Multimodal LLMs Explained: How AI Understands Text, Images & More
Traditional Large Language Models (LLMs) became popular by understanding and generating text. They can answer questions, summarize content, write code, and help with research.
But AI is moving beyond text.
Today, many advanced systems can process images, audio, video, documents, and text together. These are called multimodal LLMs.
This guide explains multimodal LLMs in simple language, including how they work, examples, and why they matter.
In simple terms
A multimodal LLM is:
A language model that can understand or generate multiple types of data, not just text.
These data types may include:
- text
- images
- audio
- video
- charts
- documents
- screenshots
Instead of reading only words, the model can interpret different forms of information together.
Why Multimodal LLMs Matter
Real life is not text-only.
Businesses and users work with:
- photos
- scanned PDFs
- voice notes
- presentations
- product images
- dashboards
- videos
Multimodal AI helps combine all of these into one workflow.
Traditional LLM vs Multimodal LLM
| Feature | Traditional LLM | Multimodal LLM |
| Text Input | Yes | Yes |
| Image Understanding | No / Limited | Yes |
| Audio Understanding | No / Limited | Yes |
| Video Analysis | No / Limited | Yes |
| OCR / Documents | Limited | Stronger |
| Use Cases | Text tasks | Real-world mixed media tasks |
Easy analogy
Think of two assistants:
- Text-only assistant = reads emails only
- Multimodal assistant = reads emails, views images, listens to voice notes, checks charts, and summarizes video meetings
That second assistant is far more useful in many workplaces.
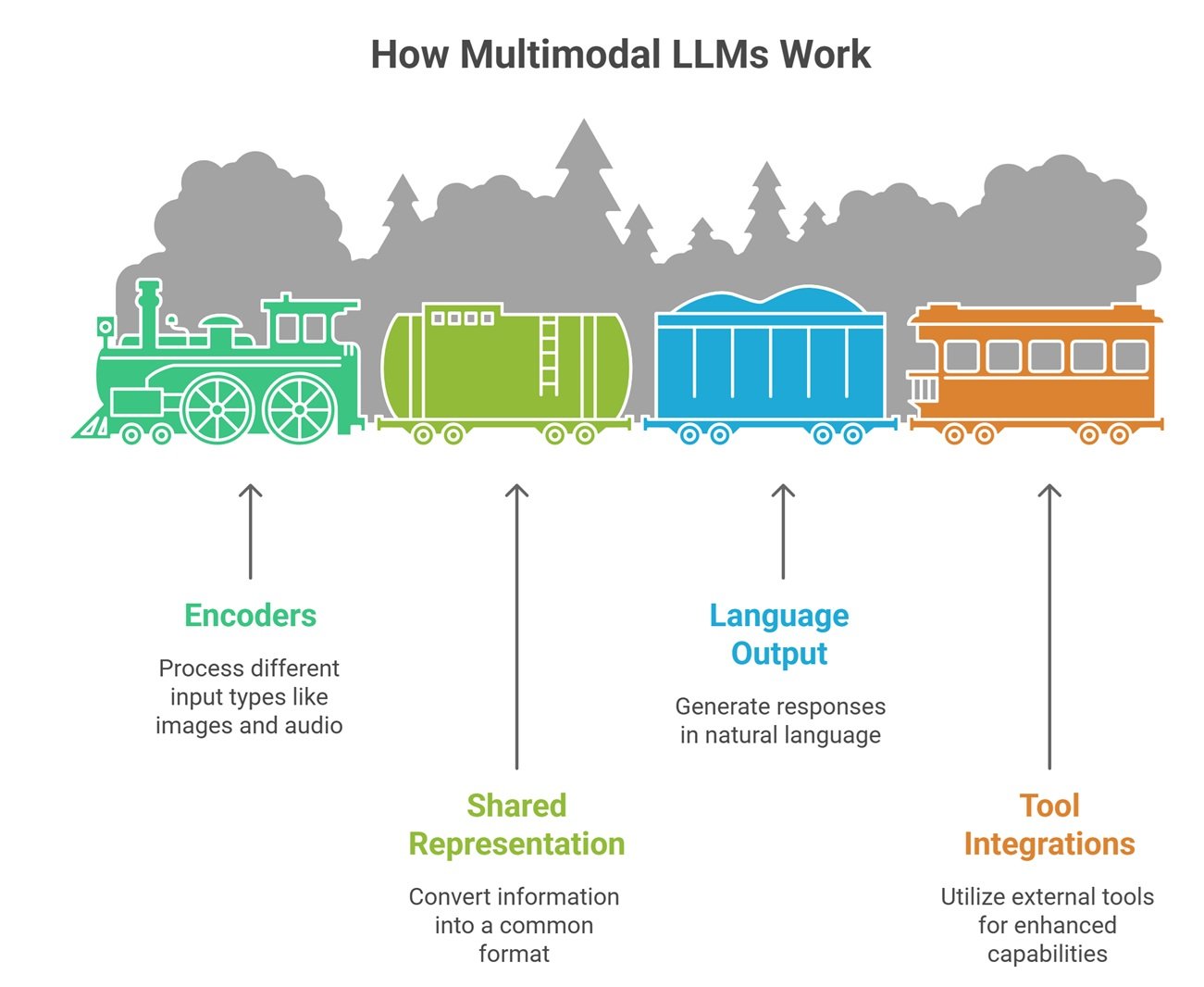
How Multimodal LLMs Work
While systems vary, common approaches include:
1. Encoders for Different Inputs
Separate components process images, audio, or video.
