Retrieval-Augmented Generation (RAG) has rapidly become one of the most important architectures in modern enterprise AI.
Organizations increasingly use RAG systems for:
- enterprise search
- AI copilots
- customer support assistants
- legal AI systems
- healthcare knowledge retrieval
- financial intelligence platforms
- document intelligence
- conversational analytics
- research automation
RAG dramatically improves Large Language Models by grounding responses using external information retrieval.
However, building a prototype RAG pipeline is very different from deploying a production-ready enterprise RAG system.
This is where many organizations struggle.
A simple demo may work well locally, but production deployments introduce entirely new challenges:
- scalability
- latency
- infrastructure complexity
- vector indexing
- orchestration
- monitoring
- security
- hallucination management
- retrieval quality
- enterprise reliability
This is why:
RAG deployment basics
have become increasingly important for AI engineers, ML teams, enterprise architects, and AI infrastructure teams.
Modern organizations need deployment strategies capable of supporting:
- high-volume retrieval workloads
- scalable inference systems
- enterprise security
- real-time document updates
- observability
- retrieval monitoring
- grounded AI generation
- low-latency user experiences
Understanding how to deploy RAG systems properly is becoming foundational for production AI infrastructure.
In this guide, you will learn how RAG deployment works, production architecture patterns, infrastructure layers, vector databases, orchestration pipelines, monitoring systems, scaling strategies, security considerations, deployment workflows, optimization techniques, and best practices for building scalable enterprise RAG systems.
In Simple Terms
What Is RAG?
Retrieval-Augmented Generation improves AI systems by retrieving external information before generating responses.
Instead of relying only on pretrained model memory, RAG retrieves contextual information dynamically.
What Does “RAG Deployment” Mean?
RAG deployment means moving a retrieval pipeline from experimentation into a scalable production environment.
This includes deploying:
- vector databases
- embedding pipelines
- retrievers
- rerankers
- APIs
- orchestration systems
- monitoring infrastructure
- LLM inference layers
into enterprise-ready infrastructure.
Easy Analogy
Imagine building a prototype search assistant for internal company documents.
A demo may work for 5 users locally.
But enterprise deployment means supporting:
- thousands of users
- live document updates
- secure retrieval
- scalable APIs
- monitoring dashboards
- low latency
- high reliability
This requires production infrastructure.
Why RAG Deployment Is Challenging
Many organizations underestimate how complex production RAG systems become.
Unlike standalone LLM APIs, RAG systems involve multiple infrastructure layers working together.
A production deployment may include:
- ingestion pipelines
- chunking systems
- embedding generation
- vector indexing
- semantic retrieval
- reranking
- orchestration layers
- inference APIs
- caching systems
- monitoring dashboards
Every layer affects reliability.
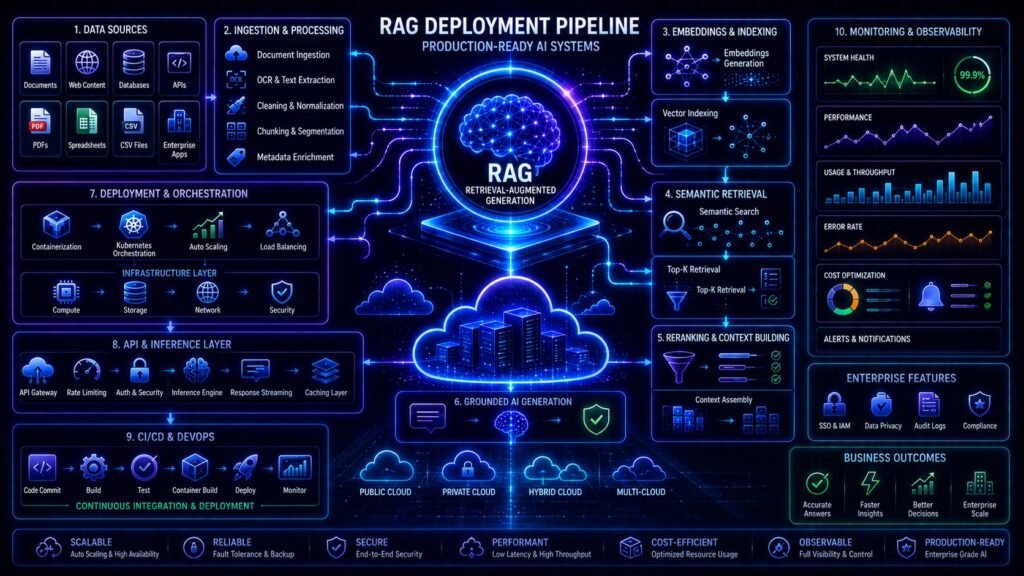
Understanding a Production RAG Architecture
A modern enterprise RAG system usually contains:
- data ingestion pipelines
- preprocessing systems
- embedding generation
- vector databases
- retrieval orchestration
- reranking systems
- LLM inference
- monitoring infrastructure
These components work together continuously.
