
Multimodal AI vs Generative AI: What’s the Difference?
Multimodal AI and generative AI are related, but they are not the same thing. Multimodal AI is about understanding and connecting different data types such as text, images, audio, video, and documents. Generative AI is about creating new content such as text, images, code, audio, or video. Some systems can be both.
In Simple Terms
The easiest way to understand multimodal AI vs generative AI is this: multimodal AI focuses on input understanding, while generative AI focuses on output creation.
A multimodal AI system can look at an image, read a question, listen to audio, analyze a chart, or process a document together. Its main strength is connecting different types of information. A generative AI system creates something new, such as a blog draft, image, voiceover, code snippet, video clip, or summary. Its main strength is production.
The two ideas often overlap. For example, an AI assistant that accepts a screenshot and writes an explanation is both multimodal and generative. It uses multimodal AI to understand the screenshot and generative AI to produce the written answer.
What Is Multimodal AI?
Multimodal AI is artificial intelligence that can process more than one type of data. These data types are called modalities. Common modalities include text, images, audio, video, documents, charts, screenshots, and sensor data.
For example, a multimodal AI system may accept a product image and a written question, then explain what the image shows. It may analyze a medical scan together with patient notes. It may summarize a meeting using both audio and transcript data. IBM describes multimodal AI as machine learning models capable of processing and integrating information from multiple modalities such as text, images, audio, video, and sensory input.
What Is Generative AI?
Generative AI is artificial intelligence that creates new content in response to a prompt or request. It can generate text, images, videos, audio, code, synthetic data, designs, summaries, and other outputs.
For example, a generative AI tool can write an email, create an image from a text prompt, generate code, compose music, summarize a report, or produce a video storyboard. IBM defines generative AI as AI that can create original content such as text, images, video, audio, or software code in response to a user’s prompt.
The Core Difference: Multimodal AI vs Generative AI
The core difference is purpose. Multimodal AI is mainly about understanding different input formats. Generative AI is mainly about creating new output.
That distinction matters because many people use these terms interchangeably. A system can be generative without being multimodal. For example, a text-only writing assistant that creates blog drafts from typed prompts is generative, but not necessarily multimodal. A system can also be multimodal without being strongly generative. For example, a model that analyzes image plus text inputs and classifies them is multimodal, but its main job may not be content creation.
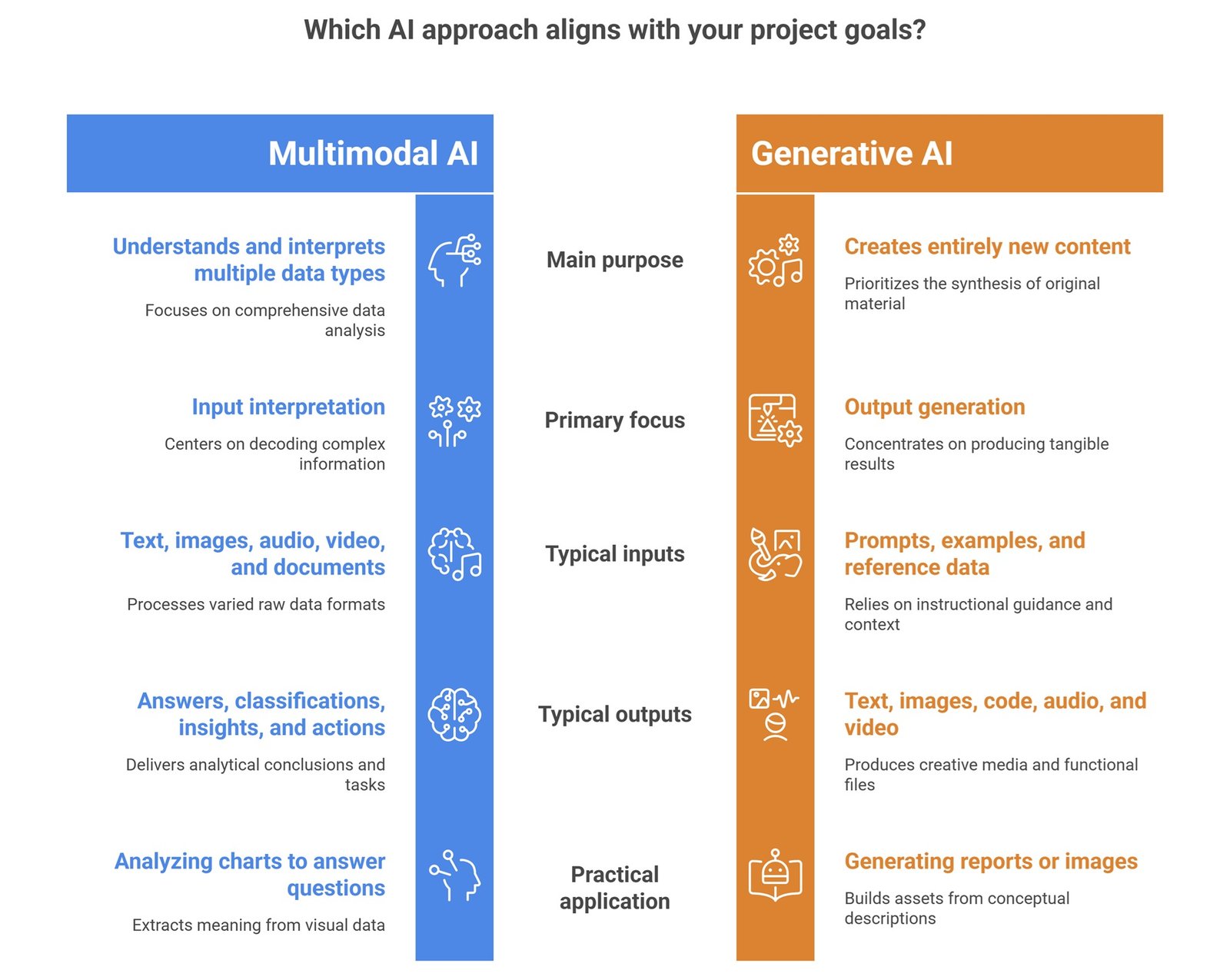
| Category | Multimodal AI | Generative AI |
| Main purpose | Understand multiple data types | Create new content |
| Main focus | Input interpretation | Output generation |
| Common inputs | Text, images, audio, video, documents | Prompts, examples, reference data |
| Common outputs | Answers, classifications, insights, actions | Text, images, code, audio, video |
| Example | Analyze a chart and answer a question | Generate a report or image |
| Overlap | Can generate after understanding inputs | Can accept multimodal prompts |
Multimodal AI vs Generative AI: Simple Example
Imagine you upload a photo of a damaged bicycle and ask, “What needs repair?”
The multimodal part is the system’s ability to inspect the image, understand the visual damage, and connect it with your written question. The generative part is the system’s ability to write a repair explanation, checklist, or recommendation.
This is why many modern AI assistants feel like both technologies at once. They can understand mixed inputs and generate useful outputs. The distinction is still useful because it helps you understand what the system is doing: first it interprets, then it creates.
Can Generative AI Be Multimodal?
Yes. Generative AI can be multimodal when it accepts or produces multiple types of data. For example, a system that accepts text and image inputs and generates a written answer is multimodal generative AI. A model that accepts a text prompt and generates an image is generative, and it may be considered multimodal if the system works across text and image modalities.
Modern multimodal large language models are a clear example of this overlap. NVIDIA describes multimodal large language models as deep learning algorithms that can understand and generate various forms of content across text, images, video, audio, and more.
Can Multimodal AI Exist Without Generative AI?
Yes. Multimodal AI does not always need to generate new content. It may classify, detect, match, score, retrieve, filter, or route information instead.
For example, a security system that analyzes video and audio to detect unusual activity is multimodal, but it may not generate creative content. A retail visual search engine that matches an uploaded product image with similar catalog items is multimodal, even if it does not generate new images. A medical workflow that compares scan data with structured records may be multimodal even if it only flags patterns for review.
What Is Multimodal Generative AI?
Multimodal generative AI combines both capabilities. It understands multiple input types and creates new output. This is the category many modern AI assistants and creative tools are moving toward.
Examples include:
- uploading an image and asking for a written explanation
- giving a text prompt and generating an image
- using audio plus transcript data to generate meeting notes
- using a product photo and customer message to generate a support reply
- analyzing a chart and generating a business summary
- using text, image, and video references to generate creative content
This overlap is becoming important because users increasingly expect AI systems to work across formats, not only typed prompts.
Business Use Cases: When Multimodal AI Matters More
Multimodal AI matters most when the problem requires understanding mixed information. Customer support is a strong example. A user may send a screenshot, typed complaint, voice note, and device photo. A text-only system may miss the real issue. A multimodal system can connect those inputs.
Healthcare, insurance, manufacturing, retail, robotics, education, and enterprise search also benefit from multimodal understanding. These workflows often involve documents, charts, images, voice, video, and sensor data. If the business problem starts with messy real-world inputs, multimodal AI is usually the more important capability.
Business Use Cases: When Generative AI Matters More
Generative AI matters most when the main goal is content creation or transformation. Marketing teams use generative AI to draft copy, create ad concepts, summarize research, generate email campaigns, or produce social media variations. Developers use it to generate code, test cases, documentation, and explanations.
