Google Wants Coding Agents to Spot Problems Before Developers Ask
Google published a preliminary evaluation framework for proactive coding agents on June 22, 2026, arguing that current benchmarks do not measure whether an AI system can notice useful engineering problems before a developer explicitly assigns them.
The research matters because coding agents are already becoming more autonomous. Tools such as Jules can inspect repositories, plan work, modify code, and create pull requests. But autonomy only measures whether an agent can carry out a task. Proactivity asks a harder question: can the agent identify the right task by itself—and avoid distracting the developer with weak suggestions?
Google’s preliminary proactive coding agent benchmark uses 705 historical bugs and 1,178 code changes from internal codebases. The company reports that one exploration round produced an average insight relevance score of 4.5 out of 5, while increasing exploration from two rounds to three improved Hit@5 from 33% to 57%.
What Is a Proactive Coding Agent Benchmark?
A proactive coding agent benchmark evaluates whether an AI system can discover and communicate useful software-engineering insights without receiving a narrowly defined task.
Traditional coding evaluations usually provide a clear issue:
- Here is the bug report.
- Here is the repository.
- Produce a patch.
A proactive benchmark begins with a broader objective or incomplete context. The agent must explore the codebase, identify what appears important, gather supporting evidence, and decide whether it has found something worth telling the developer.
This changes the unit of evaluation.
The benchmark is no longer only asking, “Did the patch pass the tests?”
It is asking:
- Did the agent notice a real problem?
- Was the observation relevant to the team’s goal?
- Was the evidence strong enough?
- Did the agent prioritize the most valuable insight?
- Should it have interrupted the developer at all?
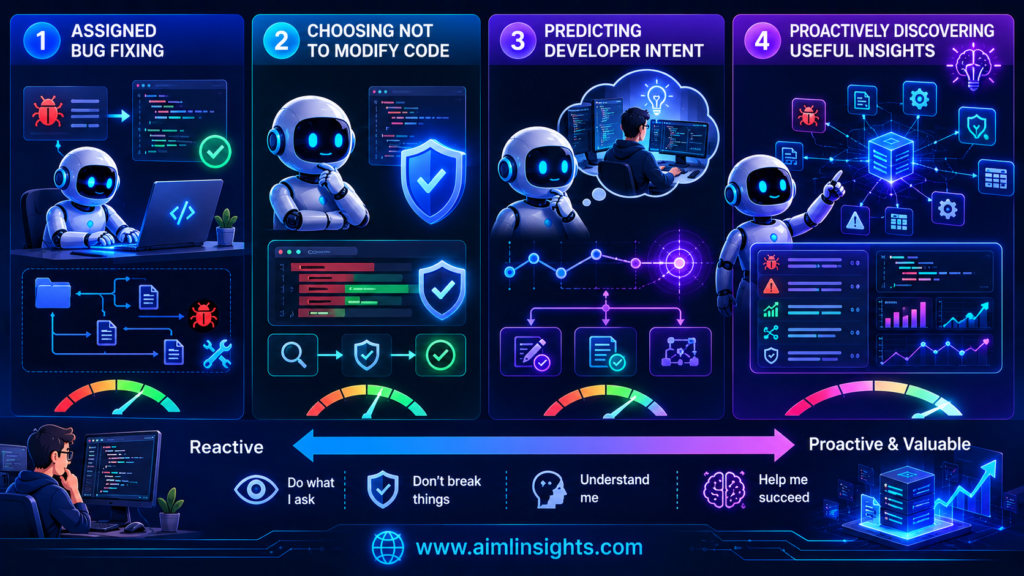
Autonomy and Proactivity Are Not the Same
An autonomous coding agent can complete a task with limited supervision.
For example, it may receive a bug report, inspect the repository, create a plan, edit files, run tests, and submit a pull request. Jules was originally introduced around this model: it could take an assigned issue, plan a solution, and execute the work under developer supervision.
A proactive coding agent goes further.
It watches repository changes, issue history, test failures, developer activity, or project goals and decides whether something deserves attention before the user asks.
A highly autonomous agent may still be completely reactive. It can perform complex work, but only after receiving instructions.
A proactive agent must choose when to act.
That decision is risky. Speaking too often creates alert fatigue. Staying silent may allow a real problem to remain hidden.
Google’s “Insight Policy” Explained
Google’s research centers on the idea of an insight policy.
The insight policy is the decision process that determines:
- What matters next
- What evidence supports the observation
- Whether the finding should be surfaced
- What form the intervention should take
- How the system should adapt after developer feedback
The output may be a notification, a question, a draft change, or deliberate silence.
This is important because useful proactivity is not the same as producing more suggestions.
A coding agent that reports ten speculative concerns may look active, but it may be less useful than an agent that surfaces one well-supported risk and ignores nine weak signals.
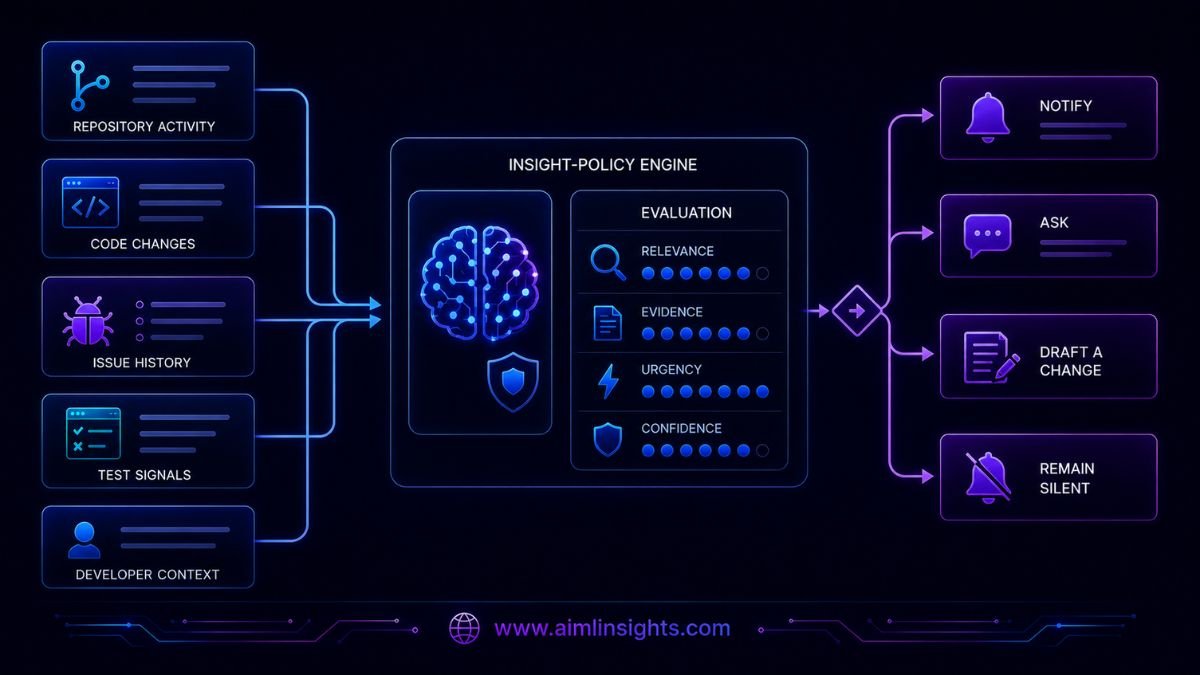
A good insight policy therefore needs both recall and restraint.
How Google Built the Preliminary Evaluation
Google used historical bug-fixing activity as a form of ground truth.
The researchers grouped related bugs using two heuristics:
- Temporal proximity: issues fixed around the same period
- Semantic similarity: issues describing related technical symptoms
The assumption is that several related bugs may reflect one broader engineering goal.
For example, separate reports about timeouts, configuration failures, and flaky network tests may all belong to a larger objective such as improving sandbox reliability.
The evaluation process was:
- Cluster related historical bugs into a higher-level goal.
- Treat the individual bugs as target insights.
- Revert the codebase to its exact pre-fix state.
- Allow the agent to explore for a fixed number of rounds.