Core Components of a Production RAG System
| Component | Purpose |
| Data Ingestion | Collect enterprise data |
| Chunking Pipeline | Split information intelligently |
| Embeddings | Represent semantic meaning |
| Vector Database | Store searchable embeddings |
| Retriever | Find contextual information |
| Reranker | Improve retrieval precision |
| LLM | Generate grounded responses |
| Monitoring Layer | Observe production behavior |
Each layer affects deployment quality significantly.
Step 1: Data Ingestion Infrastructure
Production RAG systems require scalable ingestion pipelines.
Organizations ingest:
- PDFs
- spreadsheets
- databases
- APIs
- enterprise documents
- CRM systems
- cloud storage
- operational systems
Ingestion pipelines must support continuous updates.
Why Incremental Updates Matter
Enterprise knowledge changes constantly.
Production systems must handle:
- document modifications
- new records
- deleted content
- updated policies
- operational changes
Incremental indexing reduces infrastructure overhead.
Step 2: Preprocessing and Chunking
Retrieved information quality depends heavily on chunking.
Production systems often implement:
- semantic chunking
- recursive chunking
- metadata-aware chunking
- hierarchical chunking
Chunking directly affects retrieval precision.
Why Chunking Matters in Deployment
Poor chunking creates:
- fragmented context
- weak retrieval
- hallucinations
- latency overhead
- inefficient vector indexing
Good chunking improves grounded generation significantly.
Step 3: Embedding Generation Pipelines
Embeddings convert chunks into semantic vectors.
Production deployment requires embedding infrastructure capable of:
- high throughput
- scalable indexing
- incremental updates
- efficient batching
- low latency
Embedding pipelines become critical infrastructure layers.
Why Embedding Choice Matters
Different embedding models optimize for:
- retrieval accuracy
- multilingual support
- latency
- cost efficiency
- semantic understanding
Embedding quality directly affects retrieval relevance.
Step 4: Vector Database Deployment
Vector databases are foundational for RAG deployment.
Popular production vector databases include:
- Pinecone
- Weaviate
- Qdrant
- Milvus
- Chroma
These systems support semantic retrieval at scale.
Why Vector Databases Matter
Production vector systems optimize:
- similarity search
- ANN indexing
- semantic retrieval
- scalability
- distributed infrastructure
Traditional databases struggle with semantic vector retrieval.
Step 5: Retrieval Orchestration
Retrieval orchestration determines:
- query routing
- metadata filtering
- hybrid retrieval logic
- retrieval ranking
- semantic search behavior
Modern enterprise systems increasingly use orchestration frameworks.
Why Hybrid Retrieval Is Becoming Standard
Production systems increasingly combine:
- semantic retrieval
- keyword search
- metadata filtering
- structured querying
- GraphRAG
- reranking systems
Hybrid retrieval improves enterprise reliability significantly.
Step 6: Reranking Infrastructure
Rerankers improve retrieval precision.
After initial retrieval, reranking systems reorder results using deeper semantic evaluation.
This improves:
- groundedness
- answer quality
- hallucination reduction
- contextual relevance
Reranking becomes increasingly important at scale.
Step 7: LLM Inference Deployment
The inference layer generates grounded responses.
Deployment options include:
- cloud-hosted APIs
- self-hosted inference
- GPU clusters
- serverless inference
- edge deployment
Inference infrastructure affects scalability heavily.
Cloud vs Self-Hosted RAG Deployment
| Category | Cloud APIs | Self-Hosted |
| Setup Speed | Fast | Slower |
| Infrastructure Control | Limited | High |
| Operational Complexity | Lower | Higher |
| Scalability | Excellent | Flexible |
| Security Control | Moderate | Strong |
| Cost Predictability | Variable | More controllable |
Organizations choose based on operational needs.
Why Caching Is Critical
Production RAG systems often experience repeated queries.
Caching improves:
- latency
- throughput
- infrastructure efficiency
- cost optimization
Modern systems implement:
- embedding caching
- retrieval caching
- response caching
to improve scalability.
Step 8: Monitoring and Observability
Production RAG systems require continuous monitoring.
Organizations increasingly monitor:
- retrieval precision
- hallucination rates
- answer faithfulness
- latency
- grounding quality
- vector search performance
- API failures
Observability is essential for enterprise reliability.
Why RAG Monitoring Is Difficult
Unlike traditional APIs, RAG systems involve multiple AI layers.
Failures may occur in:
- ingestion pipelines
- retrieval systems
- vector indexing
- reranking
- orchestration
- inference generation
Root-cause analysis becomes more complex.
