
GPT-5.5 Instant Is Better at Health Questions—but It Is Not a Doctor
OpenAI published a new assessment of GPT-5.5 health intelligence on June 18, 2026, describing improvements in how ChatGPT handles health and wellness questions.
The company says GPT-5.5 Instant is more likely to notice warning signs, request important missing information, communicate uncertainty, and explain complex medical topics clearly. OpenAI also reports stronger results on its HealthBench evaluations and in a physician-led comparison involving 3,500 reviewed responses.
Those findings are important because OpenAI says more than 230 million people use ChatGPT for health and wellness questions each week. They do not, however, turn ChatGPT into a clinician. The model cannot perform an examination, order tests, verify every detail of a patient’s history, or accept responsibility for a medical decision.
What Changed in GPT-5.5 Health Intelligence?
OpenAI highlights four practical improvements in GPT-5.5 Instant:
- Better recognition of situations that may require urgent care
- More appropriate requests for missing context
- Clearer explanations of uncertainty
- More understandable guidance about possible next steps
These changes matter because health questions are rarely simple fact-retrieval tasks.
A useful response may need to distinguish common symptoms from warning signs, explain several plausible causes without pretending to know which one is correct, and tell the user when online information is no longer enough.
OpenAI says physicians helped define these desired behaviors by reviewing model answers, identifying failure modes, and describing what a strong response should include. Its wider health-evaluation network includes more than 260 physicians across 60 countries, 49 languages, and 26 specialties.
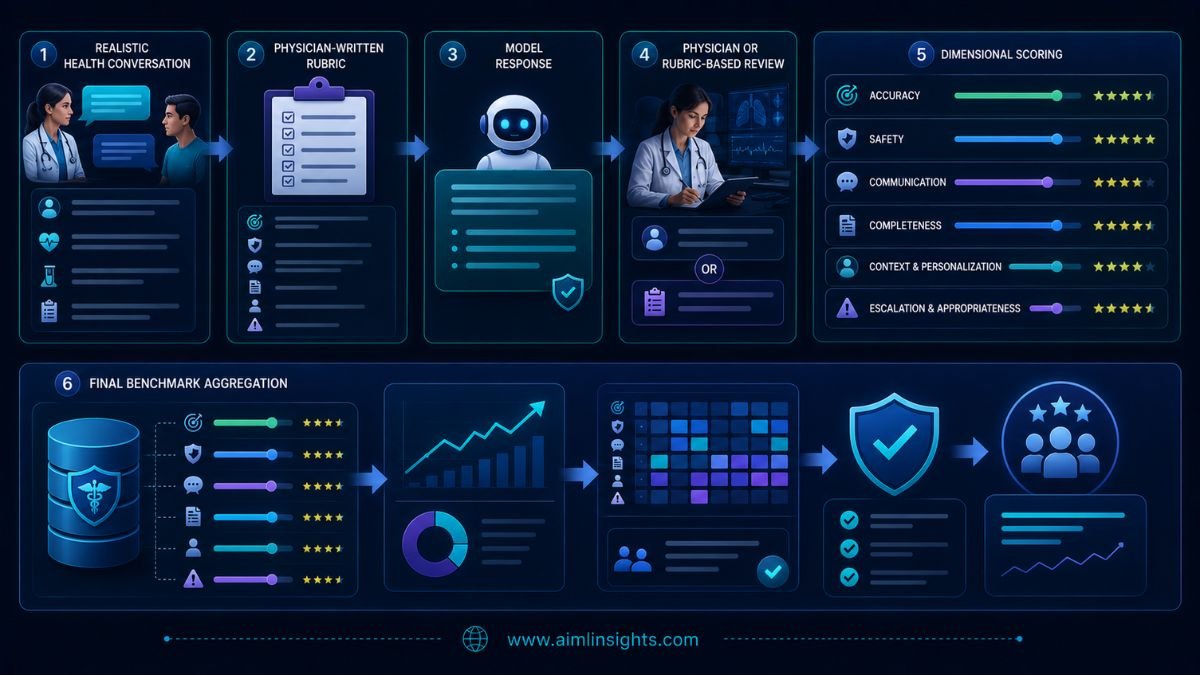
How HealthBench Measures Medical Answers
HealthBench is not a conventional medical multiple-choice exam.
