
LLM Training vs Inference: Key Differences Explained Simply
Large Language Models (LLMs) like modern AI assistants go through two major phases: training and inference. Many beginners hear these terms but are not sure what they actually mean.
Understanding this difference helps you see how AI models are built, why they cost so much to create, and how they generate answers in real time.
This guide explains LLM training vs inference in simple language.
In simple terms
Training
Training is when the AI model learns patterns from huge amounts of text data.
Inference
Inference is when the trained model uses what it learned to answer your prompts.
Think of it like this:
- Training = studying for years
- Inference = taking the exam instantly
Why This Difference Matters
Training and inference require different resources, costs, and goals.
Understanding both helps businesses decide:
- whether to build or use existing models
- how AI costs work
- why responses may be slow or expensive
- where optimization matters most
What is LLM Training?
LLM training is the process of teaching a model using enormous datasets such as:
- books
- websites
- research text
- code repositories
- conversations
- documentation
During training, the model learns:
- grammar
- facts and concepts
- reasoning patterns
- writing styles
- relationships between words
This phase uses powerful hardware and large budgets.
What happens during training?
1. Data Collection
Massive text datasets are gathered and cleaned.
2. Tokenization
Text is broken into tokens.
3. Model Learning
The neural network predicts missing or next tokens repeatedly.
4. Error Correction
Weights are adjusted millions of times.
5. Fine-Tuning
Specialized improvements may be added later.
Training can take weeks or months.
What is LLM Inference?
Inference happens after training is complete.
This is the stage when users interact with the model.
Examples:
- asking a chatbot a question
- requesting code generation
- summarizing a document
- translating text
- generating marketing copy
The model uses learned patterns to create responses in seconds.
What happens during Inference?
1. User enters prompt
Example:
“Explain blockchain simply.”
2. Prompt is tokenized
The text becomes tokens.
3. Model predicts output
It generates the most likely next tokens.
4. Response appears
You receive a natural-language answer.
This process is much faster than training.
LLM Training vs Inference: Main differences
| Feature | Training | Inference |
| Goal | Teach model | Use model |
| Timing | Before release | After deployment |
| Cost | Very high | Ongoing per use |
| Speed | Slow | Fast |
| Compute Need | Massive | Moderate to high |
| Data Need | Huge datasets | User prompts |
| Example | Building model | Chat response |
Which is more expensive?
Training
Usually extremely expensive because it needs:
- large GPU clusters
- huge datasets
- weeks of compute
- research teams
Inference
Costs less per interaction but can become expensive at scale when millions of users query the model daily.
Both matter financially.
Why Inference Optimization Matters
Many businesses do not train their own LLMs. They use existing models through APIs or platforms.
That means inference cost becomes more important.
Companies optimize inference by:
- shorter prompts
- caching responses
- choosing smaller models
- batching requests
- limiting unnecessary outputs
Can businesses train their own LLM?
Yes, but often unnecessary.
Most companies instead choose:
- APIs from OpenAI
- models from Anthropic
- tools from Google
- open models from Meta
- open-source ecosystems from Mistral AI
This avoids training costs.
Fine-Tuning vs LLM Training vs Inference
LLM Training
Build base model from scratch.
Fine-tuning
Adapt a trained model for specific tasks.
Inference
Use the model to generate outputs.
Fine-tuning sits between training and inference.
Real-world example
A company launches an AI support bot.
Training phase
Uses an existing pre-trained LLM.
Fine-tuning phase
Adjusts tone and support behavior.
Inference phase
Customers ask questions daily.
Most companies mainly pay for inference.
Why responses can feel slow
Inference speed depends on:
- model size
- server load
- token length
- reasoning depth
- hardware quality
Larger models may answer more slowly.
Future trend: Cheaper training, Faster inference
The industry is improving both areas through:
- better chips
- efficient architectures
- smaller strong models
- quantization
- optimized serving systems
This lowers costs over time.
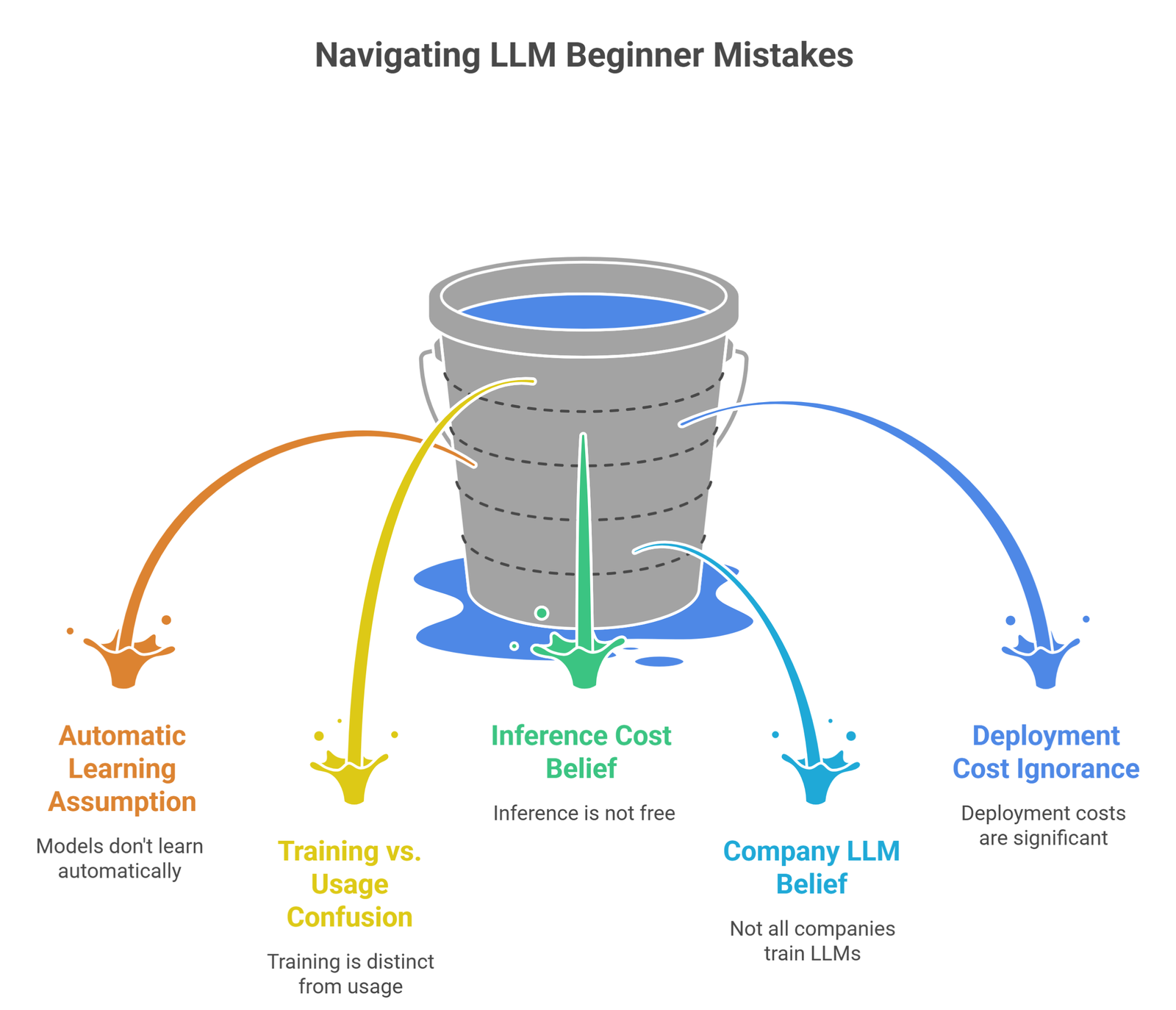
Common Beginner Mistakes
- assuming models learn from every chat automatically
- confusing training with daily usage
- thinking inference is free
- believing every company trains its own LLM
- ignoring deployment costs
Suggested Read:
FAQ: LLM Training vs Inference
What is training in LLMs?
Training is teaching the model using huge text datasets.
What is inference in LLMs?
Inference is generating responses after training.
Which costs more?
Training usually costs more upfront. Inference can cost more long term at scale.
Do chat prompts retrain the model instantly?
Usually no.
Should companies train their own model?
Most businesses use existing models instead.
Final takeaway
LLM training vs inference is simple once separated: training builds intelligence, inference delivers it to users.
Training is expensive and rare. Inference happens every time someone uses AI. For most businesses, understanding inference costs and performance matters the most.