Common RAG Deployment Challenges
Production RAG systems introduce operational complexity.
Latency Problems
Retrieval pipelines increase response times.
Hallucination Risks
Weak retrieval weakens grounded generation.
Vector Database Scaling
Large enterprise datasets require distributed indexing.
Infrastructure Costs
Embedding generation and inference can become expensive.
Retrieval Noise
Irrelevant retrieval reduces answer quality.
Why Security Matters in Enterprise RAG
Enterprise AI systems often access sensitive information.
Production systems must support:
- role-based access control
- encryption
- audit logging
- retrieval permissions
- compliance policies
- secure APIs
Security becomes foundational for enterprise deployment.
Why Multi-Tenancy Matters
Enterprise AI platforms often support multiple departments or customers.
Multi-tenant RAG systems require:
- isolated retrieval
- secure indexing
- permission-aware search
- tenant-specific embeddings
This adds architectural complexity.
Why Real-Time Updates Matter
Production systems increasingly require live knowledge synchronization.
Examples include:
- customer support updates
- compliance policy changes
- operational dashboards
- inventory systems
- financial reporting
Real-time indexing improves enterprise reliability significantly.
Why Agentic AI Is Changing RAG Deployment
Modern AI agents increasingly combine:
- RAG pipelines
- tool calling
- orchestration systems
- workflow automation
- semantic retrieval
- memory systems
This creates more dynamic deployment architectures.
Enterprise Use Cases for Production RAG Systems
Enterprise Search Platforms
Employees retrieve organizational knowledge conversationally.
Customer Support AI
Support copilots retrieve troubleshooting guidance dynamically.
Healthcare Knowledge Systems
AI systems retrieve grounded clinical information securely.
Financial Intelligence Platforms
AI retrieves operational reporting and compliance knowledge.
Legal AI Systems
RAG retrieves contracts and regulations semantically.
AI Analytics Assistants
Executives query operational intelligence conversationally.
Why Evaluation Is Critical Before Deployment
Organizations increasingly benchmark:
- answer faithfulness
- retrieval precision
- context recall
- hallucination rates
- semantic relevance
- latency
- groundedness
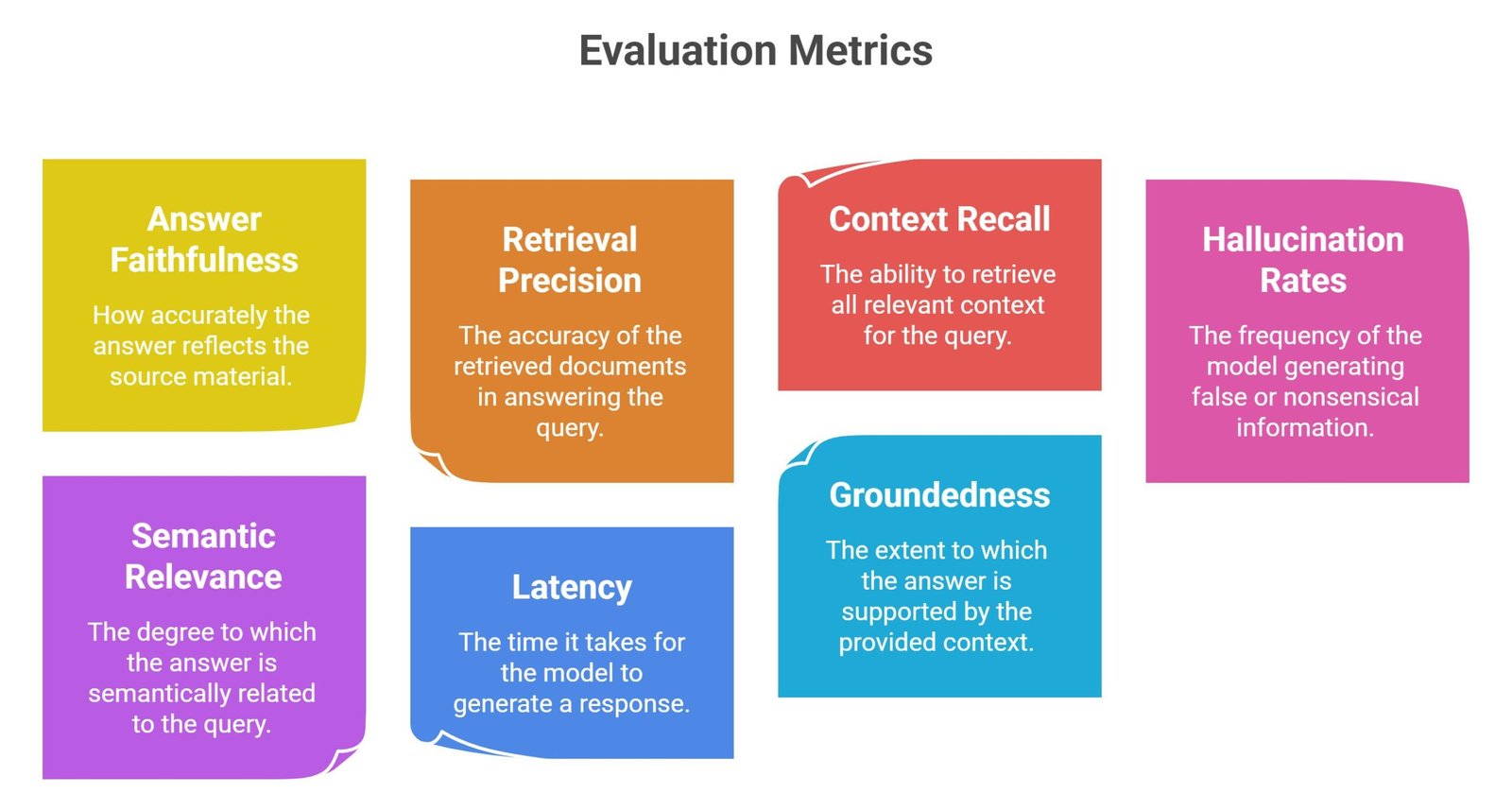
Evaluation determines production readiness.