- Ask the agent to generate its most important insights.
- Use an LLM judge to score each insight from 1 to 5 against the historical targets.
- Measure average top score and Hit@K.
The preliminary dataset contained 705 bugs and 1,178 code changes from internal Google repositories.
Why Exploration Rounds Matter
Google gave the agent a limited exploration budget, denoted as N.
An exploration round gives the agent another opportunity to inspect the repository, gather evidence, and refine its understanding.
Google reports that one round produced an average top relevance score of 4.5 out of 5 for relatively straightforward problems. More complex issues were harder. When the exploration budget increased from two rounds to three, Hit@5 increased from 33% to 57%.
That suggests extra investigation can uncover secondary signals the first pass misses.
But more exploration also has costs:
- Higher latency
- More model calls
- More repository reads
- Greater token usage
- More chances to generate speculative conclusions
The benchmark therefore needs to evaluate both insight quality and the resources used to obtain it.
Benchmark Audit
| Evaluation element | Reported setup or result | Baseline | Evaluation owner | Independently verified? |
| Dataset | 705 bugs, 1,178 code changes | No public baseline dataset | No | |
| Exploration budget | Up to three rounds | Fewer exploration rounds | No | |
| Average top relevance | 4.5/5 after one round | Not disclosed | Google using an LLM judge | No |
| Hit@5 | 33% at two rounds; 57% at three rounds | Two-round setup | No | |
| Ground truth | Historical bug clusters and fixes | Human engineering history | Google internal data | Not publicly reproducible |
The evidence is preliminary.
Google has not yet published enough detail to independently reproduce the benchmark because the codebases are internal. The LLM judge introduces another source of uncertainty: evaluation quality depends on the judge model, rubric, prompt, and consistency.
The methodology also assumes that historical bug clusters represent the best set of insights an agent should have produced. That is plausible, but not guaranteed. An agent might discover a valid issue that human engineers did not fix during the recorded period.
Equivalent-settings questions also remain:
- Did each exploration round receive the same token budget?
- Was the agent allowed identical tools in every run?
- How were duplicate insights handled?
- How many total suggestions did the model generate?
- What was the false-positive rate?
- How often did the agent correctly choose silence?
Why SWE-bench Does Not Measure Initiative
SWE-bench is designed around issue resolution.
The benchmark gives an agent a repository and an existing issue, then checks whether the patch resolves the problem through tests.
That is valuable for measuring task execution, but the key engineering decision has already been made: someone identified the problem and wrote the issue.
A proactive agent must operate before that point.
It must infer the higher-level goal, inspect the codebase, identify risks, and decide which observations deserve attention. Google therefore argues that issue-resolution benchmarks measure autonomy, not initiative.
Comparison With Existing Coding-Agent Evaluations
| Benchmark type | What the agent receives | What it measures | What it misses |
| SWE-bench-style evaluation | A defined issue and repository | Patch correctness | Problem discovery and interruption quality |
| FixedBench | A stale or already resolved issue | Ability to abstain from unnecessary changes | Broader proactive discovery |
| Intent-prediction benchmarks | IDE traces and repository context | Ability to infer developer intent | End-to-end diagnostic usefulness |
| Google’s preliminary approach | Broad engineering goal and pre-fix codebase | Quality of unsolicited diagnostic insights | Public reproducibility and live user impact |
FixedBench is particularly relevant because it shows the opposite failure mode: agents often act when no code change is needed. Its authors report that recent systems proposed undesirable changes in 35% to 65% of no-fix cases.
ProCodeBench adds another warning. Its authors used real IDE traces from 1,246 developers and found that models struggled more on real behavior than on simulated traces, suggesting that synthetic evaluations may overestimate proactive intent prediction.
Why This Matters
Proactive coding agents could reduce the amount of work developers must manually identify and describe.
Potential use cases include:
- Detecting related failures across a subsystem
- Identifying tests that no longer cover important behavior
- Spotting risky configuration changes
- Suggesting documentation updates after API changes
- Finding repeated reliability problems
- Drafting a fix before a formal bug report is created
This could be valuable for large teams with complex repositories and high maintenance workloads.
