RAG Explained Simply: Beginner Guide to Retrieval-Augmented Generation
Artificial Intelligence systems are becoming more powerful every year. Modern AI chatbots can write content, summarize reports, answer technical questions, generate code, and even simulate human-like conversations.
But despite these impressive capabilities, traditional AI systems still have one major weakness: they sometimes generate incorrect or completely fabricated information.
This problem is known as hallucination.
That is exactly why Retrieval-Augmented Generation (RAG) became one of the most important innovations in modern AI architecture.
Instead of relying only on training data, RAG systems retrieve external information before generating answers. This makes AI responses more accurate, more grounded, and significantly more useful for real-world applications.
Today, many enterprise AI systems, customer support assistants, research tools, and intelligent search platforms rely on RAG workflows behind the scenes.
In this guide, we will explain RAG simply, including how it works, why it matters, where it is used, and why enterprises are rapidly adopting retrieval-based AI systems.
In Simple Terms
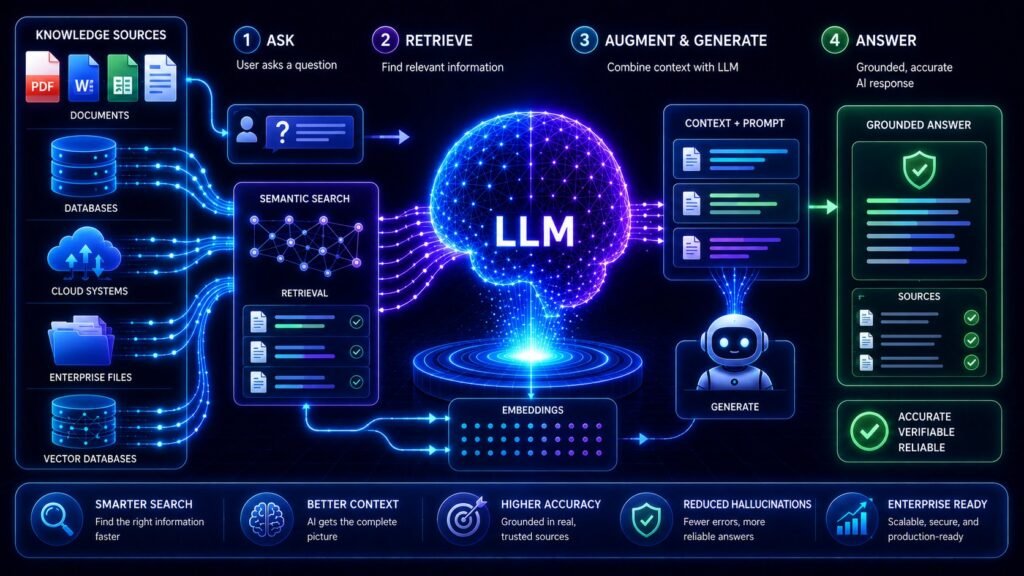
What Is RAG?
RAG stands for:
Retrieval-Augmented Generation
It is an AI architecture where a system retrieves relevant information from external sources before generating a response.
Instead of answering questions only from training memory, the AI first searches trusted knowledge sources such as:
- documents
- PDFs
- websites
- databases
- internal company files
- product manuals
- support documentation
The retrieved information is then added to the AI prompt so the model can generate a more accurate and context-aware response.
Think of RAG as giving AI systems the ability to research before responding.
Why RAG Became Important
Traditional Large Language Models (LLMs) are extremely powerful, but they have several important limitations.
AI Knowledge Becomes Outdated
LLMs are trained on historical datasets. Once training is complete, the model does not automatically know new information unless retrained.
This creates problems in fast-changing industries where information evolves constantly.
For example:
- product policies change
- regulations update
- support documentation evolves
- inventory changes daily
- research papers are continuously published
Traditional models struggle with this dynamic environment.
Hallucinations Reduce Reliability
One of the biggest challenges in modern AI is hallucination.
Sometimes AI systems confidently generate incorrect answers because they predict likely language patterns instead of verifying facts.
This is especially dangerous in industries such as:
- healthcare
- legal services
- finance
- cybersecurity
- enterprise operations
RAG helps reduce hallucinations by grounding answers in retrieved evidence.
Enterprises Need Private Knowledge Access
Most enterprise information is not publicly available online.
Companies store critical knowledge across:
- internal wikis
- PDFs
- cloud storage
- support systems
- operational documentation
- compliance manuals
Traditional LLMs usually cannot access this information.
RAG solves this by connecting AI systems directly to enterprise knowledge sources.
Easy Analogy
Imagine asking two consultants the same difficult business question.
Consultant A
Answers entirely from memory.
Consultant B
First reviews reports, spreadsheets, policies, and manuals before responding.
Consultant B uses a RAG-style workflow.
That second approach is usually more trustworthy because the answer is grounded in actual information instead of relying entirely on memory.
This is the core idea behind Retrieval-Augmented Generation.
How RAG Works
Understanding how Retrieval-Augmented Generation works becomes easier when broken into simple stages.
Step 1: Documents Are Collected
The system gathers knowledge sources such as:
- PDFs
- websites
- support documentation
- enterprise files
- databases
- contracts
- research papers
- product manuals
These files become the AI knowledge base.
This stage is important because retrieval quality depends heavily on source quality.
Step 2: Documents Are Split Into Chunks
Large documents are divided into smaller sections called chunks.
For example:
A 300-page manual may be split into hundreds of smaller searchable segments.
Why?
Because smaller chunks improve retrieval accuracy.
If chunks are too large, retrieval becomes noisy. If chunks are too small, important context may be lost.
Chunking strategy is one of the most important parts of a RAG pipeline.
Step 3: Embeddings Are Created
The chunks are converted into embeddings.
What Are Embeddings?
Embeddings are numerical vector representations of meaning.
Instead of understanding only keywords, embeddings help AI systems understand semantic similarity.
For example:
- “refund policy”
- “return process”
- “cancellation rules”
may all generate related embeddings because they have similar meanings.
This allows semantic search instead of exact keyword matching.
Step 4: Embeddings Are Stored in a Vector Database
The embeddings are stored inside a vector database.
Popular vector database ecosystems include:
- Pinecone
- Weaviate
- Chroma
- Milvus
These systems allow AI applications to retrieve semantically similar information quickly at scale.
Vector databases are one of the most important infrastructure components in modern RAG systems.
Step 5: User Sends a Query
Example:
“What is our enterprise refund policy?”
The system now begins retrieval.
Step 6: Retrieval Happens
The user query is converted into embeddings.
The system searches for the most semantically relevant document chunks inside the vector database.
This is the retrieval stage.
The retriever returns the most relevant information for the AI model.
Step 7: Retrieved Information Is Added to the Prompt
The retrieved content gets inserted into the model prompt.
Instead of relying entirely on training memory, the AI now receives supporting evidence before generating an answer.
This dramatically improves response quality.
Step 8: The LLM Generates the Final Response
The language model generates a grounded answer using:
- retrieved information
- prompt instructions
- language reasoning abilities
This final stage is called generation.
Together, retrieval plus generation create the complete RAG workflow.
Why RAG Is Important for Modern AI
RAG is becoming foundational AI infrastructure because it solves several important enterprise problems at once.
Better Accuracy
RAG systems retrieve real information before generating responses.
This improves factual grounding and makes AI outputs more reliable.
For enterprises, accurate responses are often more important than creative generation.
Reduced Hallucinations
One of the biggest benefits of RAG is hallucination reduction.
Instead of guessing, the AI retrieves supporting information first.
This creates more trustworthy systems.
Access to Updated Information
Traditional LLMs only know what existed during training.
RAG systems can retrieve current information dynamically without retraining the entire model.
This makes RAG ideal for rapidly changing environments.
Enterprise Knowledge Integration
RAG allows AI systems to access:
- internal company documents
- policies
- operational workflows
- technical manuals
- knowledge bases
This significantly improves enterprise AI usefulness.
Better User Trust
Users trust AI systems more when answers are grounded in actual sources.
Some RAG systems even provide citations or document references.
This improves transparency and confidence.
Real-World RAG Use Cases
Customer Support AI
Support assistants retrieve information from:
- FAQs
- help center articles
- product documentation
- return policies
before generating responses.
This improves support quality significantly.
Enterprise Knowledge Search
Employees can search internal company information conversationally instead of manually browsing folders and databases.
This improves productivity and knowledge access.
Legal AI Systems
Legal assistants retrieve:
- contracts
- regulations
- compliance documents
- case references
before generating answers.
This improves research efficiency and reduces risk.
Healthcare AI
Healthcare systems retrieve medical guidelines and treatment documentation before responding to users.
This helps improve reliability in high-risk environments.
Ecommerce AI
RAG systems retrieve live product information, inventory data, and shipping policies dynamically before answering customers.
Research Assistants
Researchers use RAG systems to search papers, reports, and scientific publications conversationally.
This accelerates information discovery.