It contains 5,000 realistic health conversations, each scored against a custom rubric written with physician input. The scenarios include multi-turn and multilingual interactions involving both ordinary users and healthcare professionals.
The rubrics assess qualities such as:
- Medical accuracy
- Safety
- Completeness
- Communication quality
- Awareness of context
- Appropriate escalation to care
HealthBench Professional focuses on tasks clinicians may bring to ChatGPT. It covers care consultation, writing and documentation, and medical research. OpenAI says roughly one-third of its examples were intentionally adversarial, while the dataset was filtered toward cases the models found difficult.
This makes the benchmarks more realistic than a basic medical exam, but they still evaluate written responses—not patient outcomes.
GPT-5.5 Instant HealthBench Results
OpenAI’s system card reports length-adjusted scores because longer answers have more opportunities to satisfy rubric criteria. The company applies penalties to responses above 2,000 characters and gives corresponding adjustments to shorter answers. It also notes that the current implementation differs from earlier versions, so previously published scores may not be directly comparable.
| Evaluation | GPT-5.3 Instant | GPT-5.5 Instant | Reported improvement | Evaluation owner | Independent verification |
| HealthBench | 49.6 | 51.4 | +1.8 points | OpenAI | No independent replication cited |
| HealthBench Hard | 20.2 | 22.9 | +2.7 points | OpenAI | No independent replication cited |
| HealthBench Consensus | 94.6 | 94.7 | Effectively flat | OpenAI | No independent replication cited |
| HealthBench Professional | 32.9 | 38.4 | +5.5 points | OpenAI | No independent replication cited |
The strongest reported gain appears on HealthBench Professional.
However, an increase from 32.9 to 38.4 does not mean the model correctly completed 38.4% of medical cases. It is a rubric-based aggregate score shaped by multiple qualities and adjusted for response length.
What the Physician-Led Comparison Shows
OpenAI also asked physicians to write responses to representative health conversations. They received unlimited time and internet access but could not use AI.
A separate physician panel then compared those answers with responses from several model generations across accuracy, communication, completeness, instruction following, and health-decision helpfulness. The evaluation covered 3,500 reviewed responses.
OpenAI reports that GPT-5.5 Instant responses were rated higher than both the physician-written answers and older model responses across the evaluated criteria.
The company also says evaluators found fewer failures involving:
- Missing red flags or referrals
- Failing to request necessary context
- Ignoring local healthcare conditions
- Communicating in an unclear or incomplete way
This should not be interpreted as “GPT-5.5 is a better doctor.”
The comparison measured written answers to selected conversations. Physicians in real practice can ask follow-up questions, examine patients, interpret tests, access records, update a differential diagnosis, and remain responsible for care.
The evaluation therefore supports a narrower conclusion: GPT-5.5 produced highly rated written health responses under OpenAI’s study design.
Better Uncertainty Handling Matters
Medical questions often contain incomplete information.
A poor AI answer may confidently choose one diagnosis. A better answer may explain several possibilities, identify the missing facts that would distinguish them, and state which symptoms require urgent assessment.
OpenAI says GPT-5.5 improved at explaining uncertainty without overstating confidence. It also became better at suggesting what users should ask a clinician next.
That is useful for appointment preparation, understanding terminology, and organizing questions.
It remains unsafe to treat polished uncertainty language as proof that the model considered every relevant diagnosis. A response can sound careful while still omitting an important possibility.
Production Monitoring Adds Another Signal
OpenAI reports using privacy-preserving monitors to identify possible factuality problems in health-related production traffic.
Across billions of weekly health messages, the company says the proportion of responses containing at least one flagged factuality issue fell by 71% over two months.