It may be less suitable for small projects, highly sensitive codebases, or teams that cannot tolerate frequent unsolicited recommendations.
False Positives Are the Central Risk
A proactive system can fail even when its technical observation is plausible.
It may:
- Surface low-priority issues
- Interrupt at the wrong moment
- Misread temporary work as a defect
- Suggest changes that conflict with undocumented plans
- Duplicate known issues
- Expose sensitive code through cloud analysis
- Create pressure to review large volumes of machine-generated advice
A useful benchmark must therefore measure precision, silence quality, and developer acceptance—not just how many real bugs appear in the top five suggestions.
Google’s current preliminary results emphasize relevance and Hit@K, but do not yet report the full false-positive burden or interruption cost.
Simple Explanation for Beginners
An autonomous coding agent is like a developer who can complete an assigned ticket.
A proactive coding agent is like a teammate who notices a hidden problem before anyone writes the ticket.
That sounds better, but only when the teammate is usually right.
If the agent constantly raises weak concerns, it becomes distracting. Google’s benchmark is an attempt to measure whether the agent knows what is important enough to mention.
What Comes Next
Google says it plans to expand the evaluation to public GitHub issues and resolving pull requests, making the methodology more accessible to the wider research community. It is also exploring richer context sources such as issue trackers, team conversations, and design documents.
Future versions should report:
- Precision and false-positive rates
- Developer acceptance rates
- Cost per useful insight
- Time saved or lost
- Performance after user feedback
- Ability to remain silent
- Results across public repositories
- Comparisons with reactive and scheduled agents
Conclusion: Proactive Coding Agent Benchmark
The proactive coding agent benchmark proposed by Google highlights an important gap in today’s AI evaluation.
SWE-bench can show whether an agent fixes a defined issue. It cannot show whether the agent identifies the right issue before anyone asks.
Google’s insight-policy framework moves evaluation toward a more realistic question: can a coding agent discover useful work, support it with evidence, and exercise judgment about when to interrupt?
The preliminary results are promising, but they are internal and incomplete. The real test will be whether proactive agents help developers more often than they distract them.
Final Takeaways
- Google published its preliminary proactive coding-agent evaluation on June 22, 2026.
- The benchmark focuses on initiative, not only autonomous task execution.
- An insight policy decides what matters, what evidence supports it, and whether the agent should speak or remain silent.
- The preliminary dataset contains 705 bugs and 1,178 code changes.
- Google reports an average relevance score of 4.5 out of 5 after one exploration round.
- Hit@5 rose from 33% to 57% when exploration increased from two rounds to three.
- The results are internal, preliminary, and not independently reproducible.
- False positives and interruption cost remain major unanswered questions.
- SWE-bench measures issue resolution, not problem discovery.
- Future benchmarks need to measure useful silence as well as useful action.
Suggested Read:
- AI Agents Can Now Work for Hours
- Google Jules AI Coding Agent Explained
- AI Agent Frameworks Compared
- Best AI Coding Agents
- China’s Cheap AI Model Is Making Claude Look Expensive
- Best AI Tools for Students
FAQ: Proactive Coding Agent Benchmark
What is a proactive coding agent benchmark?
It evaluates whether an AI coding agent can discover useful problems or opportunities before receiving a specific instruction, while avoiding irrelevant interruptions.
How is proactivity different from autonomy?
Autonomy is the ability to complete an assigned task independently. Proactivity is the ability to decide what task or insight is worth surfacing in the first place.
What is an insight policy?
An insight policy is the system that decides what the agent notices, what evidence supports it, whether the finding should be shown, and how the agent learns from developer feedback.
Why does SWE-bench not measure proactivity?
SWE-bench starts with an existing issue. It tests whether an agent can implement a fix, not whether the agent can discover the issue independently.
How did Google evaluate Jules?
Google clustered related historical bugs, restored codebases to their pre-fix state, allowed limited exploration rounds, and used an LLM judge to compare predicted insights with historical fixes.
What are the risks of proactive coding agents?
The main risks are false positives, excessive interruptions, privacy exposure, duplicated work, and suggestions that conflict with developer intent.
References: