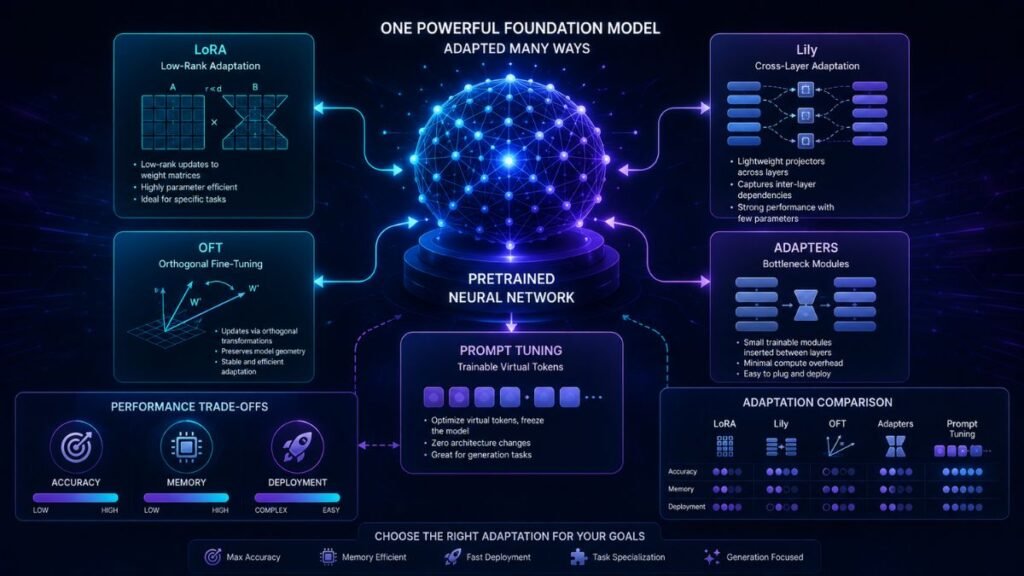
LoRA Is the Most Popular Fine-Tuning Method—but Not Always the Best
Hugging Face published a new parameter-efficient fine-tuning comparison on June 18, 2026, challenging the assumption that LoRA should be the automatic choice for every model-adaptation task.
LoRA remains overwhelmingly dominant. In Hugging Face’s sample of 20,834 model cards mentioning one PEFT technique, 98.4% referenced LoRA. A separate GitHub-code sample also found LoRA in 71.3% of matching results. That popularity reflects strong tooling, broad tutorials, easy deployment, and reliable performance—not proof that LoRA always produces the highest accuracy or lowest memory usage.
The new LoRA alternatives PEFT comparison found that Lily, OFT, memory-optimized LoRA variants, and other methods can outperform standard LoRA on one or more metrics. The result is not a universal ranking. It is evidence that PEFT selection should depend on the task, hardware, deployment stack, and acceptable inference overhead.
What Is Parameter-Efficient Fine-Tuning?
Parameter-efficient fine-tuning adapts a pretrained model without updating every original weight.
Full fine-tuning requires storing gradients and optimizer states for a large share of the model, which can demand substantial GPU memory. PEFT methods freeze most base-model parameters and train a smaller set of added or selected values.
This can reduce:
- Training-memory requirements
- Checkpoint size
- Storage per customized model
- Cost of maintaining multiple task-specific variants
Hugging Face’s PEFT library currently exposes more than 40 distinct methods or method families through a broadly unified interface, including LoRA, OFT, Lily, IA3, prompt tuning, prefix tuning, FourierFT, VeRA, and several adapter variants.
How LoRA Works
LoRA, or Low-Rank Adaptation, freezes an existing weight matrix and learns a smaller low-rank update.
Instead of changing a large matrix directly, LoRA represents the update through two smaller matrices. This reduces the number of trainable parameters and creates compact adapter checkpoints.
LoRA has several practical advantages:
- Mature support across Transformers and Diffusers
- Compatibility with many quantized training workflows
- Small task-specific files
- Ability to merge adapters into base weights in some setups
- Support in serving systems such as vLLM
- Large numbers of examples and community tools
These operational benefits explain why LoRA remains the default even when another method may show a modest benchmark advantage.
Standard LoRA vs Optimized LoRA
One of the most important findings is that “LoRA” is not a single fixed configuration.
The math benchmark showed a major gap between ordinary LoRA and optimized variants.
Standard LoRA achieved 48.1% test accuracy with 22.5GB peak VRAM. Rank-stabilized LoRA, often called rsLoRA, reached 53.2% with 22.6GB, almost the same memory footprint. LoRA-FA used a specialized optimization approach that freezes one part of the low-rank adapter and reached the more memory-efficient end of the comparison.
This means teams may be leaving performance unused even before considering a completely different PEFT family.
