
Cisco’s FAPO Can Fix the Weakest Step in an AI Pipeline
Cisco Foundation AI published FAPO on June 17, 2026, introducing an automated system for optimizing multi-step LLM applications rather than tuning one prompt in isolation.
The research matters because modern AI systems rarely make only one model call. A production pipeline may retrieve documents, extract evidence, reason over the evidence, classify the result, and format the final answer. A failure in any early stage can corrupt every later stage.
FAPO is designed for developers, AI engineers, security teams, and enterprises that already have an evaluation dataset and want to improve an existing LLM workflow. The paper’s authors report that FAPO prompt optimization outperformed GEPA in 15 of 18 model-benchmark comparisons, with an average gain of 14.1 percentage points.
What Is FAPO Prompt Optimization?
FAPO stands for Fully Automated Prompt Optimization.
It is an open-source framework that lets Claude Code operate as an optimization agent inside a standardized code workspace. The agent evaluates the pipeline, inspects intermediate outputs, groups failures by cause, proposes a targeted change, runs a review step, evaluates the new version, and retains it only if performance improves.
The framework can optimize at three levels:
- Prompt wording
- Pipeline parameters
- Pipeline structure
That hierarchy is important.
FAPO does not immediately rewrite the whole application. It begins with the least invasive change: editing a prompt. It escalates to parameter changes or structural modifications only when failure attribution suggests that prompt edits cannot solve the main bottleneck.
Why Optimizing Each Prompt Separately Can Fail
Consider a retrieval-augmented question-answering pipeline:
Question → retrieval → evidence extraction → reasoning → answer formatting
Suppose the final answer is wrong.
The reasoning prompt may appear to be the obvious place to start. But the real problem might be that retrieval returned the wrong documents. Rewriting the reasoning prompt cannot recover evidence the model never received.
The same problem appears in other pipelines:
- A classification prompt cannot fix a missing input field.
- A formatter cannot repair an incorrect intermediate answer.
- A stronger final prompt cannot compensate for a retrieval depth that is too low.
- Better wording cannot enforce a constraint that should have been implemented as deterministic code.
FAPO addresses this by storing outputs from every pipeline step. It then classifies failures as prompt-addressable, parameter-related, or structural. Cisco says this makes it possible to distinguish problems such as verbose responses and formatting errors from missing retrieval stages or absent validation nodes.
How the FAPO Workflow Works
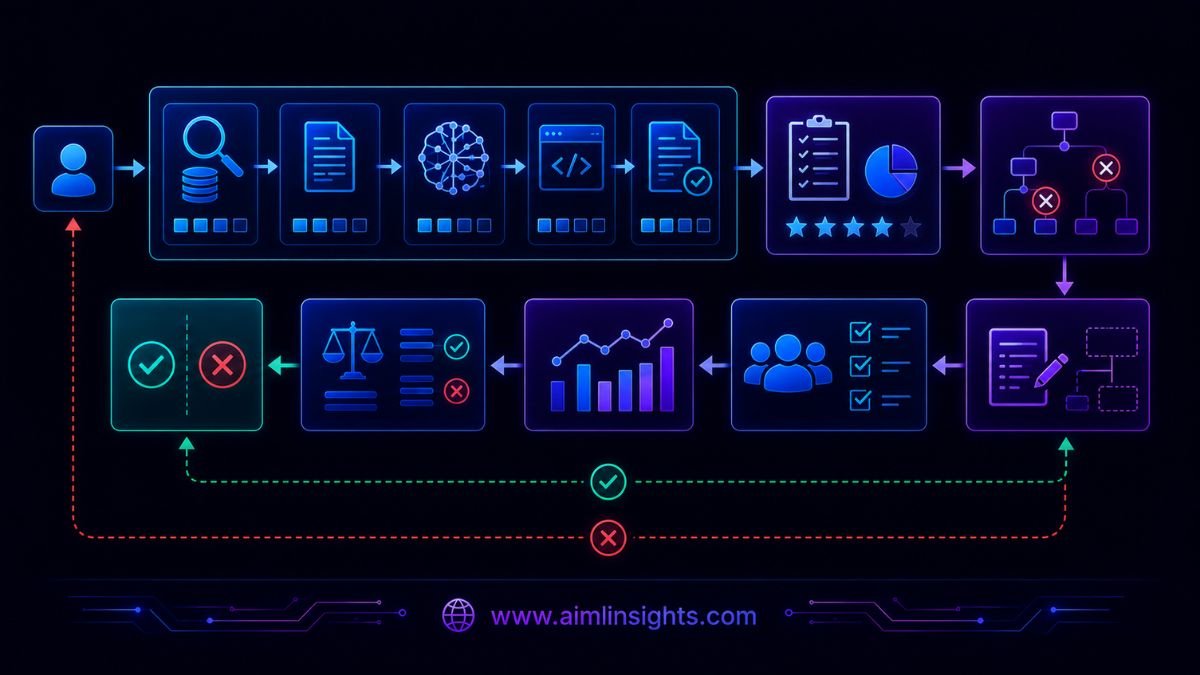