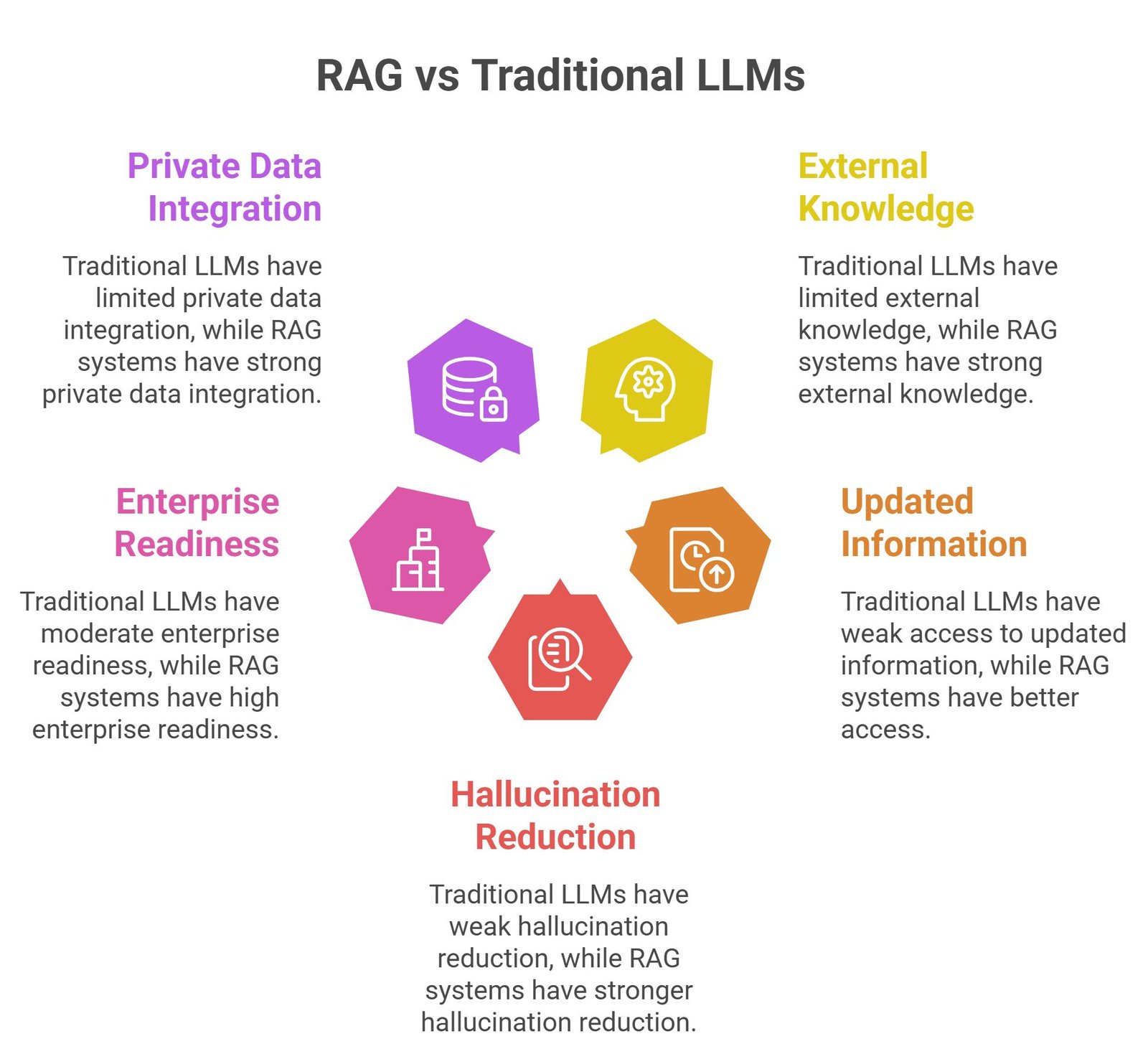
RAG vs Traditional LLMs
| Feature | Traditional LLM | RAG System |
| Uses external knowledge | Limited | Strong |
| Accesses updated information | Weak | Better |
| Hallucination reduction | Weak | Stronger |
| Enterprise readiness | Moderate | High |
| Private data integration | Limited | Strong |
Common Challenges in RAG Systems
While RAG systems are powerful, they still face challenges.
Poor Retrieval Quality
Weak retrieval systems can return irrelevant information, reducing answer quality.
Outdated Knowledge Sources
Old documents create inaccurate outputs.
Infrastructure Complexity
RAG systems require embeddings, vector databases, retrievers, orchestration pipelines, and monitoring systems.
Latency
Retrieval stages add additional processing time.
Permission and Security Risks
Enterprise systems must ensure users only access approved information.
Future of RAG
RAG is evolving rapidly as enterprises demand more reliable AI systems.
Major trends include:
- multimodal RAG
- graph-based retrieval systems
- AI agents with retrieval abilities
- personalized retrieval pipelines
- autonomous enterprise copilots
- real-time enterprise retrieval
Many future enterprise AI systems will likely use retrieval architectures by default.
Suggested Read:
- RAG for Beginners
- What Is RAG in AI
- How RAG Works
- RAG Use Cases
- LLM vs RAG
- How to Reduce LLM Hallucinations
FAQ: RAG Explained Simply
What is RAG in AI?
RAG stands for Retrieval-Augmented Generation, an AI architecture that retrieves external information before generating responses.
Why is RAG important?
RAG improves AI accuracy, reduces hallucinations, and enables access to updated or private information.
How does RAG work?
RAG retrieves relevant information first and then sends that information to an LLM before generating an answer.
What is the difference between RAG and LLMs?
Traditional LLMs rely mostly on training knowledge, while RAG systems retrieve external information dynamically.
What industries use RAG?
Technology, healthcare, legal, finance, ecommerce, and enterprise software industries are major adopters.
Final Takeaway
Understanding RAG explained simply is important because Retrieval-Augmented Generation is becoming one of the most important architectures in modern AI systems.
By combining retrieval systems with language generation, RAG helps AI applications become more accurate, grounded, trustworthy, and enterprise-ready.
That simple idea is transforming how AI assistants, enterprise copilots, customer support systems, and intelligent search platforms operate.