
Multimodal AI and LLMs are closely related, but they are not the same thing. LLMs mainly focus on understanding and generating language, while multimodal AI can process multiple data types such as text, images, audio, video, documents, charts, and sensor data. Some modern LLMs are multimodal, but not every LLM is a multimodal AI system.
In Simple Terms
The easiest way to understand multimodal AI vs LLMs is this: an LLM is mainly a language-based AI model, while multimodal AI is an AI system that can understand more than one type of information.
A traditional Large Language Model can read a prompt, summarize text, answer questions, write code, translate language, and generate human-like responses. A multimodal AI system can go further by analyzing an image, listening to audio, interpreting a chart, reading a document, or understanding a video along with text. NVIDIA describes multimodal large language models as systems that can understand and generate across text, images, video, audio, and more.
What Are LLMs?
Large Language Models, or LLMs, are AI models designed to understand and generate language. They are trained on large amounts of data and are commonly used for chatbots, writing assistants, summarization, coding help, translation, research support, and question answering. IBM describes LLMs as deep learning models trained on immense data and capable of understanding and generating natural language and other types of content.
Most people first encounter LLMs through text-based interfaces. You type a question, and the model generates a written answer. This makes LLMs extremely useful for language-heavy tasks. However, a traditional LLM does not automatically understand images, audio, video, or sensor data unless it has been extended with multimodal capabilities.
What Is Multimodal AI?
Multimodal AI is artificial intelligence that can process and connect multiple types of data. These data types are called modalities. Common modalities include text, images, audio, video, documents, charts, screenshots, and sensor signals. IBM defines multimodal AI as machine learning models that process and integrate information from multiple modalities, including text, images, audio, video, and sensory input.
For example, a multimodal AI system can look at a photo and answer a written question about it. It can analyze a screenshot, summarize a video, interpret a chart, or connect a voice command with visual information. This makes multimodal AI better suited for real-world workflows where information is not limited to text.
The Core Difference Between Multimodal AI and LLMs
The main difference is the type of information each system is designed to handle. LLMs are language-first. Multimodal AI is multi-input by design.
A text-based LLM can answer “Explain this policy in simple terms” if you paste the policy text. But a multimodal AI system can understand the policy document, inspect its tables, read scanned content, analyze charts, and answer questions about the full file structure. This is why multimodal AI is often more useful for document understanding, visual search, robotics, healthcare, customer support, and enterprise workflows.
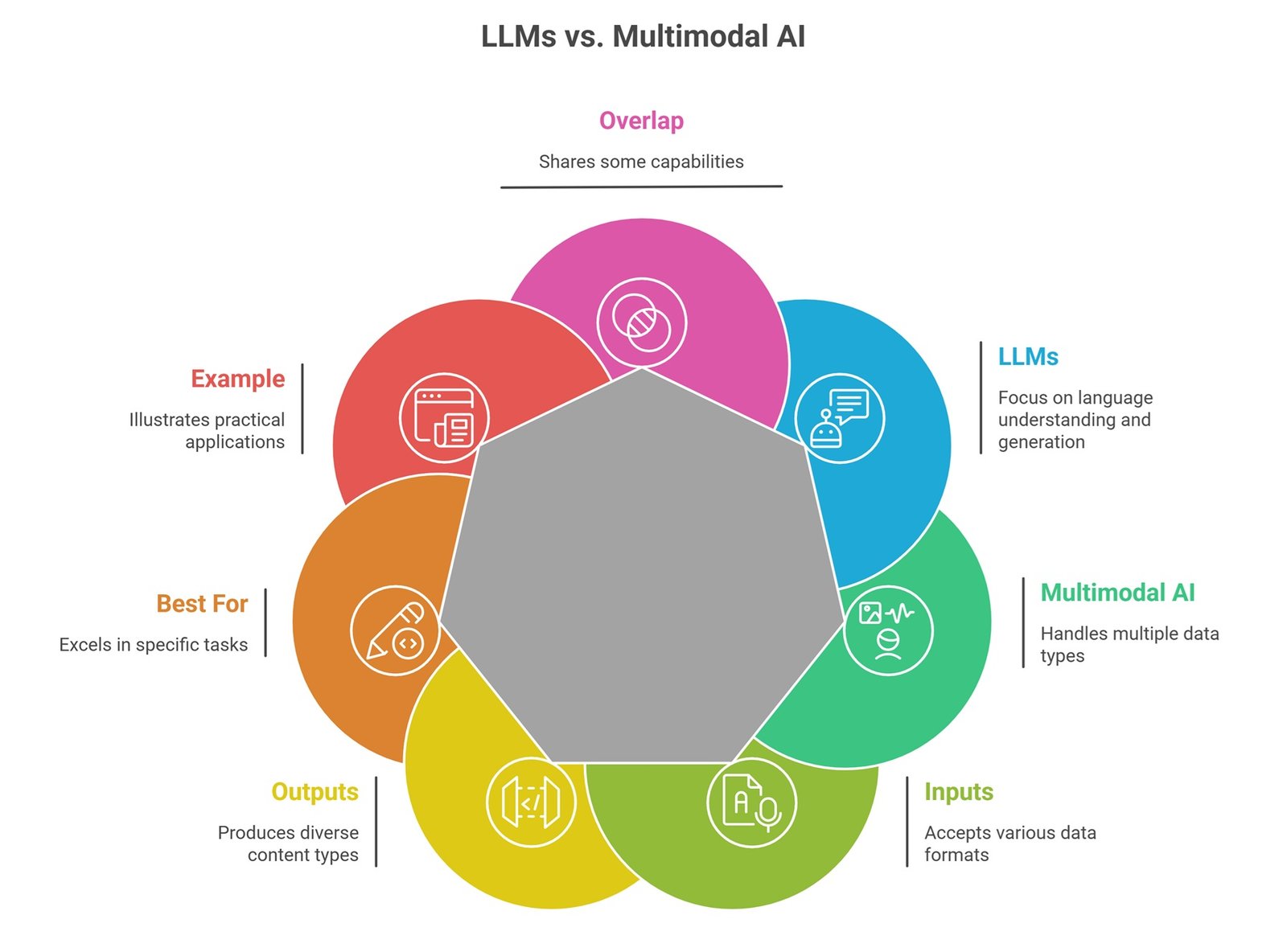
| Category | LLMs | Multimodal AI |
| Main focus | Language understanding and generation | Understanding multiple data types |
| Common inputs | Text prompts, documents, code | Text, images, audio, video, documents, sensors |
| Common outputs | Text, summaries, code, answers | Text, classifications, summaries, actions, generated content |
| Best for | Writing, Q&A, coding, language tasks | Visual, audio, document, and mixed-data workflows |
| Example | Summarize an article | Analyze a screenshot and explain the issue |
| Overlap | Some LLMs are multimodal | Some multimodal systems use LLMs |
Are LLMs Multimodal?
Some LLMs are multimodal, but not all. A traditional LLM may only process text. A multimodal LLM can process additional data types such as images, audio, documents, or video alongside text.
This is where confusion often happens. People may use “LLM” to describe any advanced AI assistant, but technically the model may be a multimodal LLM if it can process images, audio, or video. Google Cloud describes multimodal models as machine learning models that process information from different modalities, including images, videos, and text.
What Are Multimodal LLMs?
Multimodal LLMs are language models extended beyond text. They combine language reasoning with other input types such as images, audio, video, charts, screenshots, or documents.
A multimodal LLM may use a vision encoder to process images, an audio encoder to process speech, and a language model to reason and generate responses. The system converts different inputs into representations that can be aligned and used together. IBM describes multimodal LLMs as models that combine text, images, and more to improve AI understanding and interaction.
Simple Example: Text-Only LLM vs Multimodal AI
Imagine you ask an AI system: “What is wrong with this invoice?”
If you use a text-only LLM, you must paste the invoice text manually. If the invoice contains tables, stamps, signatures, handwritten marks, or layout-dependent information, the model may miss important context.
A multimodal AI system can inspect the invoice image or PDF, read text, understand table structure, identify fields, and answer your question more accurately. The LLM part helps explain the answer in natural language. The multimodal part helps understand the visual and document structure.
Multimodal AI vs LLMs in Business
Businesses use LLMs when the task is mainly language-based. Examples include writing emails, summarizing policies, drafting reports, answering FAQ questions, creating documentation, generating code, and translating text. These are high-value workflows because much business knowledge exists in written language.
Businesses use multimodal AI when important context appears across formats. A support team may need screenshots and chat history. A legal team may need scanned contracts and tables. A retail team may need product photos and descriptions. A healthcare team may need images, notes, and lab results. In these cases, a text-only LLM may not be enough because the task depends on visual, audio, or structured context.
When Should You Use an LLM?
Use an LLM when the main input and output are language. If your users ask written questions, upload plain text, need summaries, generate reports, write code, or draft content, an LLM may be enough.
LLMs are especially useful for:
- text summarization
- writing assistance
- coding help
- language translation
- brainstorming
- FAQ chatbots
- policy explanation
- document drafting
For many teams, a strong LLM is the first step before adding multimodal capabilities.
When Should You Use Multimodal AI?
Use multimodal AI when users need the system to understand more than text. If the task includes images, screenshots, video, voice, charts, forms, scanned PDFs, or sensor data, multimodal AI is usually a better fit.
Multimodal AI is especially useful for:
- screenshot troubleshooting
- visual product search
- document processing
- image-based customer support
- medical imaging workflows
- robotics
- video analysis
- accessibility tools
- dashboard interpretation
The key question is simple: does the AI need to “see,” “hear,” or inspect files to do the job well? If yes, multimodal AI is likely the better direction.
Where LLMs and Multimodal AI Work Together
The most useful AI systems increasingly combine both. A multimodal AI system often uses an LLM as the reasoning and language-generation layer. The multimodal part processes images, audio, documents, or video. The LLM part explains the result in natural language.
For example, an enterprise assistant may analyze a dashboard screenshot, retrieve relevant business context, and generate an executive summary. A healthcare assistant may help organize scan data and clinical notes for professional review. A robotics system may understand visual scenes and language instructions together. These workflows show why the future is not “LLMs or multimodal AI,” but often LLMs inside multimodal systems.
Multimodal AI vs LLMs for Search
LLMs are useful for conversational search when the knowledge source is text. They can summarize search results, explain documents, and answer natural-language questions. However, they may struggle when the user wants to search with an image, screenshot, voice clip, or video frame.
Multimodal AI expands search beyond keywords and text prompts. A user can upload a photo to find similar products, ask questions about a chart, or search a video collection using natural language. This is why multimodal AI is important for visual search, document intelligence, enterprise search, ecommerce, media archives, and accessibility workflows.
Multimodal AI vs LLMs for AI Assistants
A basic LLM assistant is strong for writing, Q&A, coding, summarization, and research support. A multimodal AI assistant can do all that plus handle visual and audio context. It can inspect screenshots, summarize voice notes, interpret charts, analyze documents, and help users who prefer speaking or uploading files.
This matters because user expectations are changing. People increasingly expect AI assistants to understand what they show, not only what they type. As a result, many modern AI assistants are moving from text-only LLMs toward multimodal LLM systems.
Limitations and Risks: Multimodal AI vs LLMs
LLMs can hallucinate, misunderstand prompts, generate unsupported claims, or reflect bias from training data. They may also struggle with highly specialized or updated information unless connected to retrieval systems, tools, or current data sources.
Multimodal AI adds additional risks. It can misread images, misunderstand audio, miss details in video, or interpret charts incorrectly. It may also process sensitive inputs such as faces, voices, medical scans, financial documents, or private screenshots. Businesses need evaluation, human review, data governance, and access controls before using multimodal AI in sensitive workflows.
Common Mistakes About Multimodal AI vs LLMs
A common mistake is saying “LLM” when the system is actually multimodal. If an AI assistant can understand images or audio, it is more accurate to call it a multimodal LLM or multimodal AI system.
Another mistake is assuming multimodal AI always replaces LLMs. In reality, many multimodal systems depend on LLMs for reasoning and language output. Multimodal AI expands the input space, but LLMs often remain the engine that turns that understanding into readable answers.
Suggested Read:
- What Is Multimodal AI? Complete Beginner’s Guide to AI Beyond Text
- What Is a Large Language Model? Explained Simply
- How Multimodal AI Works
- Multimodal AI Explained Simply
- Multimodal AI Use Cases
- Multimodal AI vs Generative AI
FAQ: Multimodal AI vs LLMs
What is the difference between multimodal AI and LLMs?
LLMs mainly focus on language understanding and generation, while multimodal AI can process multiple data types such as text, images, audio, video, documents, and sensor data.
Are LLMs the same as multimodal AI?
No. Traditional LLMs are language-first models. Some modern LLMs are multimodal, but not every LLM can process images, audio, or video.
Can LLMs be multimodal?
Yes. Multimodal LLMs can process text along with other modalities such as images, audio, documents, or video.
What are multimodal LLMs?
Multimodal LLMs are language models extended to understand and generate across multiple data types, including text, images, audio, video, and documents.
Which is better: multimodal AI or LLMs?
Neither is always better. LLMs are better for text-heavy tasks, while multimodal AI is better when the task requires images, audio, video, documents, or sensor data.
When should businesses use multimodal AI instead of LLMs?
Businesses should use multimodal AI when workflows involve screenshots, scanned documents, charts, product photos, videos, voice recordings, or other non-text data.
Final Takeaway
Multimodal AI vs LLMs comes down to the type of information the system can understand. LLMs are language-first models built for text reasoning and generation. Multimodal AI systems can connect text with images, audio, video, documents, charts, and sensor data.
The future of AI will increasingly combine both. LLMs will remain important for reasoning and language output, while multimodal AI will make systems more useful in real-world workflows that involve visual, audio, document, and sensor context. To continue learning, read What Is Multimodal AI, How Multimodal AI Works, and Vision-Language Models Explained next.