Modern enterprise AI systems are rapidly evolving beyond simple chatbot architectures. Organizations increasingly deploy Large Language Models across:
- enterprise search systems
- AI assistants
- customer support copilots
- document intelligence platforms
- legal AI systems
- healthcare AI systems
- coding assistants
- research automation platforms
However, as enterprise AI adoption grows, organizations encounter a major architectural decision:
Should you use Retrieval-Augmented Generation (RAG) or rely on long context window models?
This became one of the biggest debates in modern AI infrastructure design.
Many new Large Language Models now support extremely large context windows capable of processing:
- hundreds of thousands of tokens
- large PDFs
- enterprise documents
- code repositories
- lengthy conversations
As a result, many people began asking:
If AI models can process huge amounts of information directly, do we still need RAG?
The answer is more complex than many assume.
Long context windows improve contextual capacity significantly, but they do not eliminate many core enterprise AI challenges including:
- hallucinations
- retrieval quality
- grounding reliability
- infrastructure cost
- scalability
- retrieval efficiency
- enterprise knowledge management
At the same time, RAG systems introduce their own challenges involving:
- retrieval pipelines
- vector databases
- orchestration complexity
- monitoring systems
- semantic retrieval optimization
Today, enterprises increasingly compare both architectures carefully when building production AI systems.
Understanding the differences between RAG and long context windows is essential for designing scalable, cost-effective, and grounded enterprise AI architectures.
In this guide, you will learn how RAG and long context windows work, their strengths and weaknesses, enterprise use cases, scalability trade-offs, hallucination implications, and why hybrid architectures are increasingly becoming the future of enterprise AI systems.
In Simple Terms
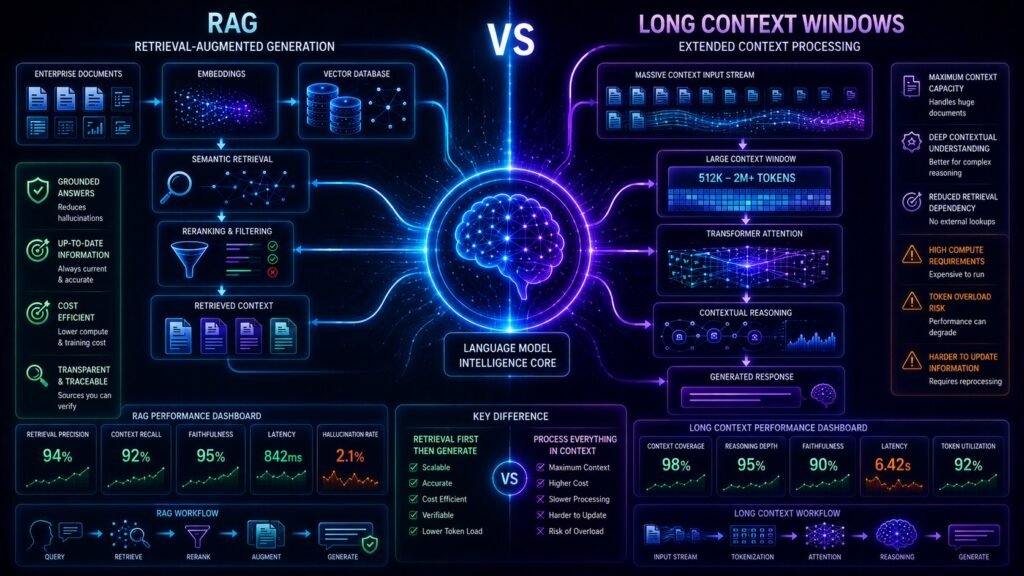
What Is RAG?
Retrieval-Augmented Generation (RAG) retrieves external information before generating answers.
Instead of placing all enterprise data directly into the prompt, RAG systems:
- search knowledge sources
- retrieve relevant documents
- filter contextual information
- pass only relevant context into the model
This improves grounding and retrieval efficiency.
What Are Long Context Windows?
Long context windows allow Large Language Models to process massive amounts of text directly inside a single prompt.
Modern models may support:
- 100K tokens
- 200K tokens
- 1 million+ tokens
This means users can upload very large documents directly into the model context.
Easy Analogy
Imagine asking a researcher a question.
A long context window approach gives the researcher an entire library to read all at once.
RAG works differently.
Instead of reading the whole library, RAG first finds the most relevant books and pages before answering.
Both approaches aim to improve contextual understanding, but they scale differently.
Why Enterprises Compare RAG and Long Context Windows
Modern organizations increasingly need AI systems capable of:
- processing massive knowledge bases
- answering grounded questions
- reducing hallucinations
- scaling efficiently
- supporting enterprise workflows
- managing large document collections
This created a major architectural debate:
Is retrieval still necessary when context windows become massive?
The answer depends heavily on:
- data scale
- retrieval requirements
- cost constraints
- latency requirements
- hallucination tolerance
- workflow complexity
Understanding How RAG Works
RAG combines retrieval systems with language models.
A modern RAG pipeline usually includes:
- embeddings
- vector databases
- semantic search systems
- reranking pipelines
- query rewriting systems
- prompt orchestration layers
- Large Language Models
The retriever finds relevant information before generation begins.
Core Components of a RAG System
| Component | Purpose |
| Embeddings | Represent semantic meaning |
| Vector Database | Stores searchable embeddings |
| Retriever | Finds relevant context |
| Reranker | Prioritizes retrieved chunks |
| LLM | Generates grounded answers |
This architecture improves contextual grounding significantly.
Understanding How Long Context Windows Work
Long context models rely on transformer attention mechanisms capable of processing very large token sequences.
Instead of retrieving information externally, these models attempt to reason over large contextual inputs directly.
This enables:
- large document analysis
- long conversation memory
- broad contextual reasoning
- multi-document processing
without retrieval systems.
Why Long Context Windows Became Popular
Long context models solved several limitations of earlier LLMs.
Older models struggled with:
- limited memory
- short prompts
- fragmented workflows
- context truncation
Large context windows improved contextual continuity dramatically.
Major Advantages of Long Context Windows
Simpler Architecture
Long context systems avoid external retrieval pipelines.
Better Context Continuity
The model sees broader contextual information simultaneously.
Easier Prototype Development
Organizations can build systems quickly without retrieval infrastructure.
Strong Multi-Document Reasoning
Long context models can reason across many related documents together.
Better Conversation Memory
Extended conversations become more manageable.
Major Limitations of Long Context Windows
Despite their strengths, long context models introduce major enterprise challenges.
Extremely High Token Costs
Large prompts dramatically increase inference costs.
Latency Problems
Long prompts slow down response generation significantly.
Context Dilution
Important information may become buried inside huge prompts.
Attention Degradation
Transformer attention quality weakens across extremely large contexts.
Hallucinations Still Exist
Long context windows do not eliminate hallucinations.
Poor Scalability for Massive Enterprise Knowledge
Large enterprises may manage millions of documents.
Directly loading everything into prompts is unrealistic.
Why RAG Remains Important
RAG solves several problems that long context windows alone cannot handle efficiently.
Selective Retrieval
RAG retrieves only relevant information.
Better Scalability
RAG handles massive enterprise knowledge bases efficiently.
Lower Inference Costs
Smaller prompts reduce token usage.
Better Knowledge Freshness
Enterprise documents update dynamically without retraining.
Improved Grounding
Retrieved evidence strengthens factual reliability.
Better Enterprise Search Integration
RAG integrates naturally with document repositories and knowledge systems.
Major Limitations of RAG
RAG also introduces operational complexity.
Retrieval Dependency
Weak retrieval weakens answer quality.
Infrastructure Complexity
RAG systems require many moving components.
Monitoring Challenges
Production RAG systems require evaluation and observability infrastructure.
Retrieval Noise Problems
Irrelevant retrieval weakens grounding quality.
Latency Overhead
Retrieval pipelines introduce additional processing steps.
RAG vs Long Context Windows: Key Differences
| Category | RAG | Long Context Windows |
| Primary Strategy | Selective Retrieval | Large Prompt Processing |
| Scalability | High | Moderate |
| Infrastructure Complexity | Higher | Lower |
| Token Costs | Lower | Higher |
| Latency | Moderate | High for huge prompts |
| Grounding | Strong | Moderate |
| Hallucination Reduction | Stronger | Limited |
| Knowledge Freshness | Dynamic | Depends on prompt |
| Enterprise Search Integration | Excellent | Weak |
| Massive Knowledge Base Support | Excellent | Poor |
Why Long Context Windows Do Not Replace Retrieval
One of the biggest misconceptions in AI today is:
“Large context windows eliminate the need for RAG.”
In practice, this is rarely true for enterprise systems.
Large organizations may manage:
- millions of documents
- constantly changing knowledge bases
- structured databases
- internal policies
- legal records
- customer histories
Loading all this information into prompts directly becomes impractical.
Retrieval remains essential for scalability.
Why Attention Saturation Matters
Transformer attention mechanisms struggle when prompts become excessively large.
Important contextual signals may weaken because:
- attention spreads too broadly
- semantic focus decreases
- irrelevant context increases
This phenomenon is often called context dilution or attention saturation.
RAG avoids many of these problems by retrieving targeted information only.
Why RAG Usually Reduces Hallucinations Better
RAG explicitly grounds answers using retrieved evidence.
Long context models may still hallucinate because:
- large prompts contain noise
- attention weakens over long sequences
- unsupported inference still occurs
Grounded retrieval improves factual reliability significantly.
When to Use Long Context Windows
Long context models work best when organizations need:
- document summarization
- multi-document reasoning
- long conversation memory
- rapid prototyping
- temporary contextual workflows
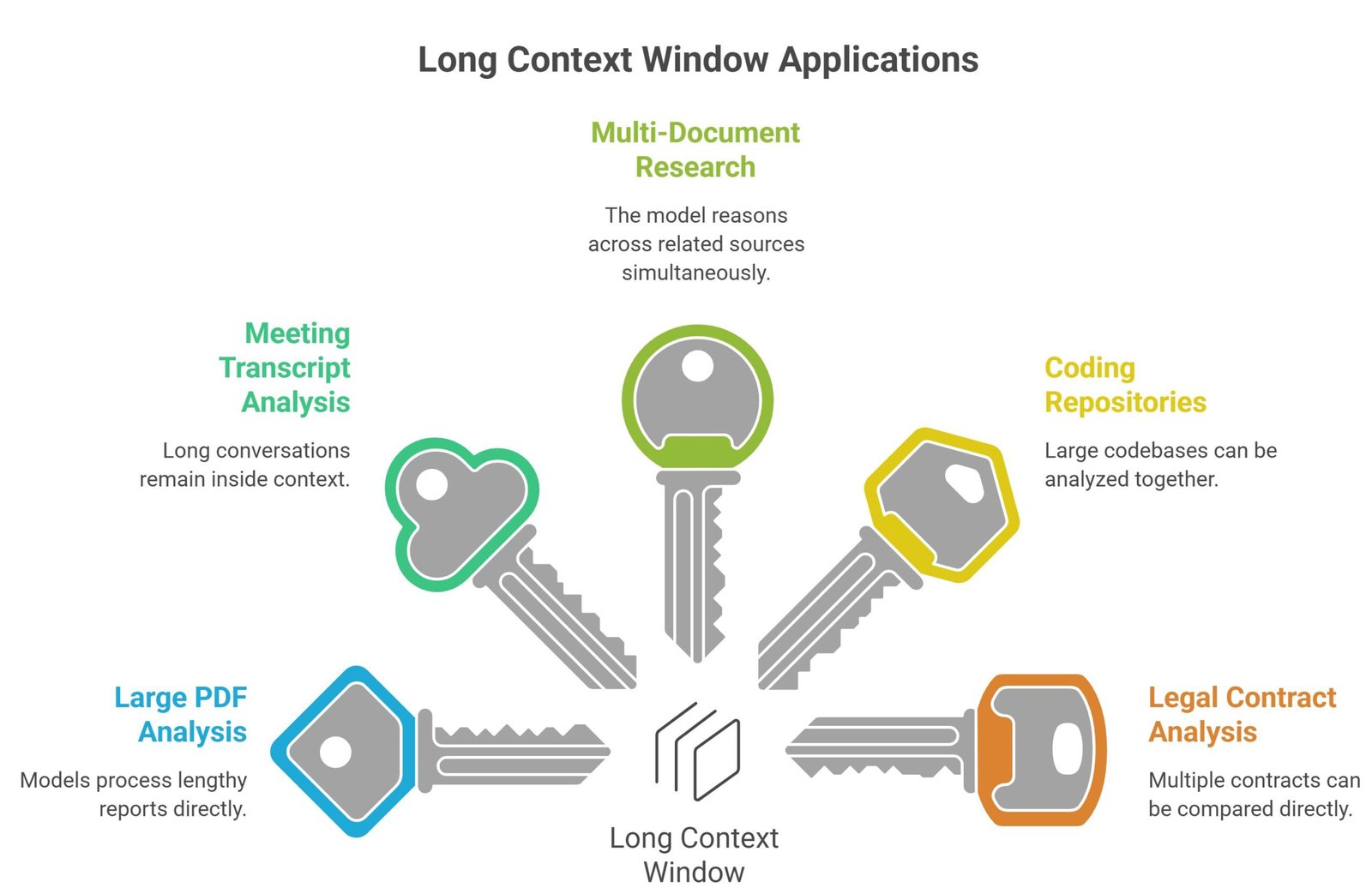
Best Long Context Window Use Cases
Large PDF Analysis
Models can process lengthy reports directly.
Meeting Transcript Analysis
Long conversations remain inside context.
Multi-Document Research
The model reasons across related sources simultaneously.
Coding Repositories
Large codebases can be analyzed together.
Legal Contract Analysis
Multiple contracts can be compared directly.
When to Use RAG
RAG works best when organizations need:
- enterprise search systems
- scalable AI assistants
- grounded AI generation
- dynamic knowledge retrieval
- hallucination reduction
- massive knowledge base access
Best RAG Use Cases
Enterprise AI Assistants
Employees retrieve internal company knowledge dynamically.
Customer Support AI
Support copilots retrieve troubleshooting guidance efficiently.
Healthcare AI Systems
Medical systems retrieve updated clinical information.
Legal Retrieval Systems
Legal assistants retrieve relevant case documents dynamically.
Ecommerce AI Platforms
Shopping assistants retrieve product information intelligently.
Why Hybrid Architectures Are Becoming the Future
Modern enterprises increasingly combine:
- RAG pipelines
- long context windows
together.
This creates hybrid AI architectures.
How Hybrid Systems Work
RAG retrieves relevant information selectively.
Long context windows process larger grounded contexts more effectively.
Together they improve:
- contextual reasoning
- groundedness
- retrieval efficiency
- scalability
- hallucination reduction
Example Hybrid Enterprise Architecture
| Layer | Purpose |
| Retriever | Finds relevant information |
| Vector Database | Stores embeddings |
| Reranker | Improves contextual relevance |
| Long Context LLM | Processes large grounded context |
| Evaluation Layer | Detects hallucinations |
This architecture is becoming increasingly common in enterprise AI systems.
Cost Comparison: RAG vs Long Context Windows
Cost remains one of the most important enterprise decision factors.
RAG Cost Structure
RAG costs include:
- embeddings generation
- vector databases
- retrieval infrastructure
- orchestration systems
However, prompt sizes remain smaller.
Long Context Cost Structure
Long context systems often generate:
- extremely high token usage
- expensive inference costs
- longer processing times
This becomes expensive at scale.
Which Approach Scales Better?
RAG generally scales better for large enterprise knowledge systems.
Long context windows scale well for localized reasoning tasks but become inefficient for massive enterprise knowledge bases.
Common Enterprise Mistakes
Many organizations misunderstand the strengths of each architecture.
Assuming Long Context Eliminates Retrieval
Large context windows still struggle with scalability and grounding.
Ignoring Retrieval Quality
Weak retrieval pipelines reduce RAG effectiveness dramatically.
Overloading Prompts
Huge prompts increase noise and reduce reasoning quality.
Underestimating Infrastructure Costs
Long context inference can become extremely expensive.
Why Evaluation Matters for Both Architectures
Organizations increasingly benchmark:
- hallucination rates
- groundedness
- retrieval precision
- context recall
- latency
- semantic relevance
- token efficiency
Continuous evaluation improves enterprise AI reliability significantly.
Future of RAG and Long Context Systems
Enterprise AI architectures are evolving rapidly.
Major trends include:
- adaptive retrieval systems
- retrieval-aware reasoning
- multimodal context architectures
- memory-augmented AI systems
- agentic retrieval orchestration
- dynamic context optimization
- long-context grounded reasoning systems
Future enterprise AI platforms will increasingly combine intelligent retrieval with advanced long-context reasoning capabilities.
Suggested
- What Is RAG in AI
- How RAG Works
- RAG vs Semantic Search
- Reducing Hallucinations in RAG
- Context Recall in RAG
- Retrieval Precision in RAG
- RAG Evaluation Metrics
- RAG Monitoring
FAQ: RAG vs Long Context Windows
What is the difference between RAG and long context windows?
RAG retrieves relevant information selectively before generation. Long context windows process large prompts directly inside the model.
Can long context windows replace RAG?
Not entirely. Large enterprise knowledge systems still require retrieval for scalability and grounding.
Which approach reduces hallucinations better?
RAG generally reduces hallucinations more effectively because retrieved evidence improves grounding.
Why are long context windows expensive?
Large prompts dramatically increase token usage and inference costs.
Can RAG and long context windows work together?
Yes. Hybrid architectures are becoming increasingly common in enterprise AI systems.
Final Takeaway
Understanding RAG vs long context windows is essential because enterprise AI architecture directly affects scalability, grounded generation quality, hallucination reduction, infrastructure cost, and production reliability.
Long context windows improve contextual reasoning and document processing capabilities, while RAG provides scalable retrieval, grounded generation, and efficient enterprise knowledge access.
Organizations that understand the strengths of both architectures can build more scalable, reliable, and production-ready AI systems.
That capability is becoming foundational for enterprise AI assistants, semantic search systems, healthcare AI platforms, legal retrieval systems, customer support copilots, and intelligent enterprise knowledge architectures across industries.