FAPO runs a six-stage closed loop.
1. Evaluate
The current pipeline runs against a dataset. FAPO collects final scores and intermediate outputs from every stage.
2. Attribute
Rule-based checks and LLM analysis group failures by their most likely source.
3. Propose
Claude Code proposes one scoped change aimed at the dominant failure cluster.
4. Review
A separate reviewing agent checks the proposed change for data leakage, scope violations, broken placeholders, and scorer manipulation.
5. Compare
The new variant is evaluated against the previous best version.
6. Iterate or escalate
Improved variants are retained. Failed variants are rejected. If prompt-level optimization reaches a plateau, FAPO can move to a permitted parameter or structural change.
The architecture can be summarized as:
Dataset → pipeline execution → step-level evidence → failure attribution → scoped modification → independent review → evaluation → accept or reject
The Components Behind FAPO
FAPO uses a two-layer design.
The first layer is a domain-independent core engine responsible for evaluation, pipeline execution, scoring, and artifact management.
The second layer contains isolated project workspaces called tenants. Each tenant stores its own prompts, datasets, chain definition, scorer, configuration, and optimization rules. This allows unrelated projects to run without sharing task-specific files.
The pipeline itself is represented through LangGraph. Claude Code orchestrates optimization, while specialized subagents handle failure attribution and independent review. The repository also supports Codex as an alternative optimization agent, although Claude Code is the default system described in the paper and official launch material.
What Is Genuinely New?
Automated prompt optimization is not new.
Methods such as GEPA already inspect execution traces, reflect on failures, generate prompt variants, and retain strong candidates. DSPy provides a broader programming framework in which structured LLM programs can be compiled against examples and scoring functions.
FAPO’s main contribution is pipeline-aware escalation.
GEPA optimizes textual parameters through reflective evolutionary search. FAPO can begin in that same prompt space, but it also examines which pipeline stage caused the error and can change parameters or chain structure when the permitted scope allows it.
For example, the system may:
- Increase retrieval coverage
- Add a missing reasoning or validation step
- Introduce deterministic format enforcement
- Change a chain parameter
- Rewrite only the prompt responsible for a recurring failure
This makes FAPO closer to automated systems debugging than simple prompt rewriting.
Benchmark Audit: FAPO vs GEPA
Cisco evaluated FAPO against GEPA on six benchmarks and three task models: GPT-4.1-mini, GPT-5.4-mini, and Gemma 3-12B.
Both systems reportedly started with the same baseline prompts and pipelines. Claude Opus 4.6 was used as FAPO’s orchestrator and GEPA’s reflection model.
| Benchmark | Main task | FAPO average | GEPA average | Reported gain | Structural changes used? |
| HoVer | Multi-hop fact verification | 83.8 | 48.5 | +35.3 pp | Yes |
| IFBench | Instruction-following constraints | 80.7 | 48.5 | +32.2 pp | Yes |
| LiveBench-Math | Mathematical reasoning | 62.0 | 52.6 | +9.4 pp | No |
| HotpotQA | Multi-hop question answering | 68.3 | 61.8 | +6.5 pp | No |
| Papillon | Privacy-preserving delegation | 94.9 | 90.7 | +4.2 pp | No |
| AIME | Competition mathematics | 12.9 | 16.0 | −3.1 pp | No |
The paper’s authors report:
- FAPO won 15 of 18 model-benchmark comparisons.
- It won 11 comparisons with non-overlapping mean-plus-or-minus-standard-deviation ranges.
- The average improvement over GEPA was 14.1 percentage points.
- On the six HoVer and IFBench comparisons where structural optimization was used, the average gain was 33.8 points.
- FAPO lost all three AIME comparisons, although the authors argue those differences were within trial variability.
How Strong Is the Evidence?
The results are promising, but several cautions matter.
First, the evaluation was performed by FAPO’s authors. It has not yet been independently replicated.
Second, FAPO and GEPA do not have identical capabilities in the study. FAPO could modify structure on HoVer and IFBench, while GEPA was restricted to prompt optimization. That comparison shows the value of a wider search space, but it is not a pure comparison of two prompt optimizers.
Third, the reported averages cover only three trials. Some results have large trial-to-trial variation, especially on structural tasks.
Fourth, cost and latency are not fully reported in the headline results. FAPO can evaluate as many as 50 candidate variants, and each variant may run the pipeline across many examples. Claude Code orchestration, reviewer calls, task-model calls, and structural evaluations can make the optimization process expensive.
The paper also uses different completion-budget semantics for reasoning and non-reasoning models. That does not invalidate the evaluation, but it complicates claims that every model was tested under perfectly equivalent computational conditions.
FAPO vs GEPA, DSPy, Prompt Search, and Manual Tuning
| Method | What it optimizes | Main strength | Main limitation |
| Manual pipeline tuning | Prompts, code, and structure through human inspection | Flexible and interpretable | Slow and dependent on expert intuition |
| Basic prompt search | Prompt variants | Simple to implement | Does not diagnose pipeline interactions |
| DSPy | Structured LLM programs, prompts, examples, and some parameters | Mature programmable framework | Requires developers to define modules, metrics, and optimization strategy |
| GEPA | Textual parameters using reflection and evolutionary search | Strong sample efficiency and trace-based diagnosis | Primarily optimizes textual components |
| FAPO | Prompts, parameters, and permitted chain structure | Step-level attribution and autonomous escalation | Higher complexity, agent cost, and risk of overfitting |
GEPA remains an important baseline because it uses natural-language reflection over full execution traces rather than relying only on a scalar score. Its original paper reports stronger performance than GRPO and MIPROv2 in its own evaluation setting.
DSPy is broader than either FAPO or GEPA. It lets developers express tasks as structured signatures and modules, then compile the program against a metric using optimizers including GEPA, MIPROv2, and others.
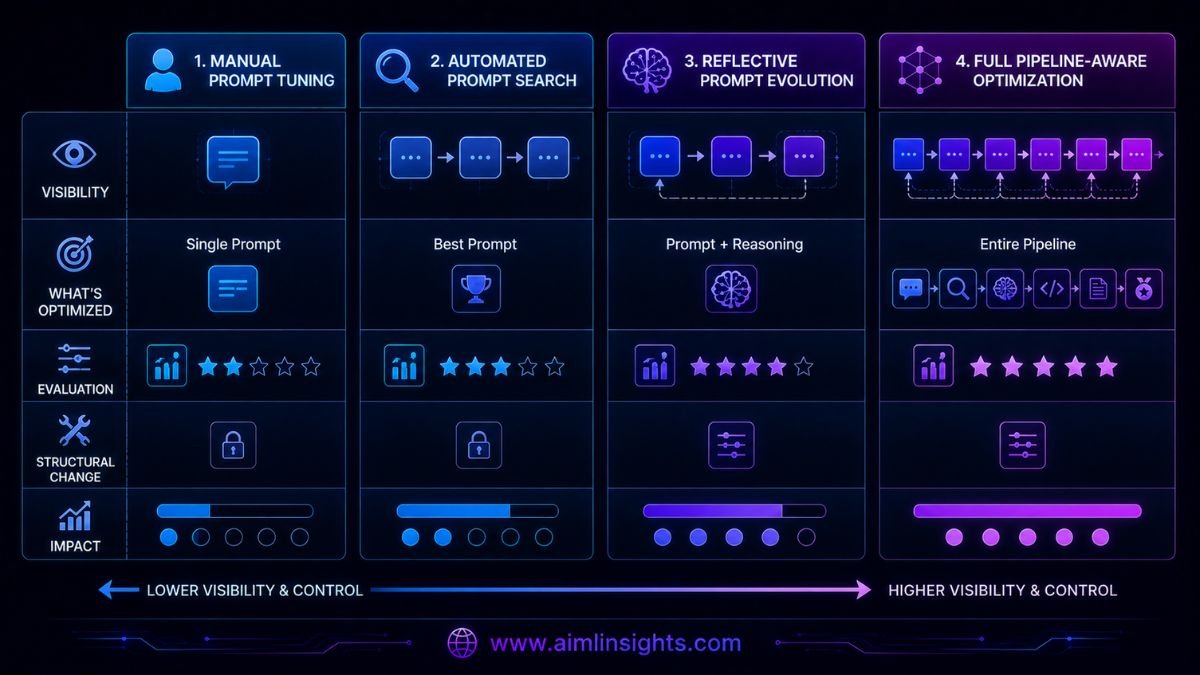
FAPO can therefore be viewed as a more opinionated autonomous optimization environment built around an inspectable codebase and an agent that can modify more than prompt text.
Why This Matters
Reliable LLM applications are increasingly systems problems.
A company may spend weeks improving a final prompt while the real bottleneck sits in retrieval, tool selection, missing validation, or a badly structured chain.
FAPO’s most useful idea is not that Claude Code can rewrite prompts. It is that optimization should follow evidence from the entire pipeline.
This could help teams:
- Improve RAG systems
- Tune multi-stage classifiers
- Optimize security workflows
- Refine tool-using agents
- Enforce structured outputs
- Diagnose failures before changing production code
Cisco also evaluated prompt-only FAPO on CTIBench-RCM, a security task mapping vulnerability descriptions to weakness categories. The authors report test-accuracy gains of 4.0 points on GPT-5, 7.1 points on Foundation-Sec-8B-Instruct, and 2.0 points on Foundation-Sec-8B-Reasoning.
Infrastructure, Cost, and Deployment Complexity
FAPO is open source, but it is not a one-click optimizer.
A team needs:
- A representative labeled dataset
- A validation metric or scorer
- A pipeline implementation
- Model API access
- Claude Code or another supported optimization agent
- LangGraph and Python infrastructure
- Clear guardrails defining what the agent may change
The quality of the dataset is crucial. If examples are narrow, incorrect, or unrepresentative, FAPO may optimize toward the wrong behavior.
API cost can also grow quickly. Every candidate variant may require repeated pipeline runs, plus analysis, review, and orchestration calls. Teams should measure total cost per accepted improvement rather than assuming automation is cheaper than human tuning.
Limitations and Failure Modes
FAPO’s autonomous loop creates several risks.
The system may overfit the validation set. The independent reviewer can reduce leakage, but it cannot guarantee generalization.
Failure attribution can also be wrong. If FAPO blames the reasoning step when retrieval is actually responsible, it may spend its variant budget optimizing the wrong component.
Structural changes create additional risk because they may increase latency, token use, maintenance burden, or failure surface even when benchmark accuracy improves.
Other open questions include:
- How well does FAPO generalize to noisy production datasets?
- How expensive is a complete optimization run?
- How often does reviewer approval prevent harmful variants?
- Can it optimize pipelines with nondeterministic tools?
- Does it preserve performance after the task model changes?
- How safely can it modify security-sensitive or regulated workflows?
Human review remains necessary before deploying any optimized pipeline.
Simple Explanation for Beginners
Imagine an AI workflow as an assembly line.
One station retrieves information. Another extracts facts. Another reasons. A final station writes the answer.
If the final product is wrong, rewriting instructions for the last worker may not help. The first station might have supplied the wrong material.
FAPO watches every station, tries to identify where the problem started, and then changes the smallest relevant part. If new instructions do not work, it may adjust the assembly line itself.
What Comes Next
FAPO shows that prompt optimization is moving toward full pipeline optimization.
The next step is independent testing across real enterprise systems, larger datasets, different orchestrator models, and production cost constraints.
Future evaluations should report:
- Total optimization cost
- Wall-clock time
- Number of model calls
- Structural complexity added
- Performance on unseen distributions
- Regression rates after model updates
- Direct comparisons with human experts
Conclusion: FAPO prompt optimization
FAPO prompt optimization turns Claude Code into an autonomous pipeline debugger and optimizer.
Its strongest contribution is step-level failure attribution followed by controlled escalation from prompt edits to parameters and structural changes.
Cisco’s reported 15-of-18 result against GEPA is notable, but the largest gains came where FAPO had permission to change the pipeline while GEPA remained prompt-only. That means the study supports a broader conclusion: sometimes the best prompt cannot fix a badly designed workflow.
For teams building multi-step LLM applications, that may be the most important lesson.
Final Takeaways
- Cisco Foundation AI published FAPO on June 17, 2026.
- FAPO optimizes multi-step LLM pipelines through Claude Code.
- It evaluates intermediate outputs, not only final answers.
- The system begins with prompt edits and can escalate to parameter or structural changes.
- A separate reviewer checks variants for leakage and scope violations.
- The authors report wins in 15 of 18 comparisons against GEPA.
- The average reported gain was 14.1 percentage points.
- The largest gains appeared when FAPO changed pipeline structure.
- Results are author-reported and not independently replicated.
- Deployment requires a high-quality dataset, scoring function, model APIs, and human review.
Suggestions Read:
- AI Agents Can Now Work for Hours
- China’s Cheap AI Model Is Making Claude Look Expensive
- Claude Code Updates
- How RAG Systems Work
- Best AI Development Frameworks
- Latest AI Research News
FAQ: FAPO prompt optimization
What is FAPO prompt optimization?
FAPO is Cisco Foundation AI’s open-source framework for automatically optimizing multi-step LLM pipelines. It can modify prompts, parameters, and permitted pipeline structure.
How does Cisco FAPO work?
It evaluates the current pipeline, records intermediate outputs, attributes failures to specific steps, proposes a scoped change, reviews that change, and keeps it only if evaluation performance improves.
How is FAPO different from GEPA?
GEPA uses reflective evolutionary search to optimize textual parameters. FAPO adds pipeline-aware failure attribution and can escalate to parameter or structural changes when prompt edits are insufficient.
Can FAPO change an LLM pipeline’s structure?
Yes, but only when the project’s scope rules allow it and failure analysis identifies a structural bottleneck.
Does FAPO require Claude Code?
Claude Code is the default orchestrator described in the paper and official release. Cisco also says the framework supports Codex as an alternative optimization agent.
Is FAPO better than manual prompt tuning?
It may reduce repetitive evaluation and failure analysis, but it still requires good datasets, reliable metrics, technical setup, and human review. It has not yet been independently proven to outperform expert tuning across all domains.
References: