LLM vs RAG: What’s the Difference and Which One Should You Use in 2026?
As AI adoption grows, many people hear two common terms: LLM and RAG.
They are related, but not the same.
Some teams assume RAG replaces LLMs. Others think they are competing technologies. In reality, they usually work together.
This guide explains LLM vs RAG in simple language, including differences, use cases, benefits, and how to choose the right approach.
In simple terms
What is an LLM?
A Large Language Model (LLM) is an AI model trained on large text datasets to understand and generate language.
Examples of tasks:
- writing content
- summarizing text
- answering questions
- coding assistance
- translation
What is RAG?
Retrieval-Augmented Generation (RAG) is a system design where an LLM first retrieves relevant information from documents or databases, then uses that information to generate better answers.
RAG is not usually a separate model. It is an architecture.
Easy analogy
Imagine asking a lawyer a question.
LLM Only
The lawyer answers from memory.
RAG System
The lawyer first checks your contract files, then answers using those documents.
That second approach is often more accurate.
Why People Compare LLM vs RAG
Many businesses need answers based on:
- internal company docs
- recent news
- product manuals
- policies
- customer records
- private knowledge bases
A standalone LLM may not know these sources or may invent answers.
RAG helps solve that.
Popular AI Ecosystems Using These Approaches
Many teams build solutions with models from:
These models are often paired with retrieval systems.
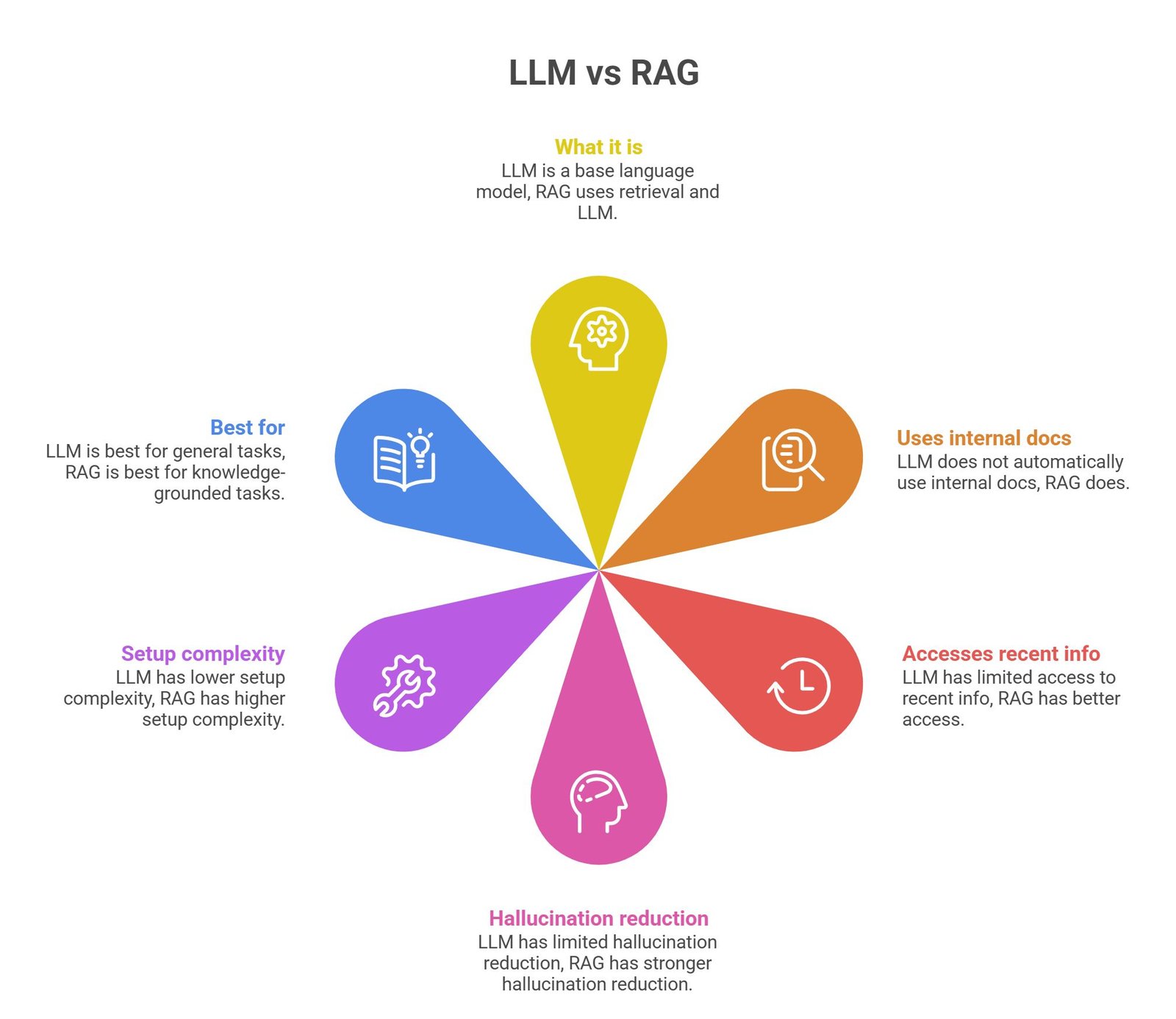
Core Difference: LLM vs RAG
| Feature | LLM | RAG |
| What it is | Base language model | System using retrieval + LLM |
| Uses internal docs | Not automatically | Yes |
| Accesses recent info | Limited | Better |
| Hallucination reduction | Limited | Stronger |
| Setup complexity | Lower | Higher |
| Best for | General tasks | Knowledge-grounded tasks |
How an LLM Works
A standalone LLM uses:
- training knowledge
- prompt context
- reasoning patterns
- token prediction
It generates responses based on what it learned during training and what you provide in the prompt.