This is not the same as a clinically adjudicated error rate.
The company has not disclosed enough detail to calculate how often users received harmful advice, how monitors were validated across conditions and languages, or whether the message mix remained constant.
The system card separately reports that GPT-5.5 Instant produced 52.5% fewer hallucinated claims than GPT-5.3 Instant on selected high-stakes prompts involving medicine, law, and finance. Those prompts were deliberately difficult and are not representative of average production use.
Why This Matters
Better health communication could help users:
- Understand unfamiliar medical terms
- Prepare questions before an appointment
- Summarize information for discussion with a clinician
- Recognize that a symptom may require prompt attention
- Compare general treatment considerations
- Navigate insurance or healthcare processes
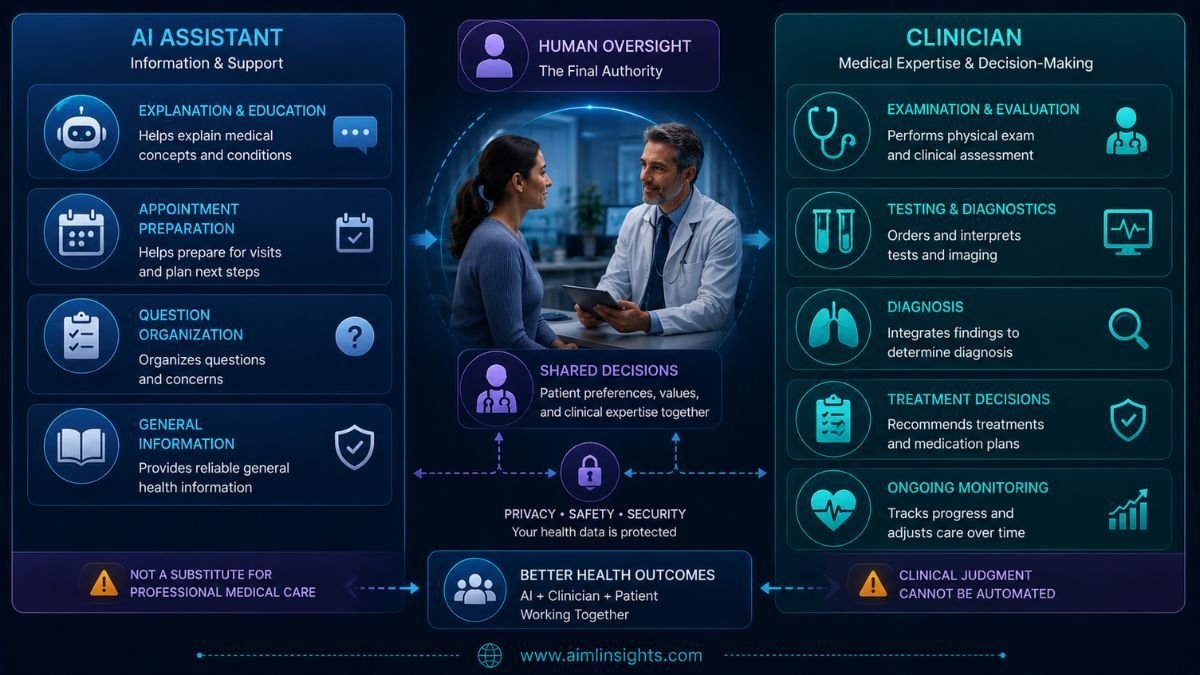
Clinicians may also benefit from drafting, documentation, research synthesis, and patient-education support.
The value is strongest when the model helps a person prepare for or communicate with healthcare professionals—not when it becomes the final authority.
What GPT-5.5 Still Cannot Do
GPT-5.5 cannot reliably replace:
- A physical examination
- Vital-sign measurement
- Laboratory or imaging interpretation in full clinical context
- Medication reconciliation
- Continuous monitoring
- Diagnosis based on a complete longitudinal record
- Emergency assessment
- A licensed professional’s accountability
It can also hallucinate, misunderstand the question, rely on outdated information, overlook rare conditions, or give advice that is inappropriate for a user’s location or medical history.
Personalization may improve relevance, but connected files or past chats can also contain incomplete, old, or incorrect information.
Benchmark Audit and Missing Evidence
| Question | Published evidence |
| Did benchmark performance improve? | Yes, according to OpenAI |
| Were physicians involved? | Yes, in rubric creation and response review |
| Were results independently replicated? | Not disclosed |
| Were patient outcomes measured? | No |
| Was diagnostic accuracy measured in clinical practice? | No |
| Were emergency delays or adverse events measured? | No |
| Was performance reported by language and specialty? | Not in the headline results |
| Was ChatGPT compared with clinicians using full clinical tools? | No |
| Does the evaluation justify autonomous care? | No |
The biggest evidence gap is the distance between a well-rated written answer and a safe real-world medical decision.
Simple Explanation for Beginners
GPT-5.5 appears better at explaining health information, noticing warning signs, and saying when it needs more information.
That makes it a potentially better assistant for understanding a health question.
It does not make ChatGPT a doctor.
A doctor can examine you, order tests, review your full history, change the plan when new evidence appears, and take responsibility for your care.
Conclusion: GPT-5.5 Health Intelligence
GPT-5.5 health intelligence represents a meaningful reported improvement in ChatGPT’s ability to communicate about health.
OpenAI’s evaluations suggest better performance on difficult health conversations, stronger professional-task scores, fewer missed red flags, and more useful handling of uncertainty.
But every major performance result is company-reported, and none proves that ChatGPT can safely replace clinicians.
The responsible role for GPT-5.5 is decision support, education, and appointment preparation—with professional medical care remaining essential for diagnosis and treatment.
Final Takeaways
- OpenAI published the health-intelligence update on June 18, 2026.
- GPT-5.5 Instant reportedly improved red-flag recognition and uncertainty handling.
- HealthBench uses realistic conversations and physician-written rubrics.
- GPT-5.5 gained 1.8 points on HealthBench and 5.5 on HealthBench Professional.
- HealthBench Consensus remained effectively flat.
- Physicians rated GPT-5.5 answers highly in an internal 3,500-response comparison.
- The comparison evaluated written answers, not full clinical practice.
- OpenAI reports a 71% decline in monitored responses with flagged factuality issues.
- All major findings are company-reported.
- ChatGPT should support—not replace—qualified medical professionals.
Suggested Read:
- ChatGPT Health Explained
- AI in Healthcare Explained
- OpenAI GPT-5.5 Guide
- AI Agents Can Now Work for Hours
- China’s Cheap AI Model Is Making Claude Look Expensive
FAQ: GPT-5.5 Health Intelligence
What changed in GPT-5.5 health intelligence?
OpenAI says GPT-5.5 Instant is better at recognizing urgent situations, requesting missing information, communicating uncertainty, and explaining complex health topics.
How did GPT-5.5 perform on HealthBench?
Its length-adjusted HealthBench score increased from 49.6 for GPT-5.3 Instant to 51.4. HealthBench Professional increased from 32.9 to 38.4.
Did physicians rate GPT-5.5 above doctors?
In an OpenAI-run comparison of written responses, physician reviewers rated GPT-5.5 Instant higher across the evaluated criteria. This did not compare the model with doctors performing complete clinical care.
Can GPT-5.5 diagnose medical conditions?
It can discuss possible explanations and help organize questions, but it cannot perform a complete clinical assessment or independently establish a safe diagnosis.
Is ChatGPT safe for health questions?
It may be useful for general information and preparation, but it can still be wrong or incomplete. Urgent, severe, persistent, or medication-related concerns require qualified medical care.
What are the limitations of HealthBench?
HealthBench evaluates generated responses using physician-created rubrics. It does not directly measure treatment outcomes, missed diagnoses in real practice, or harm caused by relying on a model.
References: