Multimodal RAG Explained: Images, Text, Video
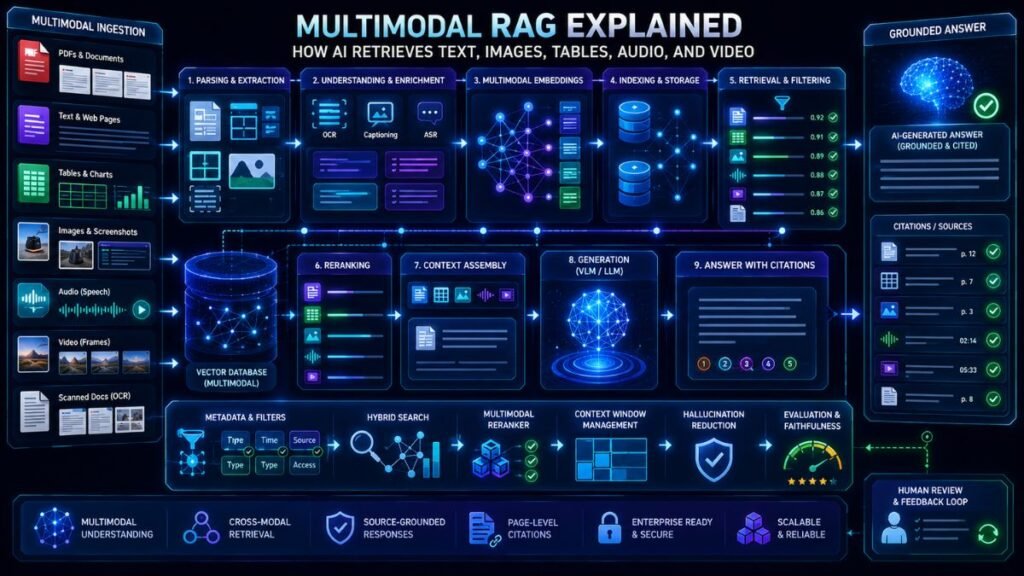
Multimodal RAG explained simply: it is retrieval-augmented generation that can search and use more than text. Instead of retrieving only written passages, multimodal RAG can retrieve images, tables, charts, screenshots, PDFs, audio, video frames, or document pages before generating a more grounded answer. In Simple Terms Traditional RAG gives an AI model relevant text before […]
Multimodal RAG Explained: Images, Text, Video Read More »