A more useful first experiment may be:
- Standard LoRA
- rsLoRA
- LoRA-FA
- One or two non-LoRA alternatives
That provides a stronger baseline than comparing every new paper only against untuned vanilla LoRA.
How Lily Differs From LoRA
Lily stands for Low-Rank Interconnected Adaptation Across Layers.
Normal LoRA learns separate low-rank projections for individual adapted layers. Lily introduces shared high-dimensional projector experts that can interact with lower-dimensional projectors across multiple layers.
The goal is to reduce the rigidity of a fixed low-rank update and allow information to flow more broadly across the network. The original Lily paper argues that these cross-layer connections improve representational flexibility.
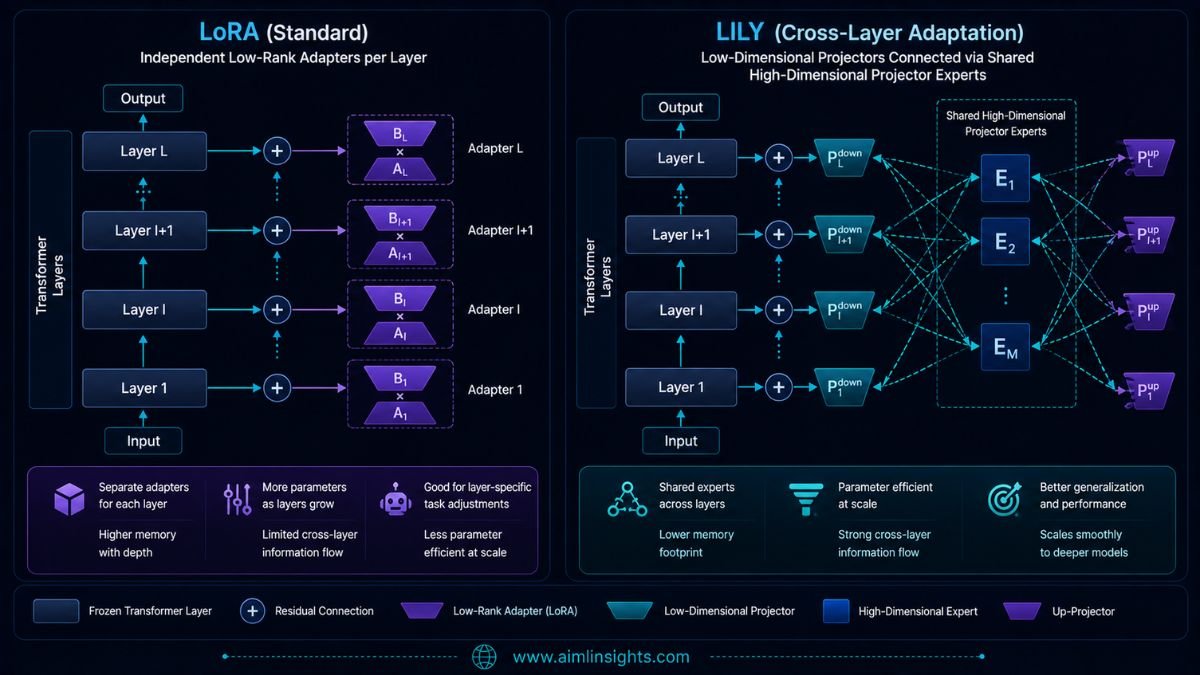
In Hugging Face’s language-model benchmark, Lily reached 54.9% accuracy, exceeding rank-stabilized LoRA’s 53.2%. However, Lily required 25.6GB peak VRAM, compared with 22.6GB for rsLoRA.
Lily therefore won on test performance but not on memory efficiency.
That is exactly why a single “best PEFT method” label is misleading.
What OFT Changes
Orthogonal Fine-Tuning, or OFT, updates a model through constrained orthogonal transformations rather than low-rank additive matrices.
The method is designed to preserve more of the pretrained model’s geometric structure while learning the new task.
In Hugging Face’s image-generation benchmark using FLUX.2-klein-base-4B, standard LoRA achieved a DINO similarity score of 0.697 and required 9.97GB of memory. OFT reached 0.708 while using 9.01GB. Under those two metrics, OFT strictly dominated LoRA: it scored higher and used less peak memory.
That does not establish OFT as universally superior.
The result applies to one image-concept learning task, one base model, chosen hyperparameters, and one evaluation metric. OFT may also have different layer compatibility, quantization support, merging behavior, and serving requirements.
Adapters, Prompt Tuning, and Other PEFT Methods
Traditional adapters
Adapter methods insert small neural-network modules between or alongside existing transformer layers.
They can be expressive because they add nonlinear transformations, but the additional modules remain active during inference. This can create latency overhead unless the implementation supports merging or efficient fused execution.
Adapters are often useful when:
- Multiple tasks share one base model
- Task switching matters
- Slight inference overhead is acceptable
- Strong task specialization is required
Prompt tuning
Prompt tuning learns trainable virtual prompt tokens while keeping the base model frozen.
Its trainable-parameter count can be extremely small, but quality is task- and model-size-dependent. It also consumes part of the context window and cannot always be merged away.
Prompt tuning is attractive when:
- Storage must be minimal
- Many small task variants are needed
- The base model already understands the task format
- Deployment supports virtual-token injection
Hugging Face recently added improved prompt-tuning initialization after its comparison suite showed that initialization choice can materially affect performance.
Other low-parameter methods
Methods such as IA3, VeRA, FourierFT, AdaLoRA, DoRA, BOFT, and Lily modify different parts of the adaptation process.
Some minimize trainable parameters. Others improve rank allocation, preserve geometry, share projections, or reduce activation memory.
The central lesson is that trainable-parameter count and actual GPU memory are not the same metric.
Activation storage, optimizer design, adapted layer count, precision, checkpointing, and implementation kernels may have a larger effect on peak VRAM than the adapter file size alone.
Benchmark Audit
Hugging Face evaluated the methods under the same base model, dataset, training code, evaluation code, hardware, and general conditions. The suite tracks test quality, peak VRAM, runtime, checkpoint size, and model drift or forgetting.
| Task | Method | Main result | Peak memory | Interpretation |
| Llama-3.2-3B math | Standard LoRA | 48.1% accuracy | 22.5GB | Weaker than optimized LoRA |
| Llama-3.2-3B math | rsLoRA | 53.2% accuracy | 22.6GB | Strong accuracy-memory balance |
| Llama-3.2-3B math | Lily | 54.9% accuracy | 25.6GB | Highest listed accuracy, higher memory |
| Llama-3.2-3B math | BEFT | 32.9% accuracy | 20.2GB | Lower quality, lower memory |
| FLUX image adaptation | LoRA | 0.697 DINO similarity | 9.97GB | Below the reported Pareto frontier |
| FLUX image adaptation | OFT | 0.708 DINO similarity | 9.01GB | Better score and lower memory |
The benchmark is more controlled than comparisons assembled across unrelated papers.
However, it is not definitive.
Hugging Face acknowledges that exhaustive, method-specific hyperparameter tuning is difficult. A configuration may favor one method, and two tasks cannot represent all language, vision, audio, classification, reasoning, or domain-adaptation workloads.
Accuracy, Memory, and Trainable Parameters
A PEFT choice should be evaluated across several axes.

Accuracy
A method may fit one task better because its structural assumptions match the required adaptation.
Lily’s cross-layer sharing may help some reasoning tasks. OFT’s constrained transformations may suit visual concept adaptation. Prompt tuning may work well when the model already possesses the required capability but needs task conditioning.
Training memory
Peak VRAM depends on more than the number of trained parameters.
It also includes:
- Forward activations
- Backward activations
- Optimizer states
- Temporary tensors
- Precision format
- Gradient checkpointing
- Number of modified layers
This explains why a method with fewer trainable parameters can still use more memory than expected.
Checkpoint size
Prompt tuning and highly compressed methods can produce extremely small task files. LoRA checkpoints are also compact and widely supported.
Inference overhead
Merged LoRA adapters can add little or no runtime overhead after merging.
Prompt tokens consume context and computation. Traditional adapters add modules to each forward pass. Some methods cannot be merged into the base model at all.
Multi-adapter serving
LoRA has a major operational advantage when one server must dynamically load or switch among many adapters. Downstream support for non-LoRA methods remains significantly weaker.
Implementation Maturity May Decide the Winner
A two-point benchmark gain may not justify a fragile production stack.
LoRA works across a broad ecosystem, while many alternatives are supported mainly inside Hugging Face PEFT or research repositories.
Hugging Face notes that systems such as vLLM support LoRA adapters but generally do not offer equivalent native support for every other PEFT method. To reduce this gap, PEFT now includes functions for converting some non-LoRA adapters into LoRA-compatible checkpoints. Not every method supports conversion, and conversion may introduce approximation differences.
Before choosing an alternative, teams should verify:
- Quantized-model support
- FSDP or DeepSpeed compatibility
- Ability to merge weights
- Inference-server support
- Adapter switching
- Export formats
- Checkpoint stability
- Community maintenance
- Reproducible examples
Why This Matters
Fine-tuning teams often choose LoRA before establishing the real optimization objective.
But different projects need different things.
A consumer-GPU experiment may prioritize peak VRAM. A hosted inference platform may prioritize mergeability. A research benchmark may prioritize maximum accuracy. A multi-tenant service may need rapid adapter switching. An image-generation model may respond better to a geometry-preserving method such as OFT.
The new benchmark encourages teams to treat PEFT selection as an engineering search problem rather than a fixed recipe.
Which PEFT Method Should You Use?
Use LoRA or rsLoRA when:
- You need the strongest ecosystem support
- Quantized training matters
- vLLM or multi-adapter serving is planned
- You want low deployment risk
- Performance is already sufficient
Try LoRA-FA when:
- Training memory is the main constraint
- You want to stay inside the LoRA ecosystem
- The target architecture is supported
Try Lily when:
- Maximum task accuracy is more important than minimum memory
- Cross-layer adaptation may help
- You can validate a newer implementation carefully
Try OFT when:
- You are adapting image-generation or vision models
- Your tests show gains on the target dataset
- Your deployment stack supports it
Try adapters or prompt tuning when:
- You need many tiny task variants
- Modularity matters
- Some inference overhead is acceptable
- Your task does not require extensive weight transformation
Limitations and Unanswered Questions
The comparison remains early.
It does not establish how methods behave across:
- Larger language models
- Instruction tuning
- Code generation
- Multilingual adaptation
- Long-context tasks
- Speech models
- Reinforcement learning
- Different quantization formats
- Distributed training
- High-throughput production serving
Random variation also matters, especially where differences are small.
Most importantly, the optimal hyperparameters differ by method. Giving every technique the same training budget improves comparability but may prevent some methods from reaching their best possible result.
Simple Explanation for Beginners
LoRA is like attaching a small adjustable part to a large machine instead of rebuilding the whole machine.
Other PEFT methods attach different kinds of parts.
One may use less memory. Another may produce better answers. Another may be easier to deploy.
The new benchmark shows that the most popular attachment is not always the best one for every job.
Conclusion: LoRA Alternatives PEFT Benchmark
The new LoRA alternatives PEFT benchmark does not show that LoRA is obsolete.
It shows that default LoRA can be weaker than optimized LoRA, Lily can deliver higher accuracy at greater memory cost, and OFT can outperform LoRA on a specific image-generation task while using less VRAM.
LoRA remains the strongest operational default because of its implementation maturity and serving support.
The better development practice is to benchmark several methods on the actual task and choose the point that best balances quality, memory, checkpoint size, inference overhead, and production compatibility.
Final Takeaways
- Hugging Face published the comparison on June 18, 2026.
- LoRA appears in 98.4% of the sampled single-method PEFT model cards.
- Standard LoRA was not the strongest LoRA configuration in the math benchmark.
- rsLoRA reached 53.2% accuracy versus standard LoRA’s 48.1%.
- Lily reached 54.9% but used more peak memory.
- OFT beat LoRA on both DINO similarity and memory in the image benchmark.
- Trainable-parameter count does not directly equal peak VRAM.
- Prompt tuning and adapters can introduce different inference overhead.
- Non-LoRA methods have weaker downstream-serving support.
- No PEFT method is universally best across tasks.
Suggested Read:
- What Is LoRA Fine-Tuning?
- How to Fine-Tune an LLM
- QLoRA Explained
- Best Open-Source AI Models
- China’s Cheap AI Model Is Making Claude Look Expensive
- AI Agents Can Now Work for Hours
FAQ: LoRA Alternatives PEFT Benchmark
Is LoRA the best PEFT method?
Not universally. It offers strong performance and excellent ecosystem support, but Hugging Face’s benchmark found alternatives that won on accuracy, memory, or both for specific tasks.
What are the best alternatives to LoRA?
Relevant alternatives include Lily, OFT, traditional adapters, prompt tuning, IA3, VeRA, FourierFT, BOFT, and optimized LoRA variants such as rsLoRA and LoRA-FA.
How is Lily different from LoRA?
Lily connects low-rank projectors across layers through shared projector experts, giving the adaptation more cross-layer flexibility than independent LoRA modules.
Does OFT use less memory than LoRA?
In Hugging Face’s image-generation test, OFT used 9.01GB compared with LoRA’s 9.97GB and also achieved a higher DINO similarity score. That result may not generalize to every task.
What is LoRA-FA?
LoRA-FA is a memory-focused LoRA training approach that freezes part of the adapter and reduces activation-memory requirements while retaining the LoRA deployment format.
Which PEFT method should I use?
Start with LoRA or rsLoRA for compatibility, then compare one memory-focused method and one task-appropriate alternative using the same data, hardware, evaluation metric, and training budget.
References:
- Hugging Face’s official Beyond LoRA benchmark analysis.
- Official Hugging Face PEFT documentation and supported-method list.
- Official PEFT documentation for converting supported non-LoRA methods into LoRA checkpoints.
- The original Lily research paper.
- Hugging Face PEFT release notes for prompt-tuning improvements.