Retrieval-Augmented Generation (RAG) systems are rapidly becoming the foundation of enterprise AI applications.
Organizations increasingly deploy RAG for:
- enterprise search
- AI copilots
- customer support assistants
- legal AI systems
- healthcare retrieval
- financial intelligence
- analytics assistants
- document intelligence platforms
- operational AI systems
RAG dramatically improves Large Language Models by retrieving external information before generating responses.
However, one major production challenge quickly appears:
Latency.
Many RAG systems work well in prototypes but become frustratingly slow in production environments.
Users expect conversational AI systems to respond almost instantly.
But production RAG pipelines often introduce delays caused by:
- vector retrieval
- embedding generation
- reranking
- orchestration layers
- database lookups
- LLM inference
- network overhead
- document retrieval complexity
This is why:
RAG latency optimization
has become one of the most important topics in production AI engineering.
Modern enterprise AI systems must optimize:
- retrieval speed
- inference latency
- vector search performance
- orchestration overhead
- caching efficiency
- indexing speed
- reranking performance
- end-to-end response time
Organizations that fail to optimize latency often face:
- poor user experience
- infrastructure cost escalation
- scalability bottlenecks
- reduced adoption
- operational inefficiency
Understanding how to optimize RAG latency is becoming essential for AI engineers, ML infrastructure teams, enterprise architects, and production AI developers.
In this guide, you will learn what causes latency in RAG systems, how retrieval pipelines affect response speed, optimization strategies, vector database tuning, caching systems, reranking optimization, inference acceleration, orchestration improvements, scalability techniques, monitoring workflows, and best practices for building high-performance production RAG systems.
In Simple Terms
What Is RAG?
Retrieval-Augmented Generation improves AI systems by retrieving external information before generating responses.
Instead of relying only on pretrained model memory, RAG retrieves contextual information dynamically.
What Is RAG Latency?
RAG latency refers to the total time required for a system to:
- receive a query
- retrieve relevant information
- process context
- generate a grounded response
Lower latency creates faster AI experiences.
Easy Analogy
Imagine asking a librarian a question.
If the librarian searches thousands of books manually before answering, responses become slow.
But if books are indexed intelligently and frequently requested answers are cached, responses become much faster.