Great for:
- writing
- brainstorming
- coding help
- summaries
- generic Q&A
How RAG works
A RAG system usually follows these steps:
Step 1: Receive User Question
Example: “What is our refund policy for enterprise customers?”
Step 2: Retrieve Relevant Sources
Search docs, PDFs, databases, wikis.
Step 3: Send Sources to LLM
The model receives retrieved content.
Step 4: Generate Grounded Answer
Response is based on actual documents.
When to use an LLM only
Choose standalone LLM for:
Content Creation
Blogs, emails, drafts.
Brainstorming
Ideas and outlines.
Coding Support
General development help.
Language Tasks
Rewrite, summarize, translate.
Fast Prototypes
Simple chat apps.
When to use RAG
Choose RAG for:
Company Knowledge Search
Internal documentation Q&A.
Customer Support
Policy-grounded answers.
Legal Search
Contracts and clauses.
Research Assistants
Recent papers or reports.
Enterprise Copilots
Private data access.
Major Benefits of RAG over LLM-only
Better Accuracy
Uses trusted sources.
More Current Answers
Can use updated documents.
Lower Hallucinations
Less guessing.
Explainability
Can show citations.
Private Data Usage
Works with internal knowledge.
Limitations of RAG
More Complex Setup
Needs indexing, retrieval, storage.
Quality Depends on Documents
Bad data = bad answers.
Permissions Matter
Must protect sensitive files.
Retrieval Errors
Wrong chunks can hurt results.
Can RAG work without an LLM?
Usually no.
- RAG typically depends on an LLM to generate final answers.
- Think of retrieval as the research step, and the LLM as the writer.
Real Business Examples: LLM vs RAG
SaaS Company
Support bot answers from product docs.
Ecommerce Brand
AI answers shipping and return policy questions.
Consulting Firm
Employees search frameworks and proposals.
Law Firm
Contract intelligence assistant.
LLM vs RAG vs Fine-Tuning
| Approach | Best Use Case |
| LLM Only | General intelligence tasks |
| RAG | External/private knowledge grounding |
| Fine-Tuning | Specialized behavior/style |
Often businesses combine them.
LLM vs RAG: Common Mistakes Teams Make
Using LLM Only for Internal Docs
May hallucinate.
Building RAG Too Early
Simple apps may not need it.
Ignoring Source Quality
Garbage in, garbage out.
No Monitoring
Need feedback loops.
Overengineering
Start with real user needs.
Future of LLM + RAG
Expect rapid growth in:
- multimodal RAG
- voice document assistants
- autonomous enterprise agents
- personalized retrieval systems
- graph-based retrieval
- lower-latency enterprise search
RAG is becoming core AI infrastructure.
Suggested Read:
- How LLMs Work
- LLM for Knowledge Bases
- LLM for Document Search
- How to Reduce LLM Hallucinations
- LLM Deployment Basics
- LLM for Beginners
FAQ: LLM vs RAG
Is RAG better than an LLM?
Not exactly. RAG uses an LLM plus retrieval.
Does RAG reduce hallucinations?
Often yes, especially with strong sources.
Can startups use RAG?
Yes, especially for support or internal search.
Is RAG expensive?
Depends on scale and architecture.
Should I choose LLM or RAG?
Choose based on whether you need external or private knowledge.
Final takeaway
The real comparison is not LLM vs RAG as enemies. RAG is usually a way to make LLMs more useful for real business knowledge tasks.
Use standalone LLMs for general creativity and productivity. Use RAG when truth, freshness, and company data matter.