2. Shared Representation
Information is converted into formats the model can reason over.
3. Language Output Layer
The model responds in natural language.
4. Tool Integrations
Some systems call OCR, speech recognition, or search tools.
Popular multimodal AI ecosystems
Many leading providers offer multimodal capabilities through platforms such as:
Capabilities differ by model and product version.
Real-world Multimodal LLM use cases
1. Document Understanding
Upload PDFs, invoices, or scanned forms.
2. Image Analysis
Describe charts, screenshots, or products.
3. Customer Support
Analyze screenshots users send.
4. Healthcare Workflows
Interpret forms, reports, and notes.
5. Education
Explain diagrams or handwritten notes.
6. Ecommerce
Generate product descriptions from images.
7. Accessibility
Read images aloud or summarize visual content.
Why businesses are adopting them
Faster Workflows
One system handles multiple content types.
Better Automation
Less switching between separate tools.
Improved User Experience
Users can upload files, not just type prompts.
Richer Insights
Combine text + visuals + audio.
Competitive Advantage
More natural AI products.
Multimodal LLMs for consumers
You may already see this in tools that can:
- analyze photos
- summarize PDFs
- understand screenshots
- answer questions about charts
- transcribe voice notes
- describe images
This is multimodal AI in action.
Challenges and limitations
Accuracy Risk
Models may misread complex visuals.
Hallucinations
Incorrect interpretations can happen.
Privacy Concerns
Sensitive uploads need careful handling.
Cost
Multimodal processing may cost more.
Large Files
Heavy inputs can slow systems.
Multimodal LLMs: Common Misconceptions
Multimodal means perfect vision AI
No. Errors still happen.
It replaces all specialized tools
Not always. Dedicated OCR or vision tools may still help.
It only means image input
Audio, video, and documents can count too.
Text models are obsolete
Text-only models still matter for many tasks.
Multimodal LLM vs Computer Vision Tools
| Feature | Multimodal LLM | Traditional Vision Tool |
| Conversational Output | Strong | Limited |
| Broad Reasoning | Strong | Lower |
| Narrow Detection Tasks | Moderate | Often stronger |
| User Friendliness | High | Lower |
Many businesses combine both.
Future of multimodal AI
Expect rapid growth in:
- real-time voice assistants
- video reasoning tools
- autonomous workplace agents
- smarter robotics systems
- richer mobile assistants
- enterprise document intelligence
Multimodal systems may become the default AI experience.
Suggested Read:
- LLM for Beginners
- How LLMs Work
- Domain Specific Language Models
- LLM Deployment Basics
- Best LLMs for Writing
- Closed Source vs Open Source LLMs
FAQ: Multimodal LLMs
What are multimodal LLMs?
AI models that understand multiple data types like text, images, and audio.
Are multimodal LLMs better than text-only LLMs?
For mixed media tasks, often yes.
Can multimodal models analyze PDFs?
Yes, many can process document files.
Do they understand video?
Some systems support video analysis or frame-based reasoning.
Are multimodal models expensive?
They can cost more depending on usage.
Final takeaway
Multimodal LLMs expand AI beyond words. They help systems understand images, voice, files, and visual information in ways text-only models cannot.
As AI becomes more useful in daily work, multimodal capability is becoming essential.