RAG optimization works similarly.
Why RAG Systems Become Slow
Many production RAG pipelines contain multiple infrastructure layers.
A typical query may involve:
- embedding generation
- vector search
- metadata filtering
- reranking
- API orchestration
- database queries
- LLM inference
Each stage adds latency.
Understanding the RAG Latency Pipeline
A production RAG request often follows this workflow:
- user query arrives
- query embedding generation
- vector similarity search
- metadata filtering
- reranking
- context assembly
- LLM inference
- response generation
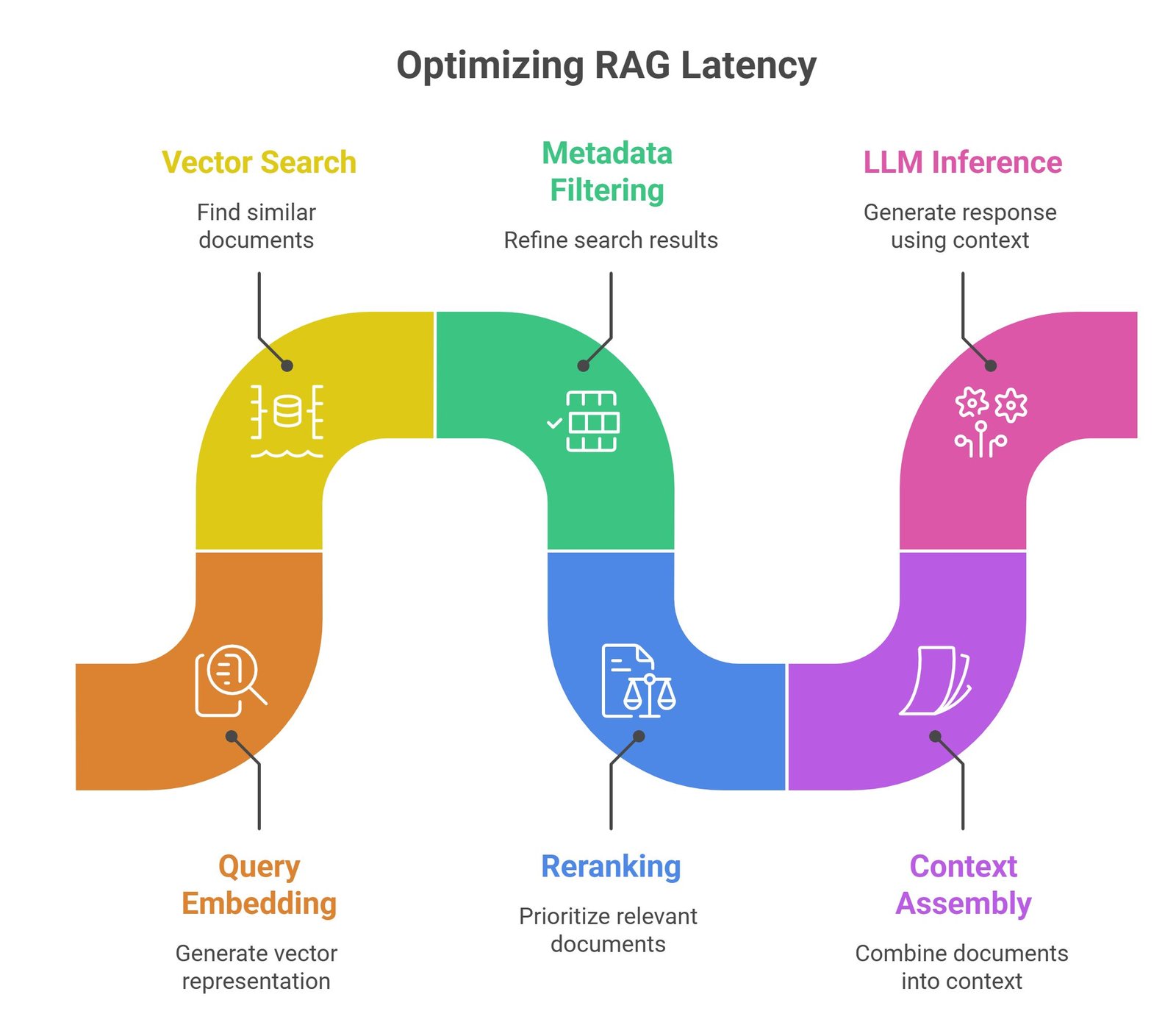
Optimization requires improving every stage.
Main Causes of RAG Latency
| Source | Description |
| Embedding Generation | Query vector creation |
| Vector Search | Similarity retrieval |
| Large Indexes | Massive retrieval datasets |
| Reranking | Deep relevance scoring |
| LLM Inference | Token generation delays |
| API Calls | External orchestration overhead |
| Network Latency | Distributed infrastructure delays |
| Poor Chunking | Excessive retrieval load |
Understanding bottlenecks is the first step toward optimization.
Why Vector Search Latency Matters
Vector retrieval is one of the largest contributors to RAG latency.
Large enterprise datasets may contain:
- millions of embeddings
- distributed indexes
- metadata layers
- hybrid retrieval pipelines
Without optimization, retrieval becomes slow quickly.
How ANN Search Reduces Latency
Most production vector databases use:
Approximate Nearest Neighbor (ANN)
search instead of exact vector matching.
ANN dramatically improves retrieval speed while maintaining acceptable relevance.
This is foundational for scalable RAG systems.
Why Embedding Size Affects Performance
Large embedding dimensions increase:
- memory usage
- vector indexing overhead
- retrieval complexity
- storage requirements
Smaller optimized embeddings often improve latency significantly.
Why Chunking Impacts Latency
Chunking affects:
- retrieval volume
- context size
- reranking complexity
- token usage
Poor chunking creates unnecessary retrieval overhead.
Large Chunks vs Small Chunks
| Chunk Type | Benefit | Drawback |
| Large Chunks | More context | Higher latency |
| Small Chunks | Faster retrieval | Less context |
| Balanced Chunks | Better tradeoff | Requires tuning |
Balanced chunking is critical for production optimization.
Why Retrieval Count Matters
Many systems retrieve too many chunks.
Excessive retrieval increases:
- reranking overhead
- inference token usage
- orchestration complexity
- response latency
Reducing retrieval count often improves performance dramatically.
Why Reranking Can Become Expensive
Rerankers improve answer quality but introduce computational overhead.
Cross-encoder rerankers are often slower because they evaluate semantic relevance deeply.
Production systems must balance:
- retrieval quality
- latency
- infrastructure cost
This tradeoff is central to optimization.
Why Caching Is Essential
Caching is one of the most effective latency optimization techniques.
Production systems increasingly use:
- embedding caching
- retrieval caching
- response caching
- query caching
Caching avoids redundant computation.
Query Caching
Repeated enterprise questions are common.
Examples include:
- policy lookups
- support requests
- operational analytics
- HR questions
Caching frequent queries dramatically reduces latency.
Embedding Caching
Repeated embedding generation wastes infrastructure resources.
Embedding caches reduce:
- compute overhead
- API latency
- embedding costs
This improves throughput significantly.
Retrieval Caching
Retrieval results for common queries can also be cached.
This reduces:
- vector search operations
- reranking overhead
- orchestration complexity
Retrieval caching improves scalability substantially.
Why Hybrid Search Can Improve Performance
Hybrid retrieval combines:
- vector search
- keyword search
- metadata filtering
Strategic routing may reduce retrieval complexity.
For example:
simple keyword queries may avoid expensive semantic retrieval entirely.
Why Metadata Filtering Improves Latency
Metadata filtering narrows retrieval scope.
Instead of searching entire vector indexes, systems search filtered subsets.
Examples include filtering by:
- department
- document type
- customer account
- geography
- permissions
This dramatically improves retrieval speed.
Why Distributed Infrastructure Adds Complexity
Enterprise RAG systems often operate across:
- multiple APIs
- distributed databases
- cloud services
- orchestration layers
- inference clusters
Network overhead increases latency significantly.
Why Co-Locating Infrastructure Matters
Keeping vector databases and inference systems geographically close reduces:
- network latency
- orchestration overhead
- API delays
Infrastructure placement becomes increasingly important at scale.
Why GPU Inference Optimization Matters
LLM inference often becomes the largest latency contributor.
Optimization strategies include:
- quantization
- batching
- speculative decoding
- GPU acceleration
- model distillation
Inference optimization dramatically improves response speed.
Quantization for Faster RAG Systems
Quantization reduces model size by lowering numerical precision.
Benefits include:
- lower memory usage
- faster inference
- reduced infrastructure costs
Many enterprise deployments rely heavily on quantized inference.
Why Smaller Models Are Growing in Importance
Large models improve reasoning quality but increase latency.
Many production systems increasingly use:
- smaller specialized models
- distilled models
- routing architectures
to optimize speed-performance tradeoffs.
Why Streaming Responses Improve UX
Even if full inference takes time, streaming improves perceived performance.
Users receive partial responses immediately.
This creates faster conversational experiences.
Why Orchestration Layers Affect Latency
Modern RAG systems often include orchestration frameworks such as:
- LangChain
- LlamaIndex
- agentic pipelines
- tool-calling systems
Complex orchestration may introduce unnecessary delays.
Why Simpler Pipelines Often Perform Better
Many production systems become overengineered.
Excessive orchestration increases:
- latency
- infrastructure complexity
- debugging difficulty
Simpler retrieval architectures often outperform overly complex pipelines.
Why Monitoring Matters for Latency Optimization
Organizations increasingly monitor:
- retrieval latency
- vector search speed
- inference time
- reranking overhead
- cache hit rates
- API performance
Continuous observability improves optimization significantly.
Common RAG Latency Bottlenecks
Large Vector Indexes
Massive embedding collections increase retrieval overhead.
Excessive Retrieval Counts
Too many retrieved chunks increase processing cost.
Slow Rerankers
Cross-encoders may become expensive.
Network Delays
Distributed systems increase orchestration latency.
Large Context Windows
Huge prompts slow inference dramatically.
Poor Caching Strategies
Repeated computations waste infrastructure resources.
Why Real-Time Indexing Creates Challenges
Enterprise systems increasingly require live updates.
Examples include:
- support documentation
- operational dashboards
- financial systems
- inventory platforms
Real-time indexing may introduce infrastructure complexity and latency overhead.
Why Vector Database Choice Matters
Different vector databases optimize for different workloads.
Factors include:
- ANN indexing quality
- distributed scaling
- metadata filtering
- memory efficiency
- retrieval throughput
Choosing the wrong database may increase latency dramatically.
Popular Vector Databases for Fast RAG Systems
| Database | Strength |
| Pinecone | Managed scalability |
| Qdrant | Fast retrieval |
| Weaviate | Hybrid search |
| Milvus | Large-scale indexing |
| Chroma | Simpler local deployments |
Database selection affects production performance heavily.
Enterprise Use Cases Where Latency Matters Most
Customer Support AI
Slow responses damage user experience.
AI Copilots
Real-time workflows require low latency.
Enterprise Search
Employees expect fast conversational retrieval.
Financial Intelligence Systems
Operational decisions require rapid access to information.
Healthcare Retrieval Systems
Clinical workflows depend on responsiveness.
AI Analytics Assistants
Executives expect conversational analytics instantly.
Best Practices for RAG Latency Optimization
Reduce Retrieval Scope
Retrieve fewer but higher-quality chunks.
Optimize Chunk Sizes
Balanced chunks improve retrieval efficiency.
Use ANN Search
Approximate search dramatically improves scalability.
Implement Aggressive Caching
Caching reduces repeated computation overhead.
Minimize Reranking Overhead
Use reranking selectively.
Compress Context Windows
Smaller prompts improve inference speed.
Optimize Infrastructure Placement
Reduce network overhead where possible.
Use Quantized Models
Smaller optimized models improve inference latency.
Monitor Performance Continuously
Observability improves production optimization.
Why Adaptive Retrieval Is Emerging
Modern systems increasingly use:
- dynamic retrieval counts
- query-aware pipelines
- adaptive reranking
- semantic routing
This improves both latency and relevance.
Why Agentic AI Changes Latency Optimization
Agentic systems introduce:
- multi-step orchestration
- tool calling
- iterative retrieval
- planning workflows
Without optimization, agents may create severe latency overhead.
Production agentic systems require careful orchestration design.
RAG Latency Optimization vs Quality Tradeoffs
| Optimization | Benefit | Tradeoff |
| Smaller Models | Faster inference | Lower reasoning quality |
| Fewer Chunks | Faster retrieval | Less context |
| Simpler Pipelines | Lower latency | Reduced flexibility |
| Aggressive Caching | Faster responses | Stale information risk |
| Quantization | Lower infrastructure cost | Slight accuracy reduction |
Optimization always involves balancing performance and quality.
Future of RAG Performance Optimization
RAG infrastructure is evolving rapidly.
Major trends include:
- adaptive retrieval systems
- retrieval-aware inference
- speculative decoding
- retrieval compression
- GraphRAG optimization
- edge AI retrieval
- multimodal retrieval acceleration
Future enterprise AI systems will increasingly combine:
- semantic retrieval
- intelligent routing
- caching layers
- lightweight inference
- adaptive orchestration
into highly optimized AI infrastructure architectures.
Suggested Read:
- What Is RAG in AI
- How RAG Works
- Vector Database for RAG
- RAG Monitoring
- RAG Deployment Basics
- Reducing Hallucinations in RAG
- RAG Observability
- RAG Evaluation Metrics
FAQ: RAG Latency Optimization
What causes latency in RAG systems?
Latency usually comes from vector retrieval, reranking, embedding generation, orchestration overhead, and LLM inference.
How do you reduce RAG latency?
Optimization strategies include ANN indexing, caching, chunk optimization, metadata filtering, and inference acceleration.
Why are vector databases important for latency optimization?
Vector databases optimize semantic retrieval speed using ANN indexing and distributed search infrastructure.
Does reranking increase latency?
Yes. Reranking improves answer quality but adds computational overhead.
What is the fastest RAG architecture?
Fast systems usually use optimized vector search, aggressive caching, lightweight inference models, and simplified orchestration.
Final Takeaway
Understanding RAG latency optimization is becoming essential because enterprise AI systems increasingly depend on fast semantic retrieval, scalable inference infrastructure, grounded AI generation, and responsive conversational experiences.
Prototype RAG pipelines often perform poorly in production because retrieval systems, reranking layers, orchestration frameworks, and inference pipelines introduce substantial latency overhead.
Organizations that understand how to optimize RAG latency can build faster, more scalable, more reliable, and more production-ready AI systems.
That capability is becoming foundational for enterprise search platforms, AI copilots, customer support assistants, operational intelligence systems, financial AI applications, healthcare retrieval systems, and next-generation enterprise AI infrastructure.