Best Practices for RAG Deployment
Start With Smaller Architectures
Avoid overengineering early deployments.
Optimize Chunking Carefully
Chunk quality directly affects retrieval precision.
Use Hybrid Retrieval
Hybrid systems improve reliability significantly.
Monitor Hallucinations Continuously
Grounded evaluation must remain ongoing.
Add Metadata Filtering
Metadata improves enterprise retrieval precision.
Build Strong Observability Systems
Monitoring improves operational reliability.
Implement Security Early
Enterprise AI security cannot be optional.
Why Kubernetes Is Popular for RAG Deployment
Many enterprise AI teams deploy RAG systems using Kubernetes because it supports:
- container orchestration
- autoscaling
- deployment management
- distributed workloads
- GPU scheduling
Kubernetes improves production scalability significantly.
Why Retrieval Latency Optimization Matters
Users expect conversational AI systems to respond quickly.
Production systems optimize latency using:
- vector indexing
- caching
- ANN retrieval
- reranking optimization
- query routing
- embedding compression
Latency optimization becomes critical at scale.
Future of RAG Deployment
Enterprise RAG systems are evolving rapidly.
Major trends include:
- agentic RAG systems
- GraphRAG architectures
- multimodal retrieval
- autonomous orchestration
- retrieval-aware agents
- enterprise memory systems
- adaptive retrieval pipelines
Future enterprise AI systems will increasingly combine:
- semantic retrieval
- grounded generation
- orchestration
- AI agents
- enterprise workflows
- scalable observability
into unified AI infrastructure architectures.
Suggested Read:
- What Is RAG in AI
- How RAG Works
- RAG Pipeline Explained
- RAG Monitoring
- RAG Observability
- Reducing Hallucinations in RAG
- RAG Evaluation Metrics
- Vector Database for RAG
FAQ: RAG Deployment Basics
What is RAG deployment?
RAG deployment means deploying retrieval pipelines, vector databases, embeddings, orchestration systems, and LLM infrastructure into production environments.
Why is RAG deployment difficult?
Production RAG systems involve multiple infrastructure layers including retrieval, indexing, orchestration, monitoring, and inference.
What infrastructure is needed for RAG systems?
Production systems usually require vector databases, embedding pipelines, APIs, orchestration layers, monitoring systems, and scalable inference infrastructure.
How do enterprises scale RAG architectures?
Organizations scale RAG using distributed vector databases, caching, orchestration systems, GPU inference, and hybrid retrieval pipelines.
Why does monitoring matter in RAG deployment?
Monitoring helps identify hallucinations, retrieval failures, latency issues, and infrastructure bottlenecks.
Final Takeaway
Understanding RAG deployment basics is becoming essential because enterprise AI systems increasingly depend on scalable retrieval infrastructure, grounded generation, semantic search, orchestration pipelines, and production-grade observability.
Building a RAG prototype is relatively easy, but deploying reliable enterprise RAG systems requires strong infrastructure architecture, monitoring systems, retrieval optimization, security controls, and scalable orchestration.
Organizations that understand how to deploy production-ready RAG systems can build more reliable, intelligent, explainable, and enterprise-grade AI platforms.
That capability is becoming foundational for enterprise search systems, AI copilots, customer support assistants, operational intelligence platforms, legal AI systems, healthcare retrieval systems, and next-generation enterprise AI infrastructure.