Multimodal AI in Document Processing: How AI Reads Text, Tables, Images, and Layouts
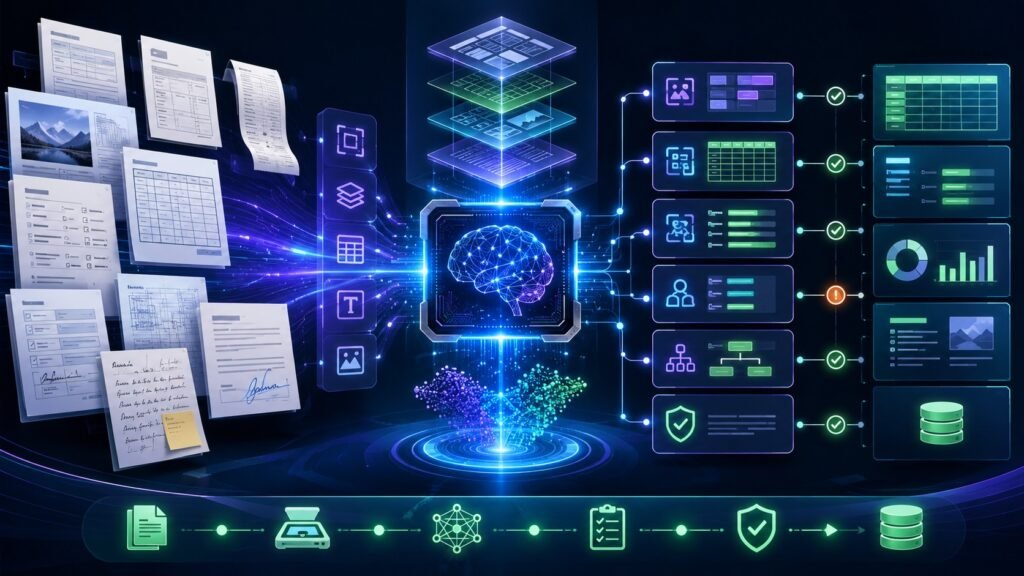
Multimodal AI in document processing helps AI understand documents as more than plain text. It combines OCR, layout analysis, table extraction, image understanding, handwriting recognition, entity extraction, and validation so businesses can turn PDFs, forms, invoices, receipts, and scanned files into usable structured data.
In Simple Terms
Multimodal AI in document processing means AI can read both the words and the visual structure of a document. A basic OCR system may extract text from a scanned invoice. A multimodal document-processing system can also understand where fields appear, which values belong to which labels, how tables are organized, and whether the document includes signatures, checkboxes, charts, or images.
This matters because business documents are rarely simple paragraphs. They contain layouts, page sections, tables, form fields, stamps, logos, handwriting, and visual cues. Multimodal AI helps preserve that context instead of flattening everything into messy text.
What Is Multimodal AI in Document Processing?
Multimodal AI in document processing uses multiple AI capabilities to analyze documents. These capabilities may include OCR for text recognition, computer vision for layout and visual elements, NLP for meaning, and machine learning for classification and extraction.
IBM describes Document AI as using OCR, machine learning, and NLP to analyze, interpret, and extract information from documents in a way that resembles human review. In a multimodal workflow, the system does not only ask, “What words are on the page?” It also asks, “Where are those words, what do they refer to, and how should they be used?”
Why OCR Alone Is Not Enough
OCR is important, but OCR alone often loses structure. If a system extracts every word from a table without preserving rows and columns, the output may be hard to use. If it reads “Total” and “$2,450” but does not connect them, the business system still needs extra logic or human review.
Modern document AI tools go beyond raw OCR. Google Document AI’s Form Parser can extract key-value pairs, tables, selection marks, generic fields, and text. Azure Document Intelligence describes extracting key-value pairs, tables, selection marks, and text from documents, including structured, semi-structured, and unstructured files. That is the core difference: multimodal document processing tries to understand structure, not just characters.
Core Parts of a Multimodal Document Workflow
| Stage | What It Does | Example |
| OCR | Reads printed or handwritten text | Extract invoice text |
| Layout analysis | Understands page structure | Detect headers, sections, columns |
| Table extraction | Preserves rows and columns | Extract invoice line items |
| Key-value extraction | Links labels to values | Match “Due Date” with date |
| Visual recognition | Detects signatures, stamps, images | Find signed approval section |
| Classification | Identifies document type | Invoice vs contract vs claim |
| Validation | Checks output for errors | Confirm total equals line items |
Common Document Types
Multimodal AI is useful for documents that combine text and visual structure. Common examples include invoices, receipts, contracts, insurance claims, bank statements, tax forms, onboarding forms, medical records, shipping documents, purchase orders, resumes, legal filings, and compliance reports.
Each document type has different challenges. Invoices need vendor names, totals, due dates, and line items. Contracts need clauses, parties, dates, obligations, and signatures. Healthcare forms may include handwritten notes, checkboxes, tables, and patient identifiers. A good document-processing workflow should be designed around the document type, not only the file format.
Real-World Use Cases
Finance teams use multimodal document processing to extract invoice data, match purchase orders, verify totals, and reduce manual entry. Insurance teams use it to process claim forms, photos, reports, and supporting documents. Legal teams use it to review contracts, extract dates and obligations, and organize clauses.
Healthcare administrators use document AI to process referrals, medical intake forms, lab reports, and scanned patient records. Logistics teams use it for shipping labels, bills of lading, customs forms, and delivery confirmations. In all these cases, the goal is not just reading text. The goal is turning document evidence into reliable workflow data.
Multimodal AI for Tables, Charts, and Images
Tables and charts are where multimodal document processing becomes especially valuable. A basic text extractor may break a table into disconnected words. A stronger multimodal system preserves structure so the information can be queried, validated, or loaded into databases.
Some documents also include embedded charts, diagrams, product photos, screenshots, or scanned images. These visual elements may contain important context that text-only extraction misses. Microsoft’s layout model documentation highlights extracting text, tables, selections, titles, section headings, page headers, page footers, and other layout elements.
How This Helps Multimodal RAG and AI Assistants
Document processing quality directly affects AI assistants and RAG systems. If a PDF is parsed badly, the retrieval system may lose table structure, mix unrelated sections, or miss important field relationships. That can lead to weak or incorrect answers.
A stronger multimodal document pipeline can preserve sections, tables, page metadata, images, and extracted fields before content enters search or RAG. This improves enterprise copilots, compliance assistants, document Q&A systems, contract search, and knowledge-base automation.
Benefits of Multimodal AI in Document Processing
The biggest benefit is reduced manual work. Teams can process high volumes of documents faster and focus human review on exceptions rather than routine extraction.
Another benefit is better data quality. Multimodal AI can connect labels to values, preserve tables, classify document types, and flag missing fields. It can also make old archives searchable and easier to analyze. For enterprises, this supports faster finance operations, claims processing, onboarding, legal review, procurement, and compliance workflows.
Limitations and Risks
Multimodal AI in document processing can still make mistakes. Accuracy may drop with blurry scans, poor lighting, handwriting, unusual layouts, rotated pages, overlapping stamps, low-resolution files, or complex tables. Even advanced systems need validation when the extracted data affects money, healthcare, legal obligations, or compliance.
Privacy is also important. Documents may contain financial records, identity data, medical details, employee information, customer addresses, or confidential contracts. Businesses should use access controls, audit logs, encryption, retention policies, and human review for sensitive workflows.
Suggested Read:
- What Is Multimodal AI? Complete Beginner’s Guide to AI Beyond Text
- Document Understanding AI
- Image to Text AI
- Text and Image Models
- Multimodal Embeddings
- Multimodal RAG Explained
- AI Tools for Document Extraction
- Multimodal Evaluation
FAQ: Multimodal AI in Document Processing Explained
What is multimodal AI in document processing?
Multimodal AI in document processing is AI that analyzes document text, layout, tables, images, checkboxes, handwriting, signatures, and structure together.
How is it different from OCR?
OCR extracts text. Multimodal document processing also understands layout, tables, key-value relationships, document type, visual elements, and structured outputs.
What documents can multimodal AI process?
It can process invoices, receipts, contracts, forms, insurance claims, shipping documents, bank statements, medical records, tax forms, and scanned PDFs.
Why is layout understanding important?
Layout shows which values belong to which fields, how tables are organized, where sections begin, and what visual evidence supports the extracted data.
How does multimodal document processing help RAG?
It improves the quality of content sent into retrieval systems by preserving sections, tables, metadata, visual context, and document structure.
What are the main risks?
The main risks are extraction errors, privacy exposure, poor handling of complex documents, over-automation, and lack of validation in sensitive workflows.
Final Takeaway
Multimodal AI in document processing helps businesses move beyond basic OCR by combining text extraction, layout understanding, tables, visual elements, classification, and validation.
To continue learning, read What Is Multimodal AI, Document Understanding AI, and Image to Text AI next.