Generative AI also helps with summarization, brainstorming, translation, training content, report drafting, and synthetic media creation. If the primary business goal is to produce something new from a prompt, generative AI is the core capability.
Where They Work Best Together: Multimodal AI vs Generative AI
The strongest modern AI workflows often combine multimodal AI and generative AI. A customer support assistant can understand screenshots and chat history, then generate a helpful reply. A business intelligence assistant can analyze dashboards and generate executive summaries. A learning assistant can inspect diagrams and generate simple explanations.
This combination is powerful because it mirrors real work. People do not only ask typed questions. They share files, images, recordings, screenshots, charts, and videos. AI systems that understand those inputs and generate useful outputs are more practical than systems that do only one of those jobs.
Multimodal AI vs Generative AI for Search
In search, multimodal AI helps users query with more than words. A user can search with an image, screenshot, voice command, or video frame. The system can understand the input and retrieve relevant information. This is useful for visual search, product discovery, document search, and enterprise knowledge retrieval.
Generative AI adds the ability to summarize results, explain findings, or produce an answer from retrieved context. For example, a multimodal search system may identify a product from an uploaded photo, while generative AI writes a comparison summary. Together, they improve both discovery and explanation.
Multimodal AI vs Generative AI for Content Creation
For content creation, generative AI is usually the main engine because it creates the output. It can write scripts, generate images, produce audio, draft videos, or create designs. Multimodal AI becomes important when the creative process uses mixed inputs, such as reference images, voice instructions, brand documents, video clips, and sketches.
For example, a designer may upload a mood board and ask the system to generate visual directions. The multimodal part understands the mood board. The generative part creates new copy, layouts, or visuals. This is why many creative AI tools are becoming multimodal generative systems rather than only text-to-image or text-to-text tools.
Risks and Limitations
Both technologies have risks. Multimodal AI can misread images, misunderstand audio, overlook visual details, or connect inputs incorrectly. It may interpret a blurry screenshot or complex chart incorrectly. Generative AI can hallucinate, fabricate details, produce biased content, or generate low-quality outputs that sound confident.
When the two are combined, the risks can stack. A system may misunderstand an image and then generate a convincing but wrong explanation. Businesses should use evaluation, human review, access controls, and clear limitations, especially in healthcare, finance, legal, education, and safety-critical workflows.
Which One Should You Learn First?
For beginners, start with generative AI if your goal is writing, content creation, coding help, summarization, or creative workflows. Start with multimodal AI if your goal is image understanding, document AI, computer vision, audio/video workflows, robotics, accessibility, or enterprise systems that process mixed data.
For AI builders, both are becoming important. Modern applications increasingly require multimodal input understanding and generative output. A practical learning path is: understand generative AI basics first, then learn multimodal AI, vision-language models, embeddings, multimodal RAG, and evaluation.
Suggested Read:
- What Is Multimodal AI? Complete Beginner’s Guide to AI Beyond Text
- Multimodal AI Explained Simply
- How Multimodal AI Works
- Multimodal AI Use Cases
- Multimodal AI Examples
- Best Multimodal AI Tools in 2026
- What Is a Large Language Model? Explained Simply
FAQ: Multimodal AI vs Generative AI
What is the difference between multimodal AI and generative AI?
Multimodal AI processes and connects multiple data types, while generative AI creates new content such as text, images, audio, video, or code.
Is multimodal AI the same as generative AI?
No. They overlap, but they are not the same. Multimodal AI is about multiple input types. Generative AI is about creating output.
Can generative AI be multimodal?
Yes. A generative AI system can be multimodal if it accepts or produces multiple modalities, such as text, images, audio, or video.
What is multimodal generative AI?
Multimodal generative AI is AI that understands multiple input types and generates new content. For example, it may analyze an image and generate a written explanation.
Which is better: multimodal AI or generative AI?
Neither is universally better. Multimodal AI is better for mixed-input understanding, while generative AI is better for content creation. Many modern systems combine both.
What are examples of multimodal AI vs generative AI?
A visual search tool is an example of multimodal AI. A text generator is an example of generative AI. An assistant that analyzes an image and writes an explanation is both.
Final Takeaway
Multimodal AI vs generative AI is easier to understand when you separate input from output. Multimodal AI helps systems understand multiple kinds of information. Generative AI helps systems create new content.
The future of AI will increasingly combine both. The most useful systems will understand text, images, audio, video, documents, and charts, then generate helpful answers, summaries, recommendations, designs, or actions. To continue learning, read What Is Multimodal AI, How Multimodal AI Works, and Multimodal AI Use Cases next.