How Multimodal AI Works: A Simple Guide to Text, Image, Audio, and Video AI
Multimodal AI works by converting different data types, such as text, images, audio, video, and documents, into machine-readable representations, combining them into shared context, and using that context to reason or generate outputs. This lets AI understand mixed information more naturally than text-only systems.
In Simple Terms
Multimodal AI works like an AI system with several “senses.” A text-only model can read words. A vision model can analyze images. A speech model can process audio. A multimodal AI model connects these abilities so it can understand more complete situations.
For example, if you upload a screenshot and ask, “What does this error mean?” the system does not rely only on your typed question. It also inspects the image, reads visible text, connects that visual information with your question, and generates a response. That is the basic idea behind how multimodal AI works: different input types are processed separately first, then joined together so the model can reason across them.
The Basic Multimodal AI Workflow
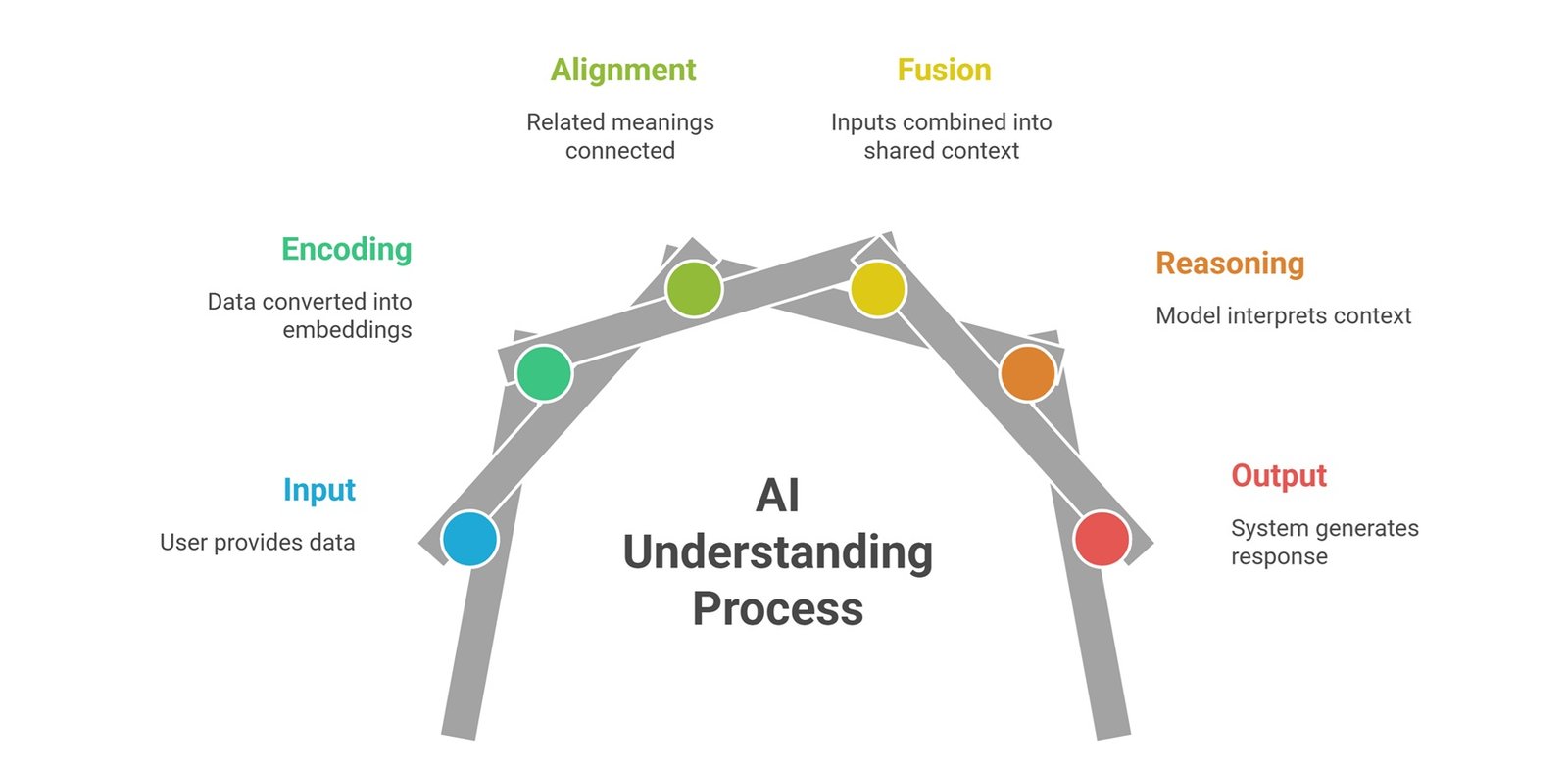
Most multimodal AI systems follow a similar workflow: input, encoding, alignment, fusion, reasoning, and output. The exact architecture can vary, but the core process is usually the same. First, the system receives one or more data types. Then specialized components convert those data types into embeddings, which are numerical representations of meaning.
After that, the system aligns the embeddings so text, images, audio, and video can be compared or combined. Then a fusion or reasoning layer connects the information. Finally, the model generates an answer, summary, classification, recommendation, image, voice response, or action. This workflow is what makes multimodal AI useful for AI assistants, document understanding, robotics, healthcare, customer support, and enterprise search.
Step 1: The System Receives Multiple Inputs
The first stage is input collection. A multimodal AI system may receive a written prompt, uploaded photo, audio recording, video clip, spreadsheet, PDF, chart, screenshot, or sensor stream. Each type of input has a different structure. Text is sequential. Images are spatial. Audio is time-based. Video combines images, motion, and sometimes sound.
This is why multimodal AI needs separate processing paths. A model cannot treat a voice recording exactly like a paragraph or a video frame exactly like a sentence. The system first prepares each modality in a form the model can process. Google Cloud describes multimodal models as systems that can process different modalities, including images, videos, and text, which is the foundation of this mixed-input workflow.
Step 2: Each Modality Is Encoded
After receiving inputs, the system converts each modality into embeddings. An embedding is a numerical representation of meaning. Text embeddings represent the meaning of words or sentences. Image embeddings represent visual patterns, objects, or scenes. Audio embeddings may represent speech, tone, rhythm, or sound patterns. Video embeddings may represent frames, motion, objects, and temporal changes.
Specialized encoders usually handle this step. A text encoder processes language. An image encoder processes visual data. An audio encoder processes sound. These encoders help the AI model turn very different data formats into representations that can later be compared and combined. Without this encoding step, the system would not have a practical way to connect a sentence, screenshot, and voice clip in one reasoning process.
Step 3: The Model Aligns Different Modalities
Encoding alone is not enough. The system also needs alignment, which means connecting related meaning across modalities. For example, the phrase “red car” should connect to an image region containing a red car. A spoken command should connect to its transcript. A chart label should connect to the visual data in the graph.
This alignment is what allows AI to understand relationships between different inputs. In image-caption training, the model may learn which text descriptions match which images. In audio-text systems, it may learn how speech maps to written words. In video understanding, it may connect actions, scenes, audio, and captions. Strong alignment improves cross-modal reasoning, which is central to multimodal AI.
Step 4: Multimodal Fusion Combines the Inputs
Multimodal fusion is the stage where information from different modalities is combined. The goal is to help the model build a richer understanding than it could get from one input alone. A chart plus a written question can be more useful than either one by itself. A customer complaint plus a screenshot can reveal the actual problem faster than text alone.
Fusion can happen in different ways. Some systems combine features early, soon after encoding. Others process each modality separately and combine information later. Advanced multimodal models may use attention mechanisms to decide which parts of the image, text, or audio matter most for a given question. This is where the model begins to build a shared view of the situation.
Step 5: The AI Reasons Across Modalities
Once the inputs are aligned and fused, the system can reason across them. This is the part users experience as intelligence. The AI may answer a question about an image, summarize a video, explain a chart, inspect a document, or respond to a voice command using visual context.
For example, a user might upload a product photo and ask, “Is this the same model as the one in the manual?” The system needs to compare visual details with text information from the manual. That is not simple image recognition or simple text search. It is multimodal reasoning. NVIDIA describes multimodal large language models as systems that can understand and generate across text, images, video, audio, and more, which reflects this broader reasoning capability.
Step 6: The System Generates an Output
After reasoning, the system produces an output. That output may be a written answer, summary, classification, recommendation, generated image, voice response, video edit, or workflow action. The output depends on the model and the application.
In a customer support tool, the output may be troubleshooting steps. In healthcare, it may be a draft summary for a clinician to review. In education, it may be a simple explanation of a diagram. In enterprise search, it may be an answer grounded in documents, screenshots, and dashboard data. The important point is that the answer is shaped by multiple inputs, not just typed text.
Multimodal AI Architecture at a Glance
| Stage | What Happens | Simple Example |
| Input | User provides text, image, audio, video, or document | Uploading a screenshot |
| Encoding | Each input becomes embeddings | Image converted into visual features |
| Alignment | Related meanings are connected | Error text matched with user question |
| Fusion | Inputs are combined into shared context | Screenshot + prompt merged |
| Reasoning | Model interprets the combined context | Finds likely cause of error |
| Output | System generates response or action | Gives troubleshooting steps |
Why Multimodal AI Needs More Than One Model Component
Multimodal AI often needs multiple components because each data type behaves differently. Text requires language understanding. Images require spatial recognition. Audio requires temporal processing. Video requires frame-level and time-based understanding. Documents may require layout understanding, OCR, tables, and reading order.
This is why multimodal AI architecture can be more complex than text-only AI. It may include vision encoders, audio encoders, language models, embedding layers, fusion mechanisms, retrieval systems, and safety filters. The result is more powerful, but also harder to build, evaluate, and deploy.
Real-World Example: Document Understanding
Document understanding is a practical example of how multimodal AI works. A business document may include paragraphs, tables, charts, signatures, stamps, images, and layout structure. A text-only system may extract words but miss how the page is organized.
A multimodal AI system can use OCR to read text, visual analysis to understand layout, table extraction to process rows and columns, and language reasoning to summarize the document. This is useful for invoices, contracts, insurance claims, compliance reports, medical forms, and financial documents. It shows why multimodal AI is valuable in workflows where meaning depends on both content and structure.
Real-World Example: Robotics and Autonomous Systems
Robotics is another strong example. A robot may need camera input, depth sensors, sound, location signals, and language instructions. If a person says, “Pick up the red box near the door,” the robot must understand speech, identify objects visually, locate the door, estimate distance, and plan movement.
This requires multimodal processing and reasoning. The robot cannot rely only on text or only on vision. It needs to combine several signals in real time. That is why multimodal AI is important for autonomous vehicles, drones, warehouse robots, industrial automation, and future embodied AI systems.
Benefits of Multimodal AI
The biggest benefit of multimodal AI is richer context. Text alone often leaves gaps. Images, audio, video, and documents can fill those gaps and help the system understand the user’s real situation more accurately.
Multimodal AI also makes interfaces more natural. Users can upload screenshots instead of typing long descriptions, speak instead of writing, or ask questions about charts and documents directly. For businesses, this can improve customer support, training, analytics, document processing, visual search, accessibility, and workflow automation.
Limitations and Risks: How Multimodal AI Works
Multimodal AI still makes mistakes. It may misread images, misunderstand audio, overlook details, or hallucinate unsupported explanations. A blurry photo, noisy recording, dense PDF, or misleading chart can reduce accuracy. More modalities do not automatically guarantee better answers.
Privacy and security are also important. Multimodal systems may process faces, voices, medical records, customer documents, financial charts, or confidential screenshots. Teams need access controls, evaluation, data governance, and human review for sensitive workflows. This is especially important in healthcare, finance, legal, education, and enterprise environments.
Suggested Read:
- What Is Multimodal AI? Complete Beginner’s Guide to AI Beyond Text
- Multimodal AI Explained Simply
- Multimodal AI Examples
- Multimodal AI Use Cases
- What Is a Large Language Model? Explained Simply
FAQ: How Multimodal AI Works
How does multimodal AI work?
Multimodal AI works by processing different data types, converting them into embeddings, aligning their meanings, combining them through fusion, and reasoning across them to generate useful outputs.
What is multimodal fusion?
Multimodal fusion is the process of combining information from different modalities, such as text, images, audio, and video, into a shared representation for reasoning.
Why does multimodal AI need embeddings?
Embeddings turn different inputs into numerical representations of meaning. This helps the model compare and combine text, images, audio, video, and documents.
How does AI understand text and images together?
The system uses text encoders and image encoders to represent both inputs, then aligns and fuses them so the model can reason about their relationship.
What are examples of multimodal AI?
Examples include AI assistants that analyze screenshots, document AI systems, healthcare tools using scans and notes, robots using vision and speech, and video analysis systems.
Is multimodal AI better than text-only AI?
It is better for tasks that need mixed information. Text-only AI can still be enough for purely language-based tasks, but multimodal AI is stronger when images, audio, video, or documents matter.
Final Takeaway
How multimodal AI works comes down to a clear process: collect different inputs, encode them into embeddings, align their meanings, fuse them into shared context, reason across that context, and generate an output.
This is why multimodal AI is becoming important for AI assistants, enterprise search, document processing, robotics, healthcare, education, and visual workflows. To continue learning, explore What Is Multimodal AI, Multimodal AI Examples, and Vision-Language Models Explained next.