraction
- enterprise knowledge integration
It simplifies many retrieval-heavy workflows.
Weaknesses of LlamaIndex
LlamaIndex may feel:
- less flexible for complex orchestration
- narrower in agentic workflows
- less mature for advanced automation compared to LangChain
Best Use Cases for LlamaIndex
LlamaIndex works well for:
- enterprise search
- document retrieval
- knowledge assistants
- semantic search systems
- RAG-focused applications
Haystack
deepset created Haystack as a production-focused NLP and retrieval framework.
Haystack focuses strongly on:
- search pipelines
- retrieval systems
- enterprise deployment
- production-grade NLP
It has become popular in enterprise AI infrastructure.
Strengths of Haystack
Haystack offers:
- strong retrieval architecture
- production pipeline design
- scalable search systems
- modular retrieval workflows
It works especially well for enterprise search applications.
Weaknesses of Haystack
Haystack may require:
- more infrastructure knowledge
- stronger engineering expertise
- additional setup complexity
compared to beginner-friendly frameworks.
Best Use Cases for Haystack
Haystack is strong for:
- enterprise search
- production retrieval systems
- scalable semantic search
- enterprise NLP infrastructure
DSPy
Stanford NLP Group developed DSPy to optimize prompt engineering and LLM workflows programmatically.
DSPy introduces a more declarative approach to AI pipelines.
It increasingly attracts developers building:
- optimized RAG systems
- agentic workflows
- retrieval-aware prompting
- adaptive pipelines
Strengths of DSPy
DSPy helps automate:
- prompt optimization
- retrieval tuning
- reasoning workflows
- modular AI programming
It supports experimentation-heavy AI systems well.
Weaknesses of DSPy
DSPy still has:
- a smaller ecosystem
- steeper conceptual learning curve
- evolving production tooling
compared to older frameworks.
Best Use Cases for DSPy
DSPy works well for:
- research-heavy AI systems
- optimization workflows
- adaptive retrieval systems
- advanced LLM orchestration
Semantic Kernel
Microsoft created Semantic Kernel to support enterprise AI orchestration and agentic systems.
It integrates strongly with:
- enterprise workflows
- cloud infrastructure
- AI plugins
- orchestration systems
Strengths of Semantic Kernel
Semantic Kernel offers:
- enterprise integration
- structured orchestration
- plugin systems
- agentic AI workflows
- cloud ecosystem alignment
Weaknesses of Semantic Kernel
Semantic Kernel may feel:
- enterprise-heavy
- cloud-opinionated
- less flexible for smaller prototypes
Best Use Cases for Semantic Kernel
It works well for:
- enterprise copilots
- Microsoft-centric environments
- agentic enterprise workflows
- business automation systems
Best Vector Databases for RAG
Vector databases are foundational for modern RAG systems.
Pinecone
Pinecone is one of the most popular managed vector databases.
It focuses on:
- scalability
- managed infrastructure
- fast vector retrieval
- enterprise reliability
Strengths of Pinecone
Pinecone offers:
- easy deployment
- managed scaling
- production reliability
- low operational overhead
Weaknesses of Pinecone
Potential downsides include:
- infrastructure cost
- managed-service dependency
- reduced low-level customization
Best Use Cases for Pinecone
Pinecone works well for:
- enterprise AI
- production search systems
- scalable retrieval pipelines
Weaviate
Weaviate combines vector search with graph-like retrieval capabilities.
It supports:
- semantic search
- hybrid retrieval
- metadata filtering
- modular AI integrations
Strengths of Weaviate
Weaviate offers:
- hybrid retrieval
- flexible architecture
- strong metadata filtering
- open-source support
Weaknesses of Weaviate
Some deployments may require:
- infrastructure tuning
- operational management
- scaling expertise
Best Use Cases for Weaviate
Weaviate works well for:
- hybrid retrieval systems
- GraphRAG
- enterprise semantic search
Qdrant
Qdrant focuses heavily on performance and filtering.
It increasingly attracts production RAG deployments.
Strengths of Qdrant
Qdrant offers:
- strong filtering
- retrieval performance
- efficient indexing
- modern architecture
Weaknesses of Qdrant
Compared to older ecosystems, Qdrant may have:
- fewer enterprise integrations
- smaller community support
Best Use Cases for Qdrant
Qdrant works well for:
- low-latency retrieval
- enterprise filtering
- scalable semantic retrieval
Milvus
Zilliz develops Milvus as a large-scale vector database.
Milvus is optimized for:
- large indexes
- distributed search
- enterprise-scale vector retrieval
Strengths of Milvus
Milvus offers:
- distributed scalability
- large-scale indexing
- enterprise retrieval infrastructure
Weaknesses of Milvus
Milvus deployments may require:
- advanced infrastructure expertise
- operational management
Best Use Cases for Milvus
Milvus works well for:
- massive enterprise datasets
- distributed retrieval systems
- large-scale semantic search
Chroma
Chroma focuses on simplicity and developer friendliness.
It became popular for lightweight RAG prototypes.
Strengths of Chroma
Chroma offers:
- simplicity
- easy local deployment
- beginner-friendly setup
Weaknesses of Chroma
Chroma may struggle with:
- large-scale production deployments
- advanced enterprise scaling
Best Use Cases for Chroma
Chroma works well for:
- prototypes
- local AI systems
- experimentation
Best Observability and Evaluation Tools
Production RAG systems increasingly require monitoring and evaluation.
LangSmith
LangChain developed LangSmith for AI observability.
It helps teams monitor:
- traces
- prompts
- retrieval pipelines
- agent workflows
Arize AI
Arize AI focuses on AI observability and evaluation.
It supports:
- hallucination tracking
- retrieval analysis
- production monitoring
- AI debugging
Why Observability Matters
Modern RAG systems contain many moving parts.
Failures may occur in:
- retrieval
- reranking
- orchestration
- embeddings
- inference
- APIs
Observability improves production reliability significantly.
Best RAG Framework Comparison Table
| Tool | Best For | Strength | Weakness |
| LangChain | AI orchestration | Flexibility | Complexity |
| LlamaIndex | Retrieval systems | Indexing simplicity | Less orchestration depth |
| Haystack | Enterprise search | Production retrieval | Setup complexity |
| DSPy | Optimization workflows | Adaptive pipelines | Smaller ecosystem |
| Semantic Kernel | Enterprise AI | Business integrations | Cloud-centric |
| Pinecone | Managed vectors | Scalability | Cost |
| Weaviate | Hybrid retrieval | Flexibility | Operational tuning |
| Qdrant | Performance retrieval | Filtering | Smaller ecosystem |
| Milvus | Massive datasets | Distributed scale | Infrastructure complexity |
| Chroma | Prototyping | Simplicity | Limited scalability |
How to Choose the Right RAG Framework
Framework selection depends heavily on:
- team expertise
- scalability requirements
- infrastructure budget
- orchestration complexity
- retrieval needs
- deployment model
There is no universal “best” framework.
Best Framework for Beginners
For beginners:
- LlamaIndex
- Chroma
often provide the easiest onboarding experience.
Best Framework for Enterprise Search
For enterprise search systems:
- Haystack
- Weaviate
- Pinecone
- LlamaIndex
are often strong choices.
Best Framework for AI Agents
For agentic AI systems:
- LangChain
- Semantic Kernel
- DSPy
are increasingly popular.
Best Framework for Scalability
For large-scale production infrastructure:
- Pinecone
- Milvus
- Qdrant
often perform well.
Why Hybrid Architectures Are Becoming Common
Modern production RAG systems increasingly combine multiple tools.
For example:
- LangChain for orchestration
- LlamaIndex for indexing
- Pinecone for vector retrieval
- Arize AI for monitoring
This creates modular enterprise architectures.
Why Simpler Architectures Often Win
Many teams overengineer RAG systems.
Complex orchestration may create:
- latency overhead
- debugging difficulty
- infrastructure complexity
- maintenance burden
Simple retrieval pipelines often outperform overly complicated systems.
Why Agentic RAG Is Changing Framework Design
Modern AI systems increasingly combine:
- retrieval
- planning
- tool calling
- workflow automation
- memory systems
- orchestration
This is driving rapid evolution in RAG tooling ecosystems.
Why Evaluation Is Becoming Essential
Organizations increasingly benchmark:
- retrieval precision
- answer faithfulness
- hallucination rates
- latency
- grounding quality
- semantic relevance
Evaluation tooling is becoming foundational for enterprise deployment.
Future of RAG Tools and Frameworks
The RAG ecosystem is evolving rapidly.
Major trends include:
- agentic retrieval systems
- GraphRAG architectures
- multimodal retrieval
- retrieval-aware reasoning
- adaptive orchestration
- autonomous retrieval optimization
- enterprise AI observability
Future enterprise AI systems will increasingly combine:
- semantic retrieval
- AI agents
- orchestration frameworks
- monitoring infrastructure
- scalable vector databases
- workflow automation
into unified AI infrastructure ecosystems.
Suggested
- What Is RAG in AI
- How RAG Works
- Vector Database for RAG
- RAG Deployment Basics
- RAG Monitoring
- RAG Observability
- GraphRAG Explained
- Agentic RAG Explained
FAQ: Best RAG Tools and Frameworks
What are the best RAG tools and frameworks?
Popular RAG frameworks include LangChain, LlamaIndex, Haystack, DSPy, Semantic Kernel, Pinecone, Weaviate, and Qdrant.
Which framework is best for beginners?
LlamaIndex and Chroma are often easier for beginners because they simplify retrieval workflows.
What is the difference between LangChain and LlamaIndex?
LangChain focuses heavily on orchestration and AI workflows, while LlamaIndex specializes in retrieval and indexing.
Which vector database is best for RAG?
The best vector database depends on scalability, filtering, infrastructure preferences, and deployment complexity.
Do enterprises use multiple RAG tools together?
Yes. Many production systems combine orchestration frameworks, vector databases, monitoring tools, and evaluation platforms into modular architectures.
Final Takeaway
Understanding the modern ecosystem of RAG tools and frameworks is becoming essential because enterprise AI systems increasingly depend on scalable retrieval pipelines, orchestration systems, semantic search infrastructure, vector databases, observability platforms, and grounded generation architectures.
No single framework solves every problem.
The best RAG stack depends on:
- retrieval complexity
- enterprise scale
- orchestration requirements
- deployment preferences
- operational expertise
- monitoring needs
Organizations that understand how different RAG frameworks fit together can build more scalable, reliable, explainable, and production-ready AI systems.
That capability is becoming foundational for enterprise search platforms, AI copilots, customer support systems, legal AI, healthcare retrieval systems, analytics assistants, and next-generation enterprise AI infrastructure.