LLM Inference Explained: What It Means and How AI Generates Answers
Large Language Models (LLMs) can answer questions, write content, summarize documents, and generate code in seconds. But what actually happens after you type a prompt?
The answer is called inference.
Inference is one of the most important concepts in modern AI because it is the stage users experience directly every day.
This guide explains LLM inference in simple language for beginners, builders, and business teams.
In simple terms
LLM inference is:
The process where a trained AI model uses what it learned to generate an output from your prompt.
Example:
You type:
“Write a professional email requesting a meeting.”
The model reads your prompt and produces a response.
That live response generation is inference.
Why Inference Matters
Inference is the part of AI users interact with most.
It affects:
- response speed
- answer quality
- user experience
- API costs
- scalability
- business ROI
Even a powerful model feels weak if inference is slow or expensive.
Training vs Inference (simple difference)
Training
The model learns from huge datasets.
Inference
The trained model uses that learning to answer prompts.
Think of it like:
- Training = studying for years
- Inference = answering the question now
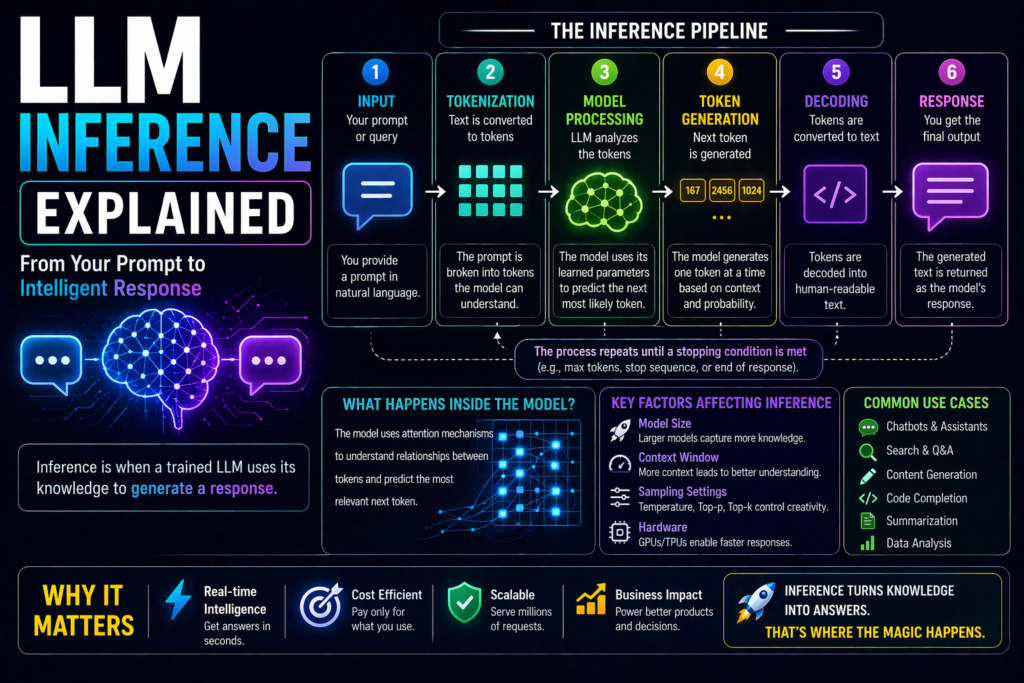
How LLM inference Explained Works Step by Step
1. User enters a prompt
Example:
“Explain cloud computing simply.”
2. Prompt becomes tokens
The text is split into tokens (small text units).
3. Model processes context
The AI analyzes:
- your words
- prior chat history
- instructions
- relevant context
4. Next-token prediction begins
The model predicts the most likely next token.
5. Tokens build a response
One token at a time, very quickly.
6. Final answer appears
You receive a complete response.
This entire pipeline is inference.
What are tokens during inference?
Tokens may be:
- full words
- parts of words
- punctuation
- numbers
Example:
A short prompt and a long answer both consume tokens.
That is why token usage matters for speed and cost.
Why some responses are fast and others slow
Inference speed depends on several factors.
Model Size
Larger models may take longer.
Prompt Length
Long prompts require more processing.
Output Length
Longer answers take more time.
Server Load
Busy systems may slow responses.
Reasoning Complexity
Harder tasks can increase latency.
Real examples of LLM inference
Chatbots
User asks a question, AI responds instantly.
Coding Assistants
Developer asks for code, model generates functions.
Support Bots
Customer asks for refund policy, system replies.
Summarizers
Upload report, receive concise summary.
AI Search
Ask a question, get conversational answer.
Why businesses care about inference costs
Many AI products pay per usage or per token.
That means inference cost increases with:
- more users
- longer prompts
- larger outputs
- premium models
- heavy daily usage
This is why optimization matters.
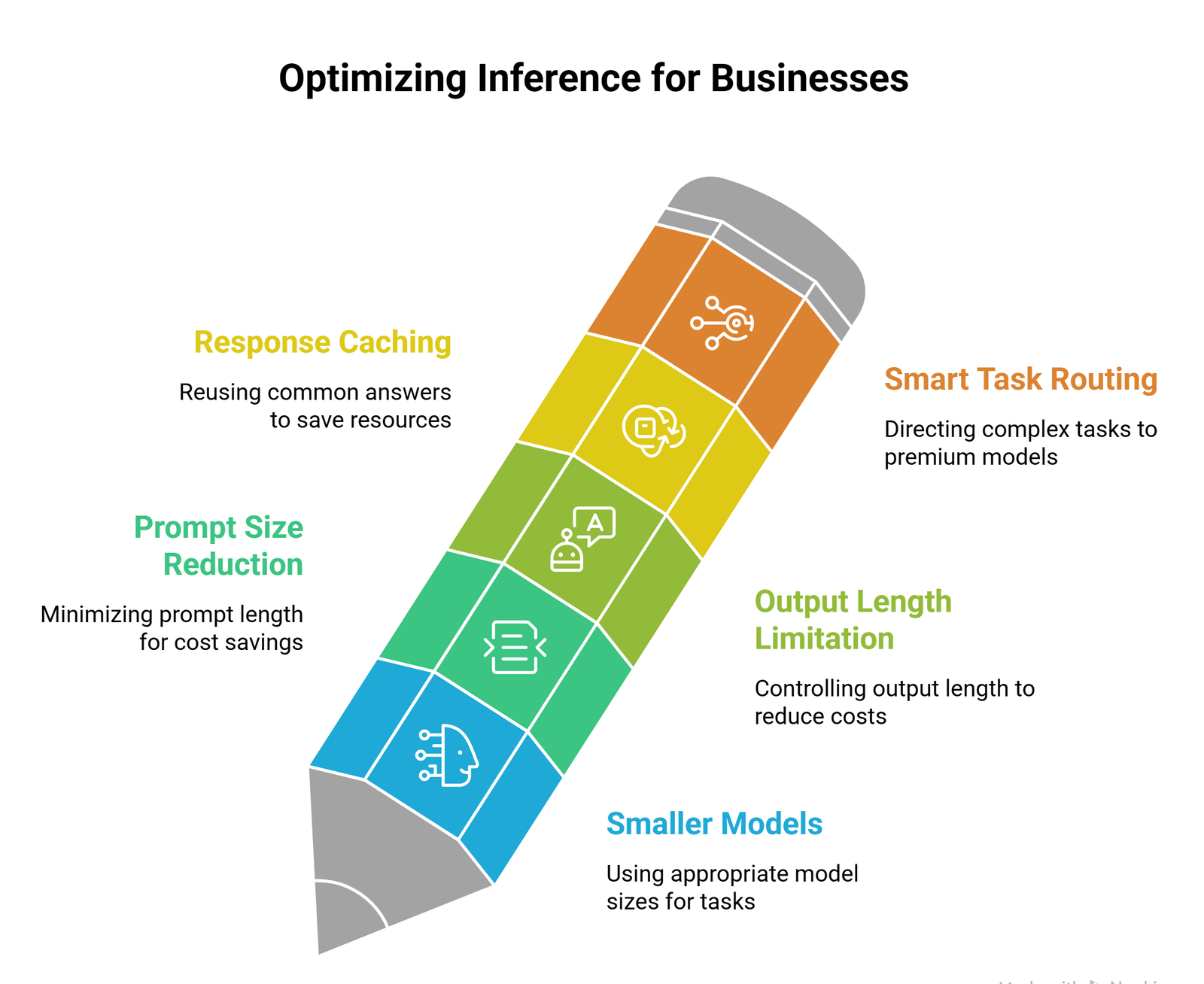
How businesses optimize inference explained
1. Use smaller models when possible
Not every task needs the largest model.
2. Reduce prompt size
Cleaner prompts save tokens.
3. Limit output length
Shorter outputs can reduce cost.
4. Cache repeated responses
Reuse common answers.
5. Route tasks smartly
Use premium models only for complex work.
Which companies provide inference platforms?
Many AI ecosystems support inference services, including:
Developers use APIs, cloud platforms, or self-hosted deployments.
Inference on cloud vs device
| Type | Benefits | Challenges |
| Cloud Inference | Powerful models, scalable | Ongoing cost, latency |
| On-Device Inference | Privacy, speed, offline use | Smaller model limits |
Both approaches are growing.
Common beginner misconceptions
The model learns from every prompt instantly
Usually no. Most prompts trigger inference, not retraining.
Faster always means smarter
Not necessarily.
Bigger models are always required
Many tasks work well with efficient models.
Inference is free after training
No. Running models still costs compute.
Future of inference
Expect rapid progress in:
- faster chips
- cheaper serving costs
- edge AI devices
- smarter routing systems
- low-latency voice assistants
- multi-model orchestration
Inference quality and cost are becoming major competitive advantages.
Suggested Read:
- LLM for Beginners
- LLM Training vs Inference
- How LLMs Work
- LLM Token Limits
- LLM Context Window Explained
- How AI Agents Work Explained
FAQ:LLM Inference Explained
What is LLM inference?
It is the process of generating outputs from prompts using a trained model.
Is inference the same as training?
No. Training teaches the model. Inference uses the model.
Why does inference cost money?
It requires computing resources every time the model runs.
Can inference happen offline?
Yes, with compatible smaller models on devices.
Why are some AI replies slow?
Model size, prompt length, server load, and complexity all matter.
Final takeaway
LLM inference is the live engine behind modern AI tools. Every time you ask a chatbot, summarize a report, or generate code, inference is happening.
Understanding inference helps you use AI more efficiently, reduce costs, and choose the right tools for